

关于NLP基准数据集的快速概览,以及最新技术的进展
电子说
描述
本文是一个自然语言处理资源索引,涵盖了目前NLP领域常用任务的最佳实验 结果和数据集资源,可以作为进一步从事NLP研究的基础。读者也可以自行在Github页面上添加新的结果,本文中大部分为英文NLP资源,还有少数汉语、印地语和越南语资源。
本文实际上是一个索引,旨在记录自然语言处理(NLP)领域的新进展,并概述最常见的NLP任务及其相应数据集的新技术。
这篇索引旨在涵盖主要的传统和核心NLP任务,如语义依赖性解析和词性标注等,以及最近不断取得新突破的任务,比如阅读理解和自然语言推理。本文主要目标是为感兴趣的读者提供关于NLP基准数据集的快速概览,以及最新技术的进展,这些数据集和新进展可以作为进一步NLP研究的基础。
因此,本文有意将这些NLP领域的新研究进展做一个简单汇总,便于研究人员集中查阅参考。
读者也可以通过浏览器访问nlpprogress.com 或nlpsota.com来阅读本文。
简易使用指南
实验结果
本文首选在已发表的论文中的实验结果,但对少数影响力很大的预印本论文也可能入选。
数据集
本文中收录的数据集,除了利用该数据集的论文之外,还应经过至少一篇已发表的其他论文的评估。
代码
我们建议添加指向实现的链接(如果可用)。如果代码不存在,您可以向表中添加代码列(见下文)。在Code列,建议使用官方实现。如果有非官方实现,请使用链接(见下文)。如果没有可用的实现,可以将单元格留空。
向本索引中添加新结果
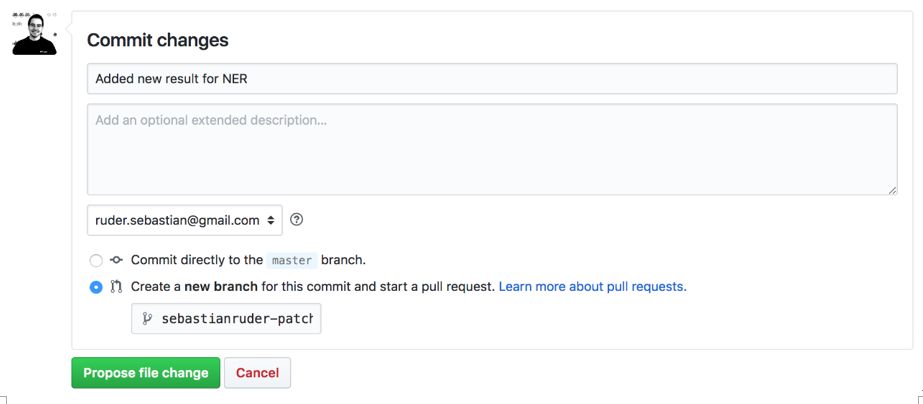
如果要添加新结果,只需单击文件右上角的小编辑按钮以执行相应任务(如下图所示)。

读者可以在Markdown中编辑文件。只需以相同的格式将一行添加到相应的表中即可。确保表格中数据排序正确(将最佳结果位于顶部)。完成更改后,单击页面顶部的“预览更改”选项卡,确保表格看起来还不错。如果一切看起来都OK,请转到页面底部确认更改。
此处需要为建议更改添加名称,可以选择添加说明文字,可以选择“创建新分支并启动拉取请求”,然后单击“提交更改”。
具体索引内容和研究领域如下,绝大部分为英语,有少量资源为汉语、印地语和越南语。
英语
自动语音识别
CCG超级标准
常识
选区解析
共同决议
依赖解析
对话
域适应
实体链接
语法纠错
信息提取
语言建模
词汇规范化
机器翻译
多任务学习
多模态
命名实体识别
自然语言推理
词性标注
问答
关系预测
关系提取
语义文本相似度
语义解析
语义角色标记
情绪分析
浅语法
简单化
状态检测
概要
分类学习
时间处理
文字分类
词义消歧
中文
实体链接
中文词汇分割
印地语
分块
词性标注
机器翻译
越南语
依赖解析
机器翻译
命名实体识别
词性标注
分词
最后以”中文-词汇分割”子类目为例,简单说明这个索引资源的呈现方式。
点击相应链接进入,首先是中文词汇分割这个任务的简要介绍。

下面列出了不同作者建立的基于不同搜索方式的单词分割模型,以及相应模型的发表时间。

接下来是评估指标,此类中为F1分数。下面以表格形式给出每种模型在不同数据集上获得的最佳F1分数。每个分数对应的研究论文链接和部分Github资源地址。

可以看到,表中中文词汇分割模型的最优F1分数均超过了96分,感兴趣的读者可以点击查看论文或Github资源。
-
新技术在生物样本冷冻中的应用案例分析2023-12-26 3835
-
【免费名额30个】手把手教你快速学习和应用人工智能技术2018-09-12 4649
-
NLPIR智能技术推动NLP语义挖掘快速发展2019-03-14 1707
-
5G承载网络需求与新技术进展2021-02-03 2936
-
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍2018-06-10 78606
-
NLP-Progress库NLP的最新数据集、论文和代码2018-11-17 2984
-
新华三在存储领域的最新技术及应用进展浅析2018-12-13 1103
-
首届中文NL2SQL挑战赛启动,NLP打破数据库壁垒2019-06-12 868
-
新技术进展经常带来伦理和文化的问题2019-11-08 3690
-
Cadence公司发布了关于即将发布的DDR5市场版本以及技术的进展2020-06-08 6145
-
NLP 2019 Highlights 给NLP从业者的一个参考2020-09-25 2324
-
整理了一波关于医疗NLP的数据集2020-10-10 9260
-
微软团队发布生物医学领域NLP基准2020-10-22 2823
-
NLP中文自然语言处理数据集、平台和工具整理2020-11-05 3595
-
关于数据转换器的基准电压选择和设计提示2024-09-20 426
全部0条评论

快来发表一下你的评论吧 !
