

迄今最大模型?OpenAI发布参数量高达15亿的通用语言模型GPT-2
电子说
描述
几个月前谷歌推出的语言模型BERT引发了业内的广泛关注,其 3 亿参数量刷新 11 项纪录的成绩让人不禁赞叹。昨天,OpenAI 推出了一种更为强大的算法,这一次模型达到了 15 亿参数。
代码地址:https://github.com/openai/gpt-2
这种机器学习算法不仅在很多任务上达到了业内最佳水平,还可以根据一小段话自动「脑补」出大段连贯的文本,如有需要,人们可以通过一些调整让计算机模拟不同的写作风格。看起来可以用来自动生成「假新闻」。对此,OpenAI 甚至表示:「出于对模型可能遭恶意应用的担忧,我们本次并没有发布所有预训练权重。」
如此强大的模型却不公开所有代码?Kyunghyun Cho 并不满意:「要是这样,为了人类我不得不删除迄今为止自己公开的所有模型权重了。」Yann LeCun 表示赞同。
OpenAI 训练了一个大型无监督语言模型,能够生产连贯的文本段落,在许多语言建模基准上取得了 SOTA 表现。而且该模型在没有任务特定训练的情况下,能够做到初步的阅读理解、机器翻译、问答和自动摘要。
该模型名为 GPT-2(GPT二代)。训练 GPT-2 是为了预测 40GB 互联网文本中的下一个单词。考虑到可能存在的对该技术的恶意使用,OpenAI 没有发布训练模型,而是发布了一个较小模型供研究、实验使用,同时 OpenAI 也公布了相关技术论文(见文后)。
GPT-2 是基于 transformer 的大型语言模型,包含 15 亿参数、在一个 800 万网页数据集上训练而成。训练 GPT-2 有一个简单的目标:给定一个文本中前面的所有单词,预测下一个单词。数据集的多样性使得这一简单目标包含不同领域不同任务的自然事件演示。GPT-2 是对 GPT 模型的直接扩展,在超出 10 倍的数据量上进行训练,参数量也多出了 10 倍。
15 亿的参数量已经是非常非常多了,例如我们认为庞大的 BERT 也就 3.3 亿的参数量,我们认为视觉中参数量巨大的 VGG-19 也不过 1.44 亿参数量(VGG-16 为 1.38 亿),而 1001 层的 ResNet 不过 0.102 亿的参数量。所以根据小编的有偏估计,除了 bug 级的大规模集成模型以外,说不定 GPT-2 就是当前最大的模型~
GPT-2 展示了一系列普适而强大的能力,包括生成当前最佳质量的条件合成文本,其中我们可以将输入馈送到模型并生成非常长的连贯文本。此外,GPT-2 优于在特定领域(如维基百科、新闻或书籍)上训练的其它语言模型,而且还不需要使用这些特定领域的训练数据。在知识问答、阅读理解、自动摘要和翻译等任务上,GPT-2 可以从原始文本开始学习,无需特定任务的训练数据。虽然目前这些下游任务还远不能达到当前最优水平,但 GPT-2 表明如果有足够的(未标注)数据和计算力,各种下游任务都可以从无监督技术中获益。
