

对驾驶行为的学习以及对其他车辆驾驶的预测
电子说
描述
自动驾驶里面很重要的就是估计和预测交通情况。预测的来源就是路上各种物体的姿态和速度历史,高级的预测会包括可能的行动轨迹。
对于车辆本身来说,其驾驶动作分析离不开动力学理论(kinematic,dynamic),周围的障碍物,同时还有道路行驶的路况(坡度,曲率)和规则(红绿灯,限速牌,车道线,交叉路口等等)。所有这些因素组合一起就能体现交通参与者的行为模式,而学习这些行为模型就是自动驾驶掌握老司机技术的必然之路。
一共两件事,一是对其他车辆的驾驶行为预测,二是司机驾驶行为建模以便学习模仿这种技术。在ADAS层次,基于错误的驾驶操作危险预测,可以对司机的不良行为警告,这不是这里的讨论范围。
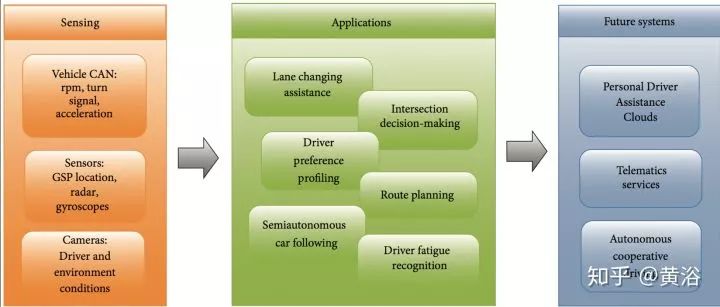
驾驶行为建模(DBM,driver behavior modeling)目的就是预测驾驶动作,预测驾驶员心思,还有环境因素,如下图所示:各种传感器和车载控制器CAN数据作为输入,预处理算法过滤数据,然后给各种应用提供预测模型。
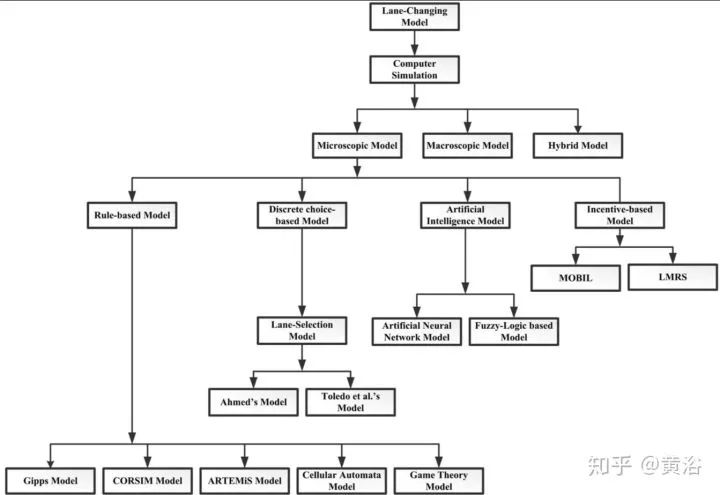
以换车道为例吧,建模方法可以分成微观模型,宏观模型(交通流)和二者混合模型。微观模型又可以细分为基于规则模型,基于(概率)选择模型,AI模型和基于激励模型,见下图。
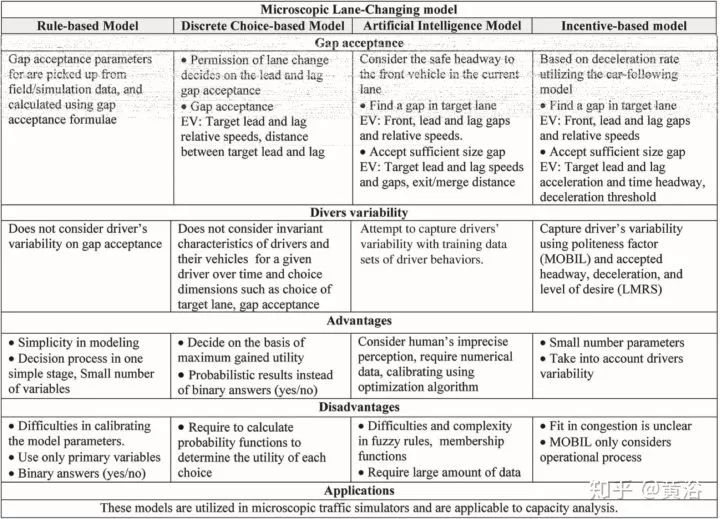
这些微观模型的各个方法在决策(decision),理由(reason),目标车道选择(target lane selection),可接受间距(gap),驾驶习惯(drivers variability)比如激进或者温和 (aggressive or mild)等方面有各自的特色,如下面表格的总结。
