

探析自动驾驶规划控制发展现状及热点研究
电子说
描述
对自动驾驶而言,传感器、感知、地图定位和规划控制是目前研究的热点,本文奇点汽车美研中心首席科学家兼总裁黄浴博士从多个方面综述了目前自动驾驶的技术水平以及不同板块的重要性。
传感器技术
传感器而言,大家比较关心新技术。
在摄像头技术方面,HDR,夜视镜头,热敏摄像头等是比较热的研究。前段时间有研究(MIT MediaLab教授)采用新技术穿透雾气的镜头,叫做single photon avalanche diode (SPAD) camera;另外,能不能采用计算摄像技术(computational photography)改进一下如何避免雨雪干扰,采用超分辨率(SR)图像技术也可以看的更远。前不久,图森的摄像头可以看1000米远吗,要么采用高清摄像头4K甚至8K,要么采用SR技术实现。
这是介绍SPAD的两个截图:
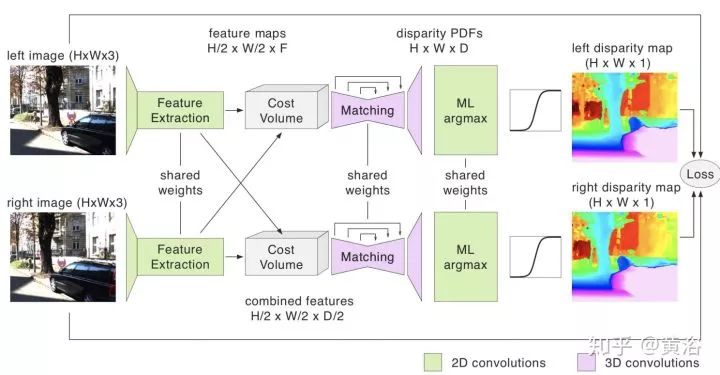
另外,单目系统比较流行,现在也有双目系统存在,比如安霸从意大利帕尔马大学买到的VisLab自动驾驶技术,还有Bertha Benz著名的Stixel障碍物检测算法。因为基线原因,车上可以配备多个双目系统,以方便测量不同距离的障碍物。懂计算机视觉的同学知道,立体匹配和基线宽度在涉及视觉系统的时候有一个权衡。深度学习已经用来估计深度/视差图,就如分割一样,pixel-to-pixel。甚至单目也可以推理深度,结果当然比双目差。
激光雷达最热,一是降低成本和车规门槛的固态激光雷达,二是如何提高测量距离,三是提高分辨率和刷新频率,还有避免互相干扰和入侵的激光编码技术等。其实激光雷达的反射灰度图也是一个指标,3-D点云加上反射图会更好,比如用于车道线检测。
另外,摄像头和激光雷达在硬件层的融合也是热点,毕竟一个点云的点是距离信息,加上摄像头的RGB信息,就是完美了不是?一些做仿真模拟以及VR产品的公司就是这么做的,去除不需要的物体和背景就能生成一个虚拟的仿真环境。
这里是一家美国激光雷达创业公司AEye的技术iDAR截图,iDAR 是 Intelligent Detection and Ranging,最近该公司宣称已经能够实现测距1000米(一两年前谷歌就说,它的激光雷达能看到3个足球场那么远):
毫米波雷达方面,现在也在想办法提高角分辨率。毕竟它是唯一的全天候传感器了,如果能够解决分辨率这一痛处,那么以后就不会仅仅在屏幕上展示一群目标点,而是有轮廓的目标,加上垂直方向的扫描,完全可以成为激光雷达的竞争对手。希望新的天线和信号处理技术可以解决雷达成像的难点,包括功耗。
这里是NXP提供的新型高分辨率雷达和激光雷达比较的截图:
超声波雷达,基本是用在泊车场景,便宜。
感知模块
下面谈感知模块。
感知是基于传感器数据的,以前反复提过了,传感器融合是标配,信息越多越好吗,关键在于怎么融合最优。比如某个传感器失效怎么办?某个传感器数据质量变差(某个时候,比如隧道,比如天气,比如夜晚,比如高温低温等等造成的)怎么办?如果你要用数据训练一个感知融合模型,那么训练数据是否能够包括这些情况呢?