Zero-shot
GPT-2 在多个领域特定的语言建模任务上实现了当前最佳性能。该模型没有在这些任务的特定数据上进行训练,只是最终测试时在这些数据上进行了评估。这被称为「zero-shot」设置。在这些数据集上进行评估时,GPT-2 的表现要优于那些在领域特定数据集(如维基百科、新闻、书籍)上训练的模型。下图展示了在 zero-shot 设定下 GPT-2 的所有当前最佳结果。
(+)表示该领域得分越高越好,(-)表示得分越低越好。
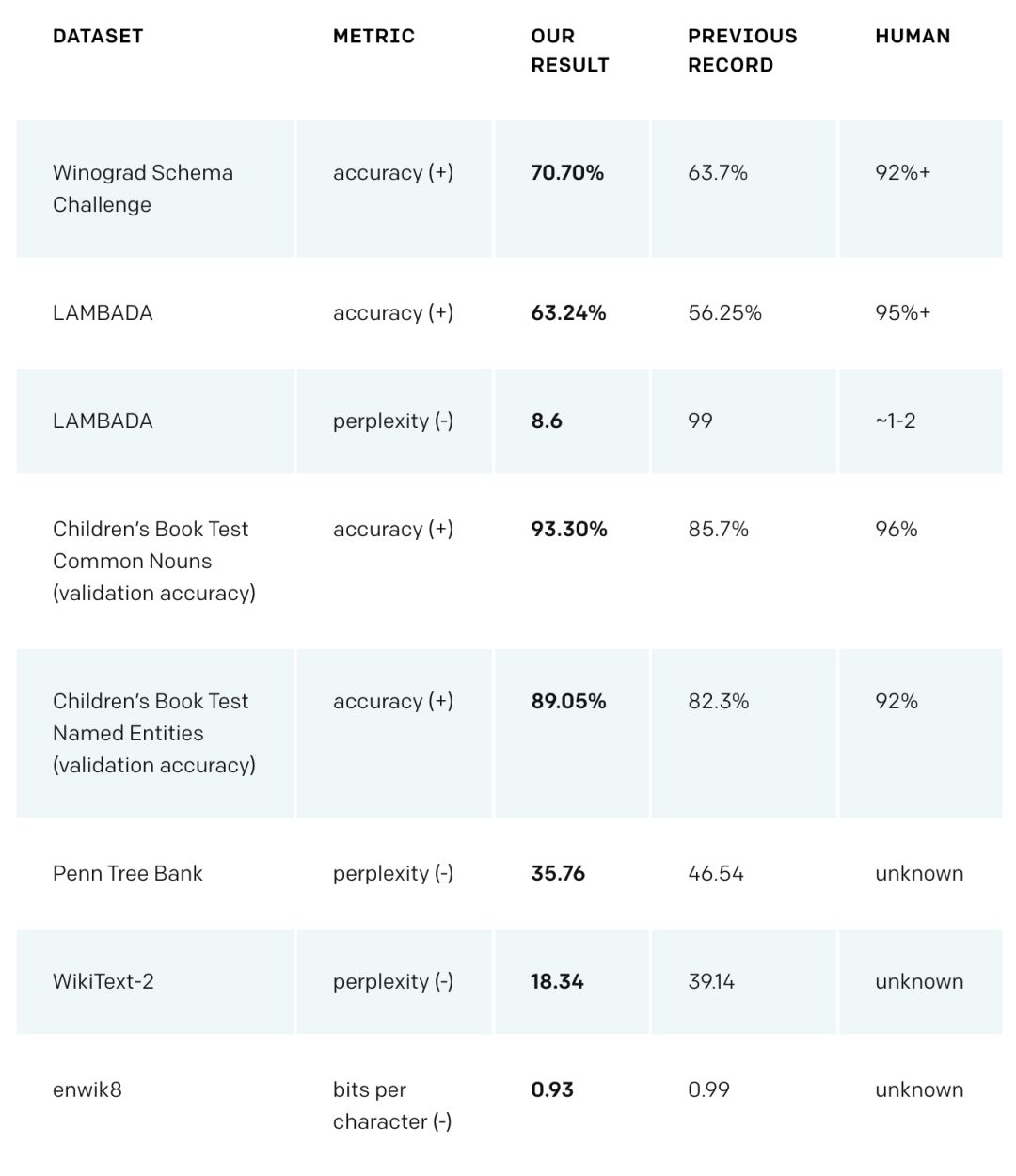

GPT-2 在 Winograd Schema、LAMBADA 和其他语言建模任务中达到了当前最佳性能。
在问答、阅读理解、自动摘要、翻译等其他语言任务中,无需对 GPT-2 模型做任何微调,只需以正确的方式增强模型,就能取得令人惊艳的结果,虽然其结果仍逊于专门系统。
OpenAI 假设,既然这些任务是通用语言建模的子集,那么增加计算量和数据就能获得进一步的性能提升。《Learning and Evaluating General Linguistic Intelligence》等其他研究也有类似假设。OpenAI 还预期微调能够对下游任务的性能提升有所帮助,尽管还没有全面的实验能证明这一点。
策略建议
大型通用语言模型可能产生巨大的社会影响以及一些近期应用。OpenAI 预期 GPT-2 这样的系统可用于创建:
AI 写作助手
更强大的对话机器人
无监督语言翻译
更好的语音识别系统
此外,OpenAI 还设想了此类模型有可能用于恶意目的,比如:
生成误导性新闻
网上假扮他人
自动生产恶意或伪造内容,并发表在社交媒体上
自动生产垃圾/钓鱼邮件
这些研究成果与合成图像和音视频方面的早期研究结果表明,技术正在降低生产伪造内容、进行虚假信息活动的成本。公众将需要对在线文本内容具备更强的批判性,就像「deep fakes」导致人们对图像持怀疑态度一样。
今天,恶意活动参与者(其中一些是政治性的)已经开始瞄准共享网络社区,他们使用「机器人工具、伪造账号和专门团队等,对个人施加恶意评论或诽谤,致使大众不敢发言,或很难被别人倾听或信任」。OpenAI 认为,我们应该意识到,合成图像、视频、音频和文本生成等方面研究的结合有可能进一步解锁这些恶意参与者的能力,使之达到前所未有的高度,因此研究者应当寻求创建更好的技术和非技术应对措施。此外,这些系统的底层技术创新是基础人工智能研究的核心,因此控制这些领域的研究必将拖慢 AI 领域的整体发展。
因此,OpenAI 对这一新研究成果的发布策略是:「仅发布 GPT-2 的较小版本和示例代码,不发布数据集、训练代码和 GPT-2 模型权重」。
论文:Large Language Models are Unsupervised Multitask Learners