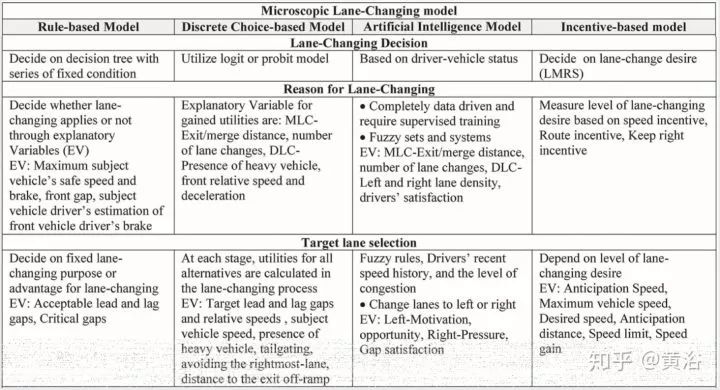
规则法主要是基于Gipps模型建立包含一系列固定条件的决策树,输出是二值选择;也有基于其他的,比如游戏理论的方法;
选择法主要是采用概率模型,最大似然估计给出操作;
AI法需要车辆的行驶数据来训练NN模型;
激励法会考虑车道的吸引度和风险安全标准,也可以加入礼貌之类的个性化因素。
各自的优缺点对比:
规则法建模简单,决策的变量少;难处是参数调节,判决只能二值;
选择法决定来自于其概率计算,获取最大的益处;问题是概率如何计算选择的益处;
AI法是根据司机驾驶的数据,优化模型参数;但数据量要求大,函数复杂度高;
激励法参数少,有驾驶风格选项可以考虑;但是交通拥挤的时候动机不清楚。
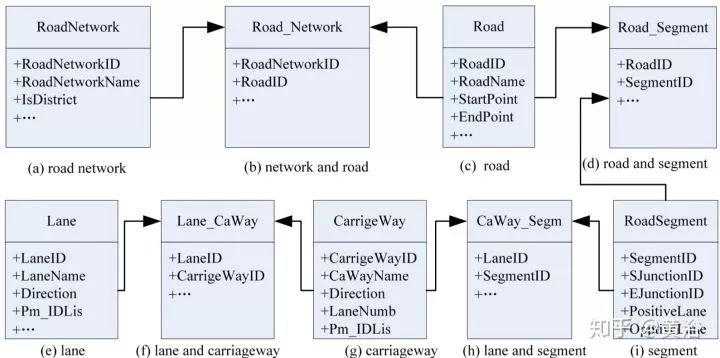
研究DBM,必然涉及道路网络建模(RNM,road network modeling),即道路的拓扑结构。基本上,道路信息包括多个分级结构,如regional road network–road–road segment–carriageway–lane。
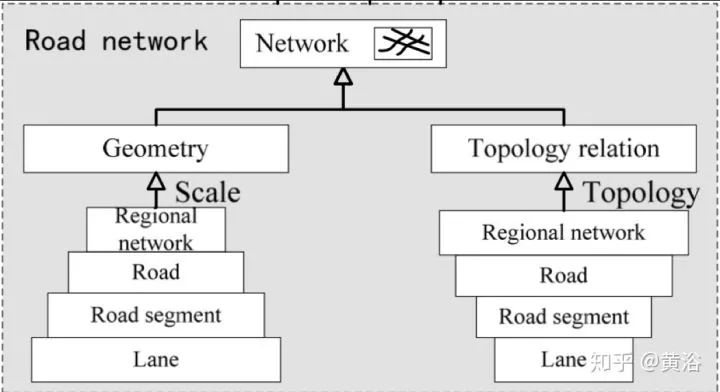
车道(Lane)是最基本的道路单位,而行车道(carriageway)是同一方向和类似交通性质的车道合并而成,如图所示。

而这个是十字路口的行车道网络结构。
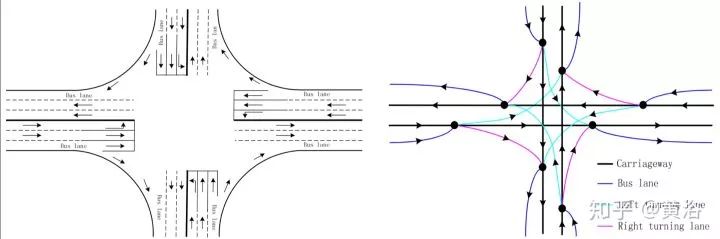