这里当然谈到深度学习了,而且深度学习也不仅仅用在图像数据,激光雷达点云数据也用,效果也非常好,明显胜过传统方法。不过,深度学习有弱点,毕竟还是靠大量数据“喂”出来的模型,有时候很敏感,比如像素上改变一点儿对人眼没什么而机器识别就造成错误,还有当识别类别增多性能会下降,同时出现一些奇怪的误判,比如谷歌曾经把黑人识别成猩猩。机器学习一个问题是泛化问题(generalization),如何避免overfitting是一个模型训练的普遍问题,当然大家都提出了不少解决方法,比如data augmentation,drop out等。
深度学习发展还是很快的,好的模型不断涌现,如ResNet, DenseNet;好的训练方法也是,比如BN成了标配,采用NAS基础上的AutoML基本上可以不用调参了(GPU设备很贵呀);具体应用上也是进步很大,比如faster RCNN,YOLO3等等。
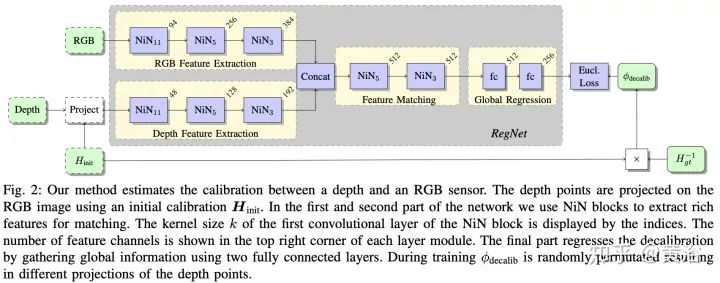
在激光雷达数据上,最近深度学习应用发展很快,毕竟新吗,而且这种传感器会逐渐普及,成本也会降下来,毕竟是3-D的,比2-D图像还是好。这里要提到sync和calibration问题,要做好激光雷达和摄像头数据的同步也不容易,二者的坐标系校准也是,去年有个CNN模型叫RegNet,就是深度学习做二者calibration的。
谈到融合,这里包括几个意思,一是数据层的直接融合,前面提到硬件层可以直接完成,软件也可以,而且还可以解决硬件做不了的问题:激光雷达毕竟稀疏,越远越稀疏,有时候还会有“黑洞”,就是不反射的物质,比如车窗玻璃;而图像可以致密,分辨率也可以很高,毕竟造价便宜,二者在深度图(depth map)空间结合是一个互补,深度学习可以帮上忙,有兴趣的可以看看MIT的论文。
除了数据层,还有中间模型层融合,以及最后任务层(一般指多个模型结果输出)的融合,目前深度学习用在激光雷达数据以及结合图像数据融合的目标检测识别分割跟踪等方面有不少论文,基本可以在这三个层次划分。
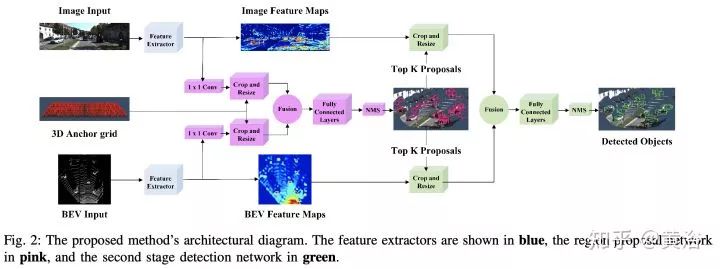