论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
摘要:问答、机器翻译、阅读理解、自动摘要这样的自然语言处理任务的典型方法是在任务特定数据集上进行监督式学习。我们证明,在包含数百万网页的全新数据集 WebText 上训练时,语言模型开始在没有任何明确监督的情况下学习这些任务。计算条件概率并生成条件样本是语言模型在大量任务上取得良好结果(且无需精调)所必需的能力。当以文档+问题为条件时,在没有使用 127000 多个训练样本中任何一个样本的情况下,语言模型生成的答案在 CoQA 数据集上达到 55F1,媲美于或者超越了 4 个基线系统中的 3 个。语言模型的容量对 zero-shot 任务的成功迁移非常重要,且增加模型的容量能够以对数线性的方式在多任务中改进模型性能。我们最大的模型 GPT-2 是一个包含 15 亿参数的 Transformer,在 zero-shot 设定下,该模型在 8 个测试语言建模数据集中的 7 个数据集上取得了 SOTA 结果,但仍旧欠拟合 WebText 数据集。来自该模型的样本反映了这些改进且包含连贯的文本段落。这些发现展示了一种构建语言处理系统的潜在方式,即根据自然发生的演示学习执行任务。
-
OpenAI发布2款开源模型2025-08-06 878
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 768
-
ChatGPT重磅更新 OpenAI发布GPT-4 Turbo模型价格大降2/32023-11-07 3458
-
OpenAI已为GPT-5申请商标,GPT-5要来了?2023-08-02 1283
-
如何计算transformer模型的参数量2023-07-10 14582
-
ChatGPT升级 OpenAI史上最强大模型GPT-4发布2023-03-15 3363
-
基于OpenAI的GPT-2的语言模型ProtGPT2可生成新的蛋白质序列2022-09-08 3206
-
使用NVIDIA TensorRT优化T5和GPT-22022-03-31 4581
-
谷歌开发出超过一万亿参数的语言模型,秒杀GPT-32021-01-27 2794
-
谷歌推出1.6万亿参数的人工智能语言模型,打破GPT-3记录2021-01-18 2715
-
最大人工智能算法模型GPT-3问世2020-07-08 2537
-
布朗大学90后研究生:我们复现了15亿参数GPT-2模型,你也行!2019-09-01 3753
-
OpenAI发布一款令人印象深刻的语言模型GPT-22019-05-17 5032
-
OpenAI发布了一个“逆天”的AI模型——GPT2整个模型包含15亿个参数2019-03-07 9223
全部0条评论

快来发表一下你的评论吧 !