建立一个道路网络和拓扑结构可以像下图一样。
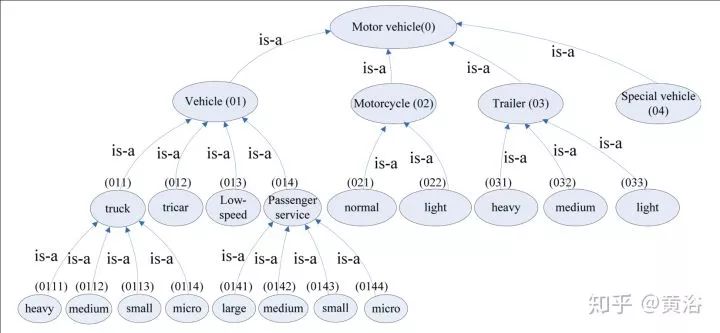
除了道路网络,DBM也需要考虑车辆模型,下图是一个车辆种类划分的分级模型。
下面选几篇论文分析一下做驾驶行为建模及其预测的研究工作。
这一篇文章是讲述如何针对不同场景预测驾驶行为:“A Scenario-Adaptive Driving Behavior Prediction Approach to Urban Autonomous Driving“。
因为城市交通场景经常变化,需要在驾驶行为预测时候考虑对场景的自适应性。首先需要设计一个场景模型库,称为ontology,如下图:包括两个分支,一是Entity,二是Attribute;Entity包括4个部分:
MapEntity。它包括两个部分,即AreaEntity和PointEntity。前者表示道路的一个区域,包括RoadPart,SideWalk,Junction,Segment和Lane。后者表示道路剩下的部分,包括TrafficSign,LaneMarker,StopLine。
ObstacleEntity。包括静态和运动的。
EgoEntity。自身车的部分,VehicleType,EquippedSensors等等。
Environment。包括Weather,LightingConditions和RoadSurfaceConditions。
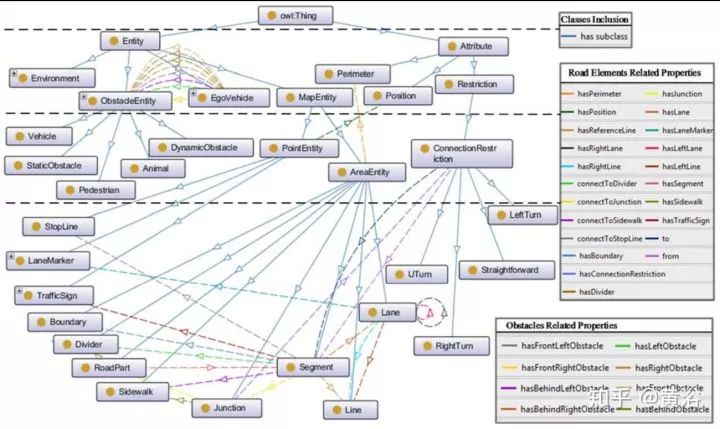
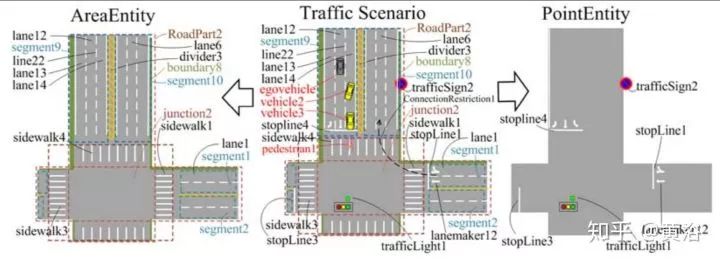