很有趣的现象是,激光雷达点云投射到平面上变成图像数据是一个很讨巧的方法,而且鸟瞰平面比前视平面(摄像机方向)效果好,当然也有直接在3-D数据上做的,比如VoxelNet,PointNet。很多工作都是将图像领域成功的模型用在激光雷达数据上,做些调整和推广,比如faster RCNN,其中RPN和RCNN部分可以通过不同传感器数据训练。
这里是一个激光雷达+摄像头融合做目标检测的论文截图:
谈到深度学习在图像/视频/深度图/3-D点云上的应用,不局限在检测识别分割上,这个以后再谈吧,又要写一篇才行。
感知的任务是理解自动驾驶车的周围环境,除了定位跟地图有关,像障碍物检测,运动目标跟踪,红绿灯识别,道路标志识别,车道线检测(根据需要而定,比如有些地图直接用路标或者特征匹配实现定位,车道线就是由地图给出)都是感知的任务。更高级的任务会涉及对周围其他物体的行为预测,比如行人,尤其是路口行人过马路的预测,比如行驶车辆,到底是打算cut-in还是仅仅偏离了车道,在高速入口的车辆,到底是想加速先过还是减速等你,这些都是“老司机”很擅长的,而提供线索的恰恰是感知模块。
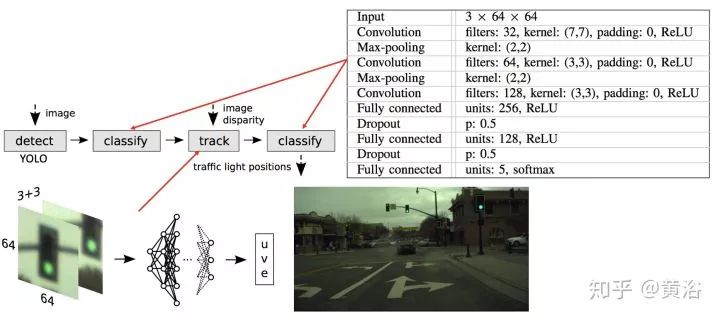
这里是一个做红绿灯检测识别的NN模型例子:
而一个检测路牌的NN模型:
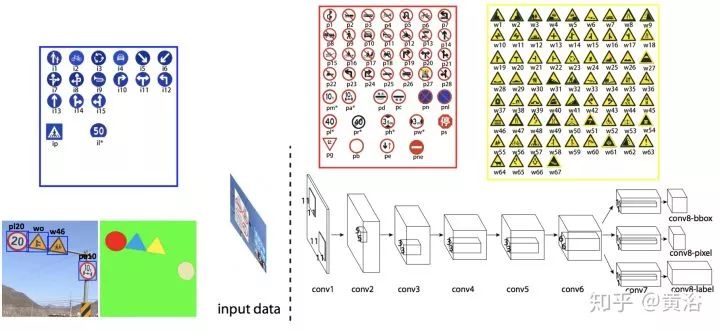
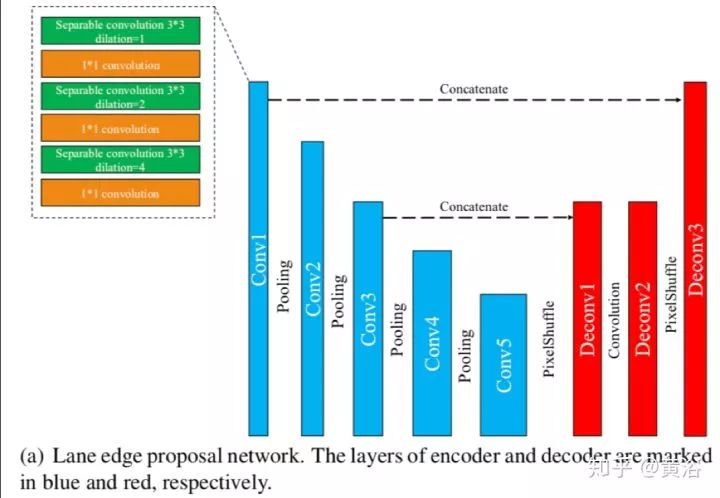
这是一个车道线检测的NN模型LaneNet示意图:车道线proposal network和车道线localization network。
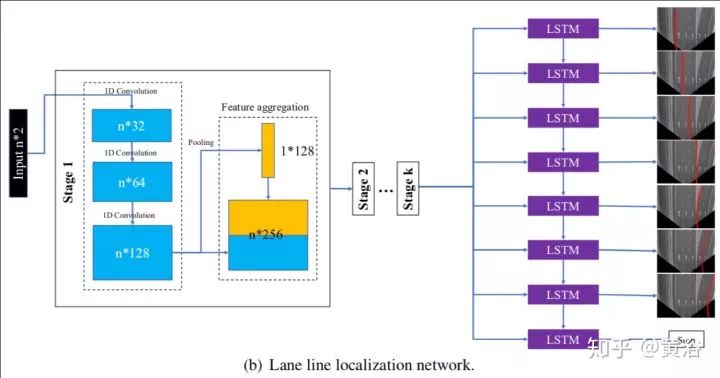
这个NN模型就是对行人预测的:
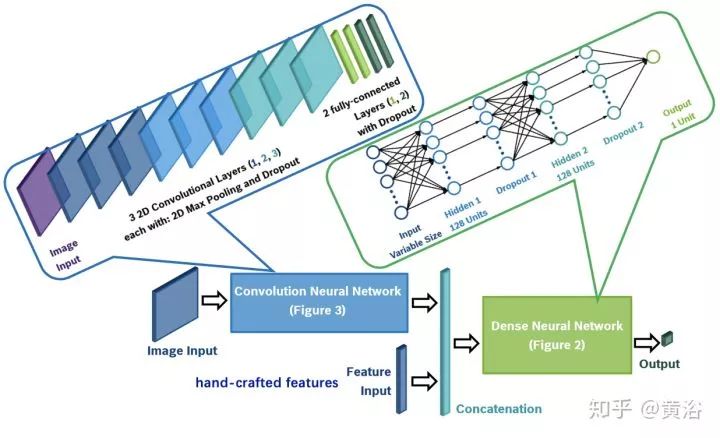
应用场景可以看下面的示意图:激光雷达点云作为输入
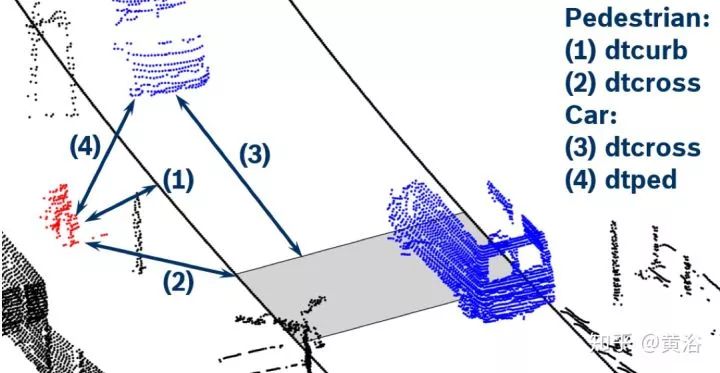
