

Byte Cup 2018国际机器学习竞赛夺冠记
描述
9月份,我们两位同学一起组队,参加Byte Cup 2018国际机器学习竞赛。本次比赛由中国人工智能学会和字节跳动主办,IEEE中国代表处联合组织。比赛的任务是文章标题自动生成。最终,我们队伍获得了第一名。
1. 比赛介绍
本次比赛的任务是给定文章文本内容,自动生成标题。本质上和文本摘要任务比较类似。本次比赛有100多万篇文章的训练数据。
1.1 数据介绍
详细参见:https://biendata.com/competition/bytecup2018/data/。
本次竞赛使用的训练集包括了约130万篇文本的信息,验证集1000篇文章,
测试集800篇文章。
1.2 数据处理
文章去重,训练数据中包含一些重复数据,清洗,去重;
清洗非英文文章。
1.3 评价指标
本次比赛将使用Rouge(Recall-Oriented Understudy for Gisting Evaluation)作为模型评估度量。Rough是评估自动文摘以及机器翻译的常见指标。它通过将自动生成的文本与人工生成的文本(即参考文本)进行比较,根据相似度得出分值。

2. 模型介绍
本次比赛主要尝试了seq2seq的方法。参考的模型包括Transformer模型和pointer-generator模型。
模型如下图:
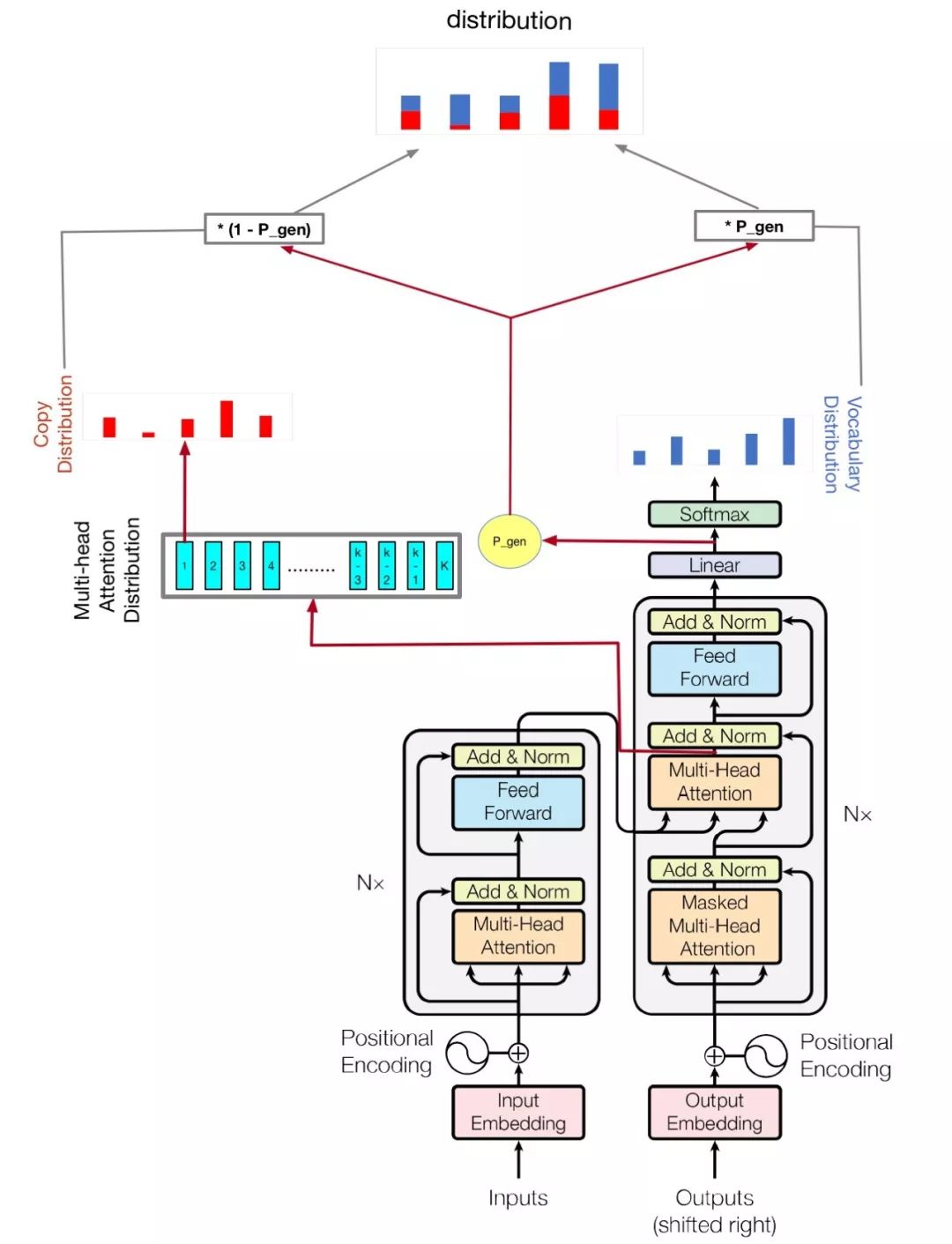
(其实就是将pointer-generator的copy机制加到transformer模型上)。
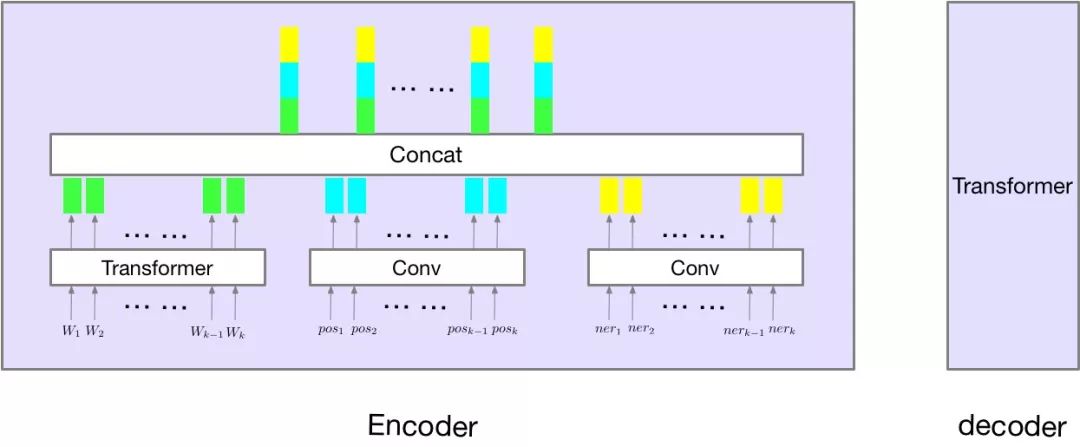
同时,尝试了将ner-tagger和pos-tagger信息加入到模型中,如下图所示:
3. 问题分析
最开始我们尝试了最基本的transformer模型,通过查看数据,遇到以下几类明显错误:
OOV(out of vocabulary);
数字,人名,地名预测错误;
词形预测错误。
OOV问题,主要原因是数据集词表太大,但是,模型能够实际使用的词表较小;数字,人名,地名预测错误,主要原因是低频词embedding学习不充分;词形预测错误,主要原因是模型中没有考虑词的形态问题(当然,如果训练数据足够大,是能避免这个问题的)。
为了解决这些问题,我们尝试了以下方法。
4. 重要组件
4.1 copy机制
对于很多低频词,通过生成式方法生成,其实是很不靠谱的。为此,我们借鉴Pointer-generator的方法,在生成标题的单词的时候,通过Attention的概率分布,从原文中拷贝词。
4.2 subword
为了避免oov问题,我们采用subword的方法,处理文本。这样,可以将词表大小减小到20k,同时,subword会包含一些单词词形结构的信息。
4.3 ner-tagger和pos-tagger信息
因为baseline在数字,人名,地名,词形上预测错误率较高,所以我们考虑能不能将ner-tagger和pos-tagger信息加入到模型中。如上图所示。实验证明通过加入这两个序列信息能够大大加快模型的收敛速度(训练收敛后,指标上基本没差异)。