Attributes 描述位置,区域范围和限制类型。包括Position,Perimeter和ConnectedRestriction。下图是一个道路基于此ontology的分解:
回头看,该驾驶行为预测方法的系统框架如图描述:存在两个工作模式,在线和离线。
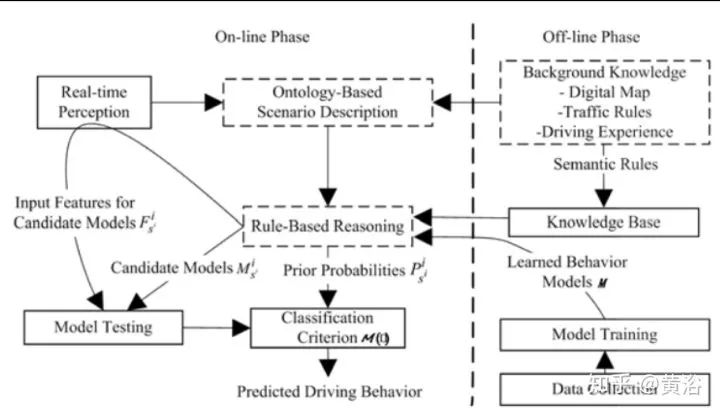
在离线模式,从数字地图中提取道路信息,并根据上面的ontology模型进行描述;先从典型的交通场景里提取数据用于学习驾驶行为的连续特征;每个驾驶模型通过一个HMM学习;基于先验知识(交通规则,驾驶经验)定义候选行为模型,输入特征,以及每个模型的先验知识概率,构成语义规则;所有这些规则存于知识库。
在线模式下,将知识库的所有学习的模型和语义规则在初始化装入内存,然后每个候选行为模型会计算其似然值,结合先验概率得到行为标签(tag)。
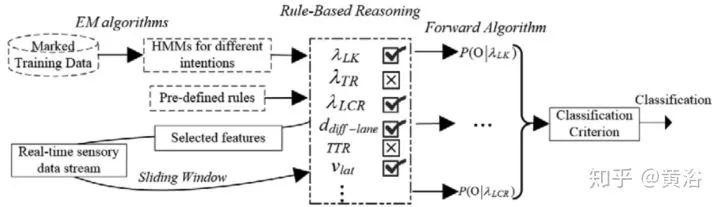
最后驾驶行为的预测方法如图:对应行为集合的一组HMM已经离线学习完成,现在输入实时的感知器数据,那么对于每个车辆,基于规则的推理模块会计算产生其候选模型,而HMM中的Forward算法就能估计每个所选模型的拟合程度,即最大后验估计。
这里给出一个实验例子:
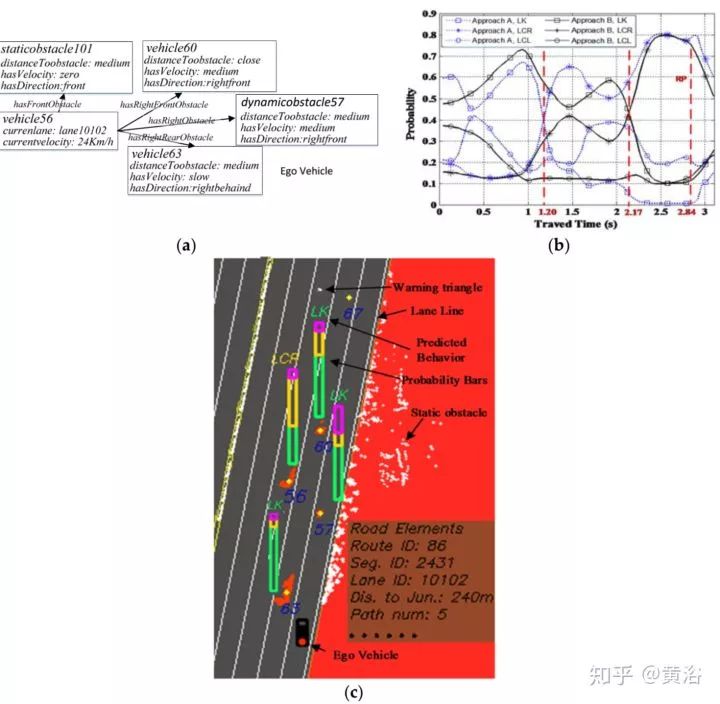
其中 (a) 是场景推理结果, (b) 不同行为似然值,(c) 驾驶行为预测界面。
北卡的驾驶行为预测的工作,两篇论文:
第一篇是规划算法AutonoVi,以支持满足交通约束的无人驾驶动态机动(dynamic maneuvers):“AutonoVi: Autonomous Vehicle Planning with Dynamic Maneuvers and Traffic Constraints”。