顺便说一下,我对一些大讲“感知已经OK,现在最重要的是规划决策”的言论难以苟同,毕竟感知在这些行为细节上缺乏充分的数据提供给预测和规划部分,所以也很难有更细腻的规划决策模型来用。当然采用大数据训练的规划决策模型可以包括这些,但仅仅凭轨迹/速度/加速度这些输入信息够吗?大家也可以注意到一些startup公司已经在展示人体运动跟踪,头部姿态,路上人工驾驶车辆的驾驶员视线方向 (gaze detection) 和面部表情/手势识别的结果,说明大家已经意识到这些信息的重要性。
这里展示最近一些基于深度学习的人体姿态研究论文截图:
另外,感知模型基本上是概率决策,是软的推理(soft inference),最后是最小化误差的硬决定(hard decision),所以误差是难免的。现在一些安全标准,比如ASIL,ISO26262, NHTSA,要求做到功能安全,还有最近的SOTIF,要求考虑unknown safe/unsafe,这些对感知在自动驾驶的作用是提出了更严格的标准。说白了就是,以前给出判断就行,现在必须给出判断的可靠性以及不自信的警告(confidence score)。有时候融合就要考虑这个问题,最好给出多个模型输出,当一个模型可靠性不高的时候,就要采用其他可靠性高的模型输出,当所有模型都不可靠,自然就是准备进入安全模式了。对突发性事故的适应性有多强,就考验安全模型了。
以前提到过L2-L3-L4演进式开发自动驾驶模式和L4这种终极自动驾驶开发模式的不同,提醒大家可以注意一个地方:特斯拉的演进模式在用户自己人工驾驶的时候仍然运行自动驾驶程序,称之为“影子”模式,当用户的驾驶动作和自动驾驶系统的判断出现矛盾的时候,相关上传的数据会引起重视,以帮助提升自动驾驶系统性能,比如一个立交桥出现,自动驾驶系统误认为是障碍物,而驾驶员毫无犹豫的冲过去,显然这种传感器数据会重新被标注用来训练更新模型,甚至引导工程师采集更多相关数据进行训练;另外,当驾驶员突然刹车或者避让,而自动驾驶系统认为道路无障的情况,收集数据的服务器一端也会将这种数据重新标注。
这种影子模式就是演进式开发模式系统升级的法宝,同时大量驾驶数据的收集也可以帮助规划决策的提升,这个下面再讲。相比之下,谷歌模式在安全员操控车辆时候,自然也在收集数据,当运行自动驾驶出现报警或者安全员觉得危险需要接管的时候,这种数据也会像影子模式一样需要注意。两种开发模式都会及时获取特别数据方法,唯一不同的是前者是付钱的(买车),而后者是要钱的(工资)。