4.4 Gradient Accumulation
在实验过程中,我们发现transformer模型对batch_size非常敏感。之前,有研究者在机器翻译任务中,通过实验也证明了这一观点。然而,对于文章标题生成任务,因为每个sample的文章长度较长,所以,并不能使用超大batch_size来训练模型,所以,我们用Gradient Accumulation的方法模拟超大batch_size。
4.5 ensemble
采用了两层融合。第一层,对于每一个模型,将训练最后保存的N个模型参数求平均值(在valid集上选择最好的N)。第二层,通过不同随机种子得到的两个模型,一个作为生成候选标题模型(选择不同的beam_width, length_penalty), 一个作为打分模型,将候选标题送到模型打分,选择分数最高的标题。
5. 失败的方法
将copy机制加入到transformer遇到一些问题,我们直接在decoder倒数第二层加了一层Attention层作为copy机制需要的概率分布,训练模型非常不稳定,并且结果比baseline还要差很多;
我们尝试了bert,我们将bert-encoder抽出的feature拼接到我们模型的encoder的最后一层,结果并没有得到提升;
word-embedding的选择,我们使用glove和fasttext等预训练的词向量,模型收敛速度加快,但是,结果并没有random的方法好。
6. 结束语
非常感谢主办方举办本次比赛,通过本次比赛,我们探索,学习到了很多算法方法和调参技巧。
-
2016机器学习行业应用国际峰会:唯「智」者,「造」未来2016-11-08 0
-
立足于上海,放眼于未来——2018上海国际工业自动化及机器人展览会2017-07-06 0
-
CIROS2018第7届中国国际机器人展2017-10-19 0
-
2018深圳国际工业自动化及机器人展览会2017-11-30 0
-
2018年暑假电子设计竞赛,2018-05-12 0
-
2019中国(沈阳)国际机器人展2019-01-07 0
-
竞赛机器人制作技术(电路设计、编程方法、算法解析)2019-12-25 0
-
2018年数据科学和机器学习工具调查2018-06-07 4235
-
区块链的饕餮盛宴 2018 NULS 杯国际区块链创新应用DAPP设计大赛进行时2018-08-01 997
-
哈工大斩获第21届“国际水下机器人大赛”冠军2018-08-08 5454
-
AI新闻:2018年机器学习国际会议2018-11-12 1778
-
第二届TE Connectivity AI CUP竞赛圆满落幕2020-12-15 1740
-
聊天机器人在教育行业有什么优势2021-03-31 689
-
2018年电子竞赛题目汇总资料下载2021-07-22 766
-
AMD赞助多支FIRST机器人竞赛团队2024-09-18 404
全部0条评论

快来发表一下你的评论吧 !