其中机动包括拐弯,换道和刹车等动作,要求遵守各种交通规则(路口红灯/stop牌停车)和避撞(行人,车辆,自行车)。下图是算法流水线图:

路径规划在前,按车道驾驶和交通生成一个引导轨迹,以及一串候选控制输入(PID控制器)。这些控制会以数据驱动的车辆动力建模和控制障碍物理论(Control Obstacle)的无碰撞导航为标准评估,最后剩下的轨迹再通过优化算法(Path,Comfort,Maneuver,Proximity等为开销)决定最佳控制信号。
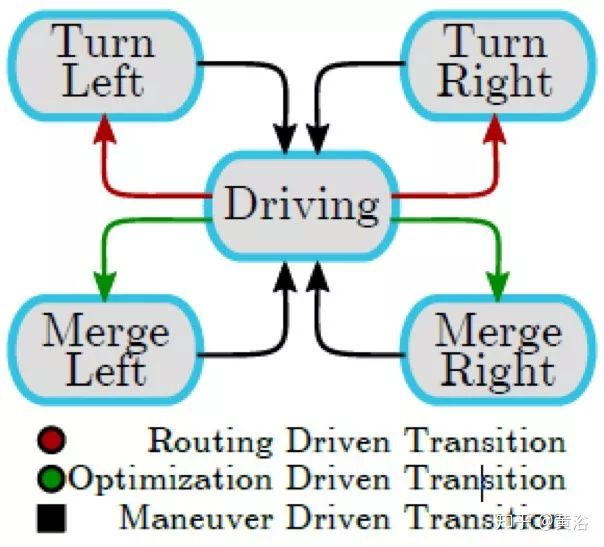
车辆的行为描述为有限状态机(FSM),如下图:
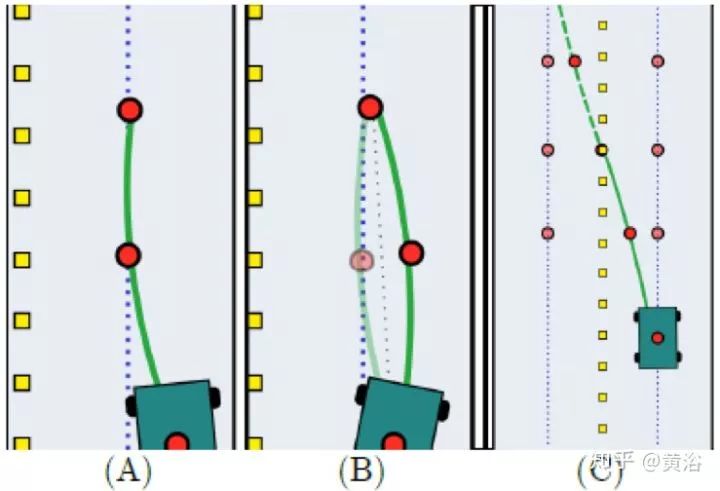
轨迹规划要计算一组沿着车道中心等时间间隔的waypoints。如图给出一个计算引导路径的例子:(a)偏离中心被平滑引回;(b) 突然改变前进方向;(c)换道,离开和目标车道的waypoints加权平均。
第二篇讨论如何从车辆轨迹分析驾驶行为并用于自动驾驶:"Identifying Driver Behaviors using Trajectory Features for Vehicle Navigation"。
算法的框架如图:
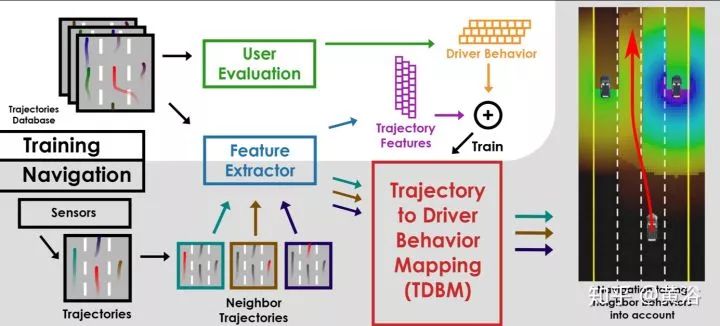
其中定义一个模块叫Trajectory to Driver Behavior Mapping (TDBM),有6种驾驶员行为定义和分析,主要衍生于两种基本模式Aggressiveness 和Carefulness,定义如下。