地图与定位
再谈地图和定位。
我们知道自动驾驶在L2是不需要地图的,特别高清地图(HD Map),带有车道线信息,L2级别用不上,现在有一种“降维打击”模式,采用L4技术去开发L3甚至L2,主要是地图定位可以提供很多辅助信息,简化一些感知负担,比如车道线,路牌和红绿灯位置。
一般我们看到的地图,俗称导航地图,基于GPS进行车定位和道路规划。现在又出现了一种ADAS地图(四维图新就提供这种服务),其实就是在导航地图上附加一些信息,比如道路曲率和坡度,可以有助于车辆控制的时候调整参数,如ACC,LKS。
我们一般谈到定位,可以是GPS/IMU,也可以是高清地图。前者有误差,要么采用差分GPS,如RTK(国内的千寻网络就是提供这样的服务),要么和其他方式融合,比如激光雷达的点云匹配,摄像头的特征匹配,也包括基于车道线和路牌的识别定位。
谈到高清地图,以前提到过两种模式,一是谷歌的高成本方式,采用高价的数据采集车,获取环境的激光雷达点云以及反射灰度图,滤除不需要的物体(行人/车辆/临时障碍物),提取车道线/红绿灯/路牌(停止/让路符号,街道距离信息)/车道标志(箭头/限速/斑马线)等等,另外也标注了道路的其他信息如曲率,坡度,高程,侧倾等等。
这是一个谷歌HD Map的截图:
由于激光雷达点云数据大,大家就考虑压缩的方法,比如TomTom的RoadDNA,国内高德地图的道路指纹匹配,美国startup地图公司CivilMaps也有类似地图指纹技术,不过前者是在视觉层,而后者是在点云层。有些公司是不提供点云层,因为数据太大,相反视觉层和语义层可以给,基本矢量图就能描述,数据量小多了,但匹配难度大。地图的绘制,存储和访问是相当复杂的工程,所以投入很大,尤其是底图(base map)的绘制。
这是TomTom的RoadDNA定位的介绍截图:
高清地图的第二种方式就是Mobileye和Tesla采用的,一般低成本,期望通过众包实现。不用激光雷达,采用摄像头获取道路标识,Mobileye称之是REM(Road Experience Management),也是“路书”(Roadbook)。REM提取的信息有道路边缘线、车道中心线、车道边缘线以及静态物体的标示。
截图来自Mobileye的REM介绍:
Bosch基于此,还提出一种基于毫米波雷达的方法提取道路其他信息,比如隔离栏、电线杆和桥梁等等,称为Bosch Road Signature(BRS)。追随这种众包方法的公司也不少,如特斯拉出来的人成立的公司Lvl5,国内有几家,如宽凳科技,MOMENTA,深动科技,最近地平线也给出一个NavNet平台,支持这种众包的低成本制图方式。
这是Lvl5作图的一个示意图:像VO的例子吧。
其实“实时更新”是高清地图提供服务的关键,而对这个服务的成本考虑当然是第二种方式容易推广。众包的缺点是容易数据碎片化,同时摄像头的制图难度也远大于激光雷达方法,视觉SLAM是比较有挑战性的,当然如果限制一下做车道线和路牌为主的目标取地图特征,难度可以降低。
美国地图公司HERE采用的更新方法也是通过众包,只是它先建了底图。所以,一些提出众包建图的公司都想先拥有底图。Mobileye就和HERE合作,最近它在日本已经完成了REM的高速公路建图。
这张图是在今年CES介绍REM的一页PPT:
定位是基于地图的,融合方式是包括GPS/IMU/HD Map,比如隧道就没有GPS信号,甚至高楼大厦密集的地方也不会有稳定的GPS信号,如果网络不好造成地图下载不利,基本就是靠IMU和L2的车道线/路牌识别了(激光雷达的反射灰度图可以做车道线识别,但是传感器性能有时候限制它的工作距离,不如摄像头灵活),这时候“降维打击”的方法都失效了,回归原始,就靠现场感知了,真正的“老司机”做派:)。
值得一提的是,MIT教授就有在研究如何不用地图做自动驾驶。
规划控制
下面该是规划控制(包含预测和决策)。
规划分三个层面,路径规划(任务规划),行为规划和运动规划。最后一个运动规划,和后面的控制模块捆在一起,基本上L2-L4都通用了,除非软硬件联合开发,L2和L4用的运动规划(经典的有RRT,Lattice planner)及控制(PID,MPC之类)没啥变化。路径规划,就是基于道路网络确定地图上A点到B点的路径,这个以前导航地图也是要做这个任务。那么,剩下一个最新的问题就是行为规划了。
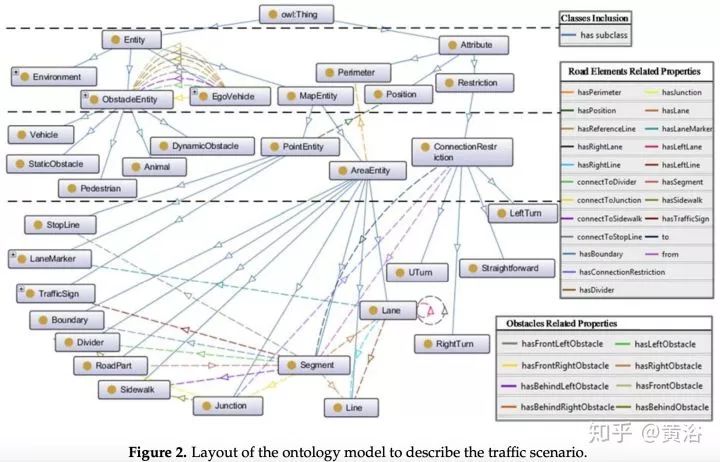
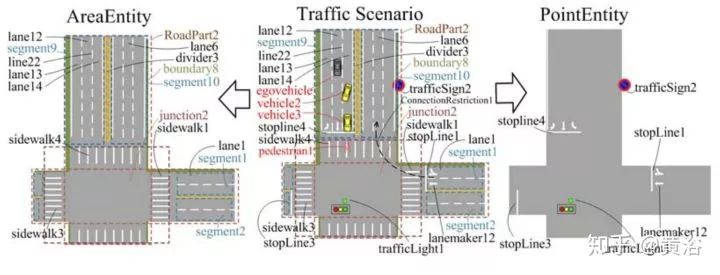
行为规划需要定义一个行为类型集,类似多媒体领域采用的ontology,领域知识的描述。而行为规划的过程,变成了一个有限状态机的决策过程,需要各种约束求解最优解。这里对周围运动障碍物(车辆/行人)的行为也有一个动机理解和轨迹预测的任务。上面谈到的,感知模块对周围车辆行人的行为理解,就会在这里扮演一个重要的角色。
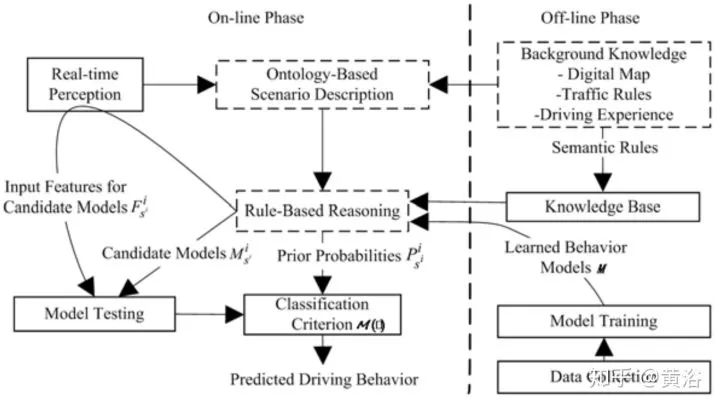
深度学习在这里有价值了。行为模型的学习过程需要大量的驾驶数据,包括感知和定位的输出,路径规划和车辆的运动状态作为输入,最终的车辆行驶的控制信号(方向盘,油门,刹车)作为输出,那么这就是一个E2E的行为规划+运动规划+控制的模型;如果把车辆轨迹作为输出,那么这个E2E就不包括控制。
如果把传感器/GPS/IMU/HD Map和路径规划作为输入,那么这个E2E就是前端加上感知的模型,这就变成特斯拉想做的software 2.0,不过感知太复杂了,不好办。还是觉得把感知和定位的输出作为输入吧,这样放心:)。
这里不得不提到自动驾驶的仿真模拟系统,按我看,这种规划控制的行为模型学习,最适合在模拟仿真环境做测试。Waymo在Carcraft仿真系统中测试左拐弯行为时候,会加上各种变化来测试性能,称子为“fuzzing"。
这里给大家推荐两篇重要论文做参考:
1 “A Scenario-Adaptive Driving Behavior Prediction Approach to Urban Autonomous Driving”
2 “ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst”
第一篇是中科大的论文,个人认为非常适合大家了解百度刚刚发布的Apollo 3.5的行为规划模型。这篇文章我一年前就读了,不是深度学习的方法。这里贴几个截图:
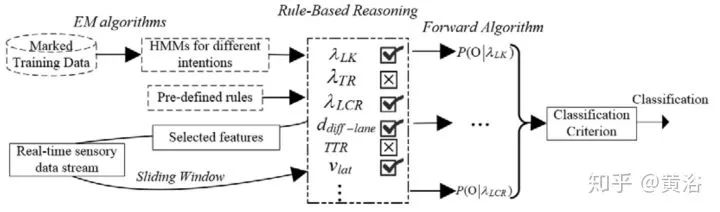
第二篇论文是Waymo最近发的research工作,是深度学习方法,完全依赖其强大的感知模块输入,还有1000万英里的驾驶数据,强烈推荐。附上几个截图:
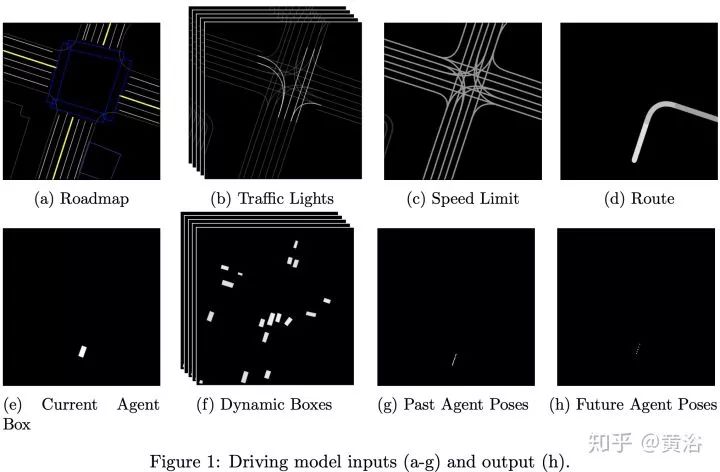
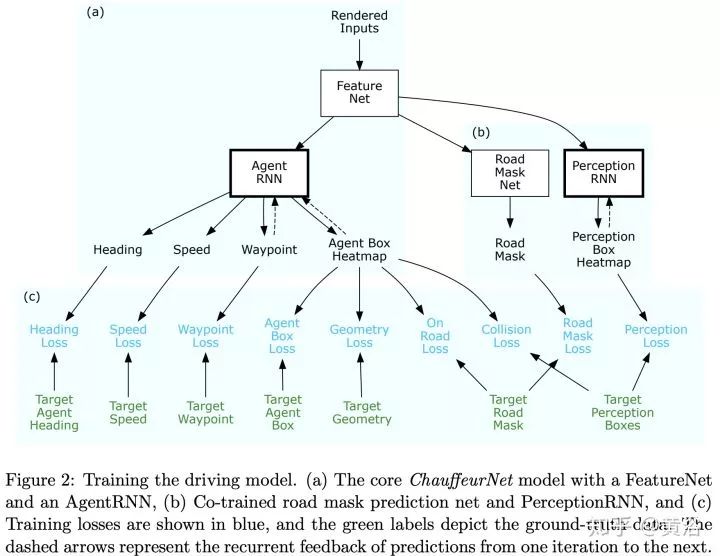
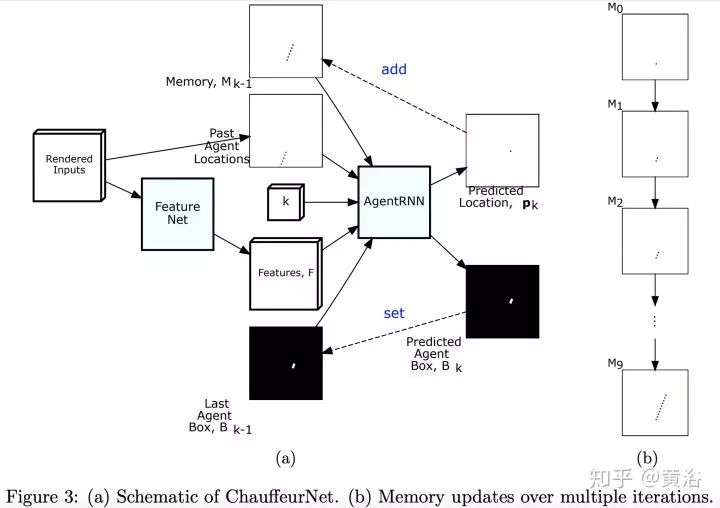

仿真模拟平台
顺便介绍一下,仿真模拟平台的发展。
DARPA当年比赛的时候前几名都做了模拟系统,谷歌收购斯坦福团队以后就先把模拟仿真平台升级了。毕竟它是一个软件系统,谷歌天生就强。这里不包括那些车体动力和电子性能的模拟仿真工作,这个已经存在好多年,是车企的强项,比如它们常用的CarMaker,PreScan,CarSim等商用软件系统。
这是谷歌CarCraft和Xview的样子:
其中提到的"fuzzing"图就是这样的:
仿真模拟平台已经是自动驾驶开发的标配,看看Daimler汽车公司这部分工作的介绍:
还有自动驾驶高校研究的例子:北卡的AutonoVi-Sim
-
智能驾驶传感器发展现状及发展趋势2025-01-16 1685
-
家用电器电机驱动控制技术发展现状及展望2023-07-12 558
-
自动驾驶技术的实现2021-09-03 3072
-
云计算产业发展现状及趋势2021-07-27 5181
-
广播电视发展现状及趋势2021-07-21 2209
-
网联化自动驾驶的含义及发展方向2021-01-12 4820
-
我国自动驾驶发展现状及趋势2020-10-22 14537
-
汽车电子传感器发展现状及趋势是什么2020-05-20 2995
-
2020中国上海国际自动驾驶技术展览会2019-12-08 2820
-
如何让自动驾驶更加安全?2019-05-13 3621
-
2018年车联网的发展现状和发展机遇解读2018-01-23 3382
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7351
-
自动驾驶的到来2017-06-08 7302
-
超宽带雷达的发展现状及应用2016-12-28 1085
全部0条评论

快来发表一下你的评论吧 !