其中0-5是驾驶行为测度,6-9是注意(attention)测度。
很重要的一点是,作者定义了一组轨迹的特征,以此形成轨迹到行为的映射,10个候选特征见下表,其中绿色部分就是用来计算行为测度的,蓝色是用来一起计算行为测度和注意测度。

选择特征的方法是基于LASSO分析,映射关系最终是矩阵形式。应用在自动驾驶时,选择了前面提到的AutonoVi规划算法。
Uber Toronto最近的驾驶预测工作,有两篇论文
"Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net"
"IntentNet: Learning to Predict Intention from Raw Sensor Data"
第一篇论文介绍一种将目标检测工作和预测合为一体的系统FAF,如图所示:
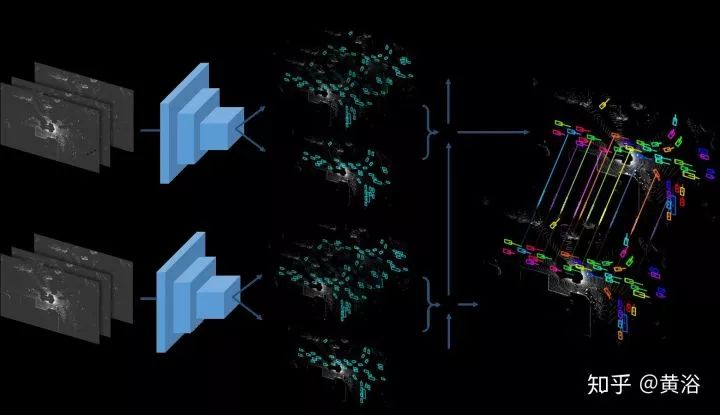
这里数据是激光雷达的点云,利用它的鸟瞰投影作为模型输入。其实预测部分才是我们感兴趣的,当然三合一的NN模型是新颖的方式。模型输入多帧数据构成4-D张量,利用3-D卷积做预测。下图是运动预测的示意图(t, t+1, ...,t+n-1):

第二篇论文在此基础上,定义意向(intent)是一个高级行为和连续的轨迹的组合,提出了一个预测意向的模型IntentNet。看看模型的输入,输出和模型结构的介绍:
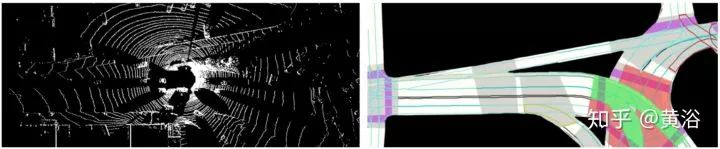
输入如上图,左边是点云鸟瞰投影,右边是静态地图部分,包括道路,车道,十字路口,交通牌和红绿灯等。
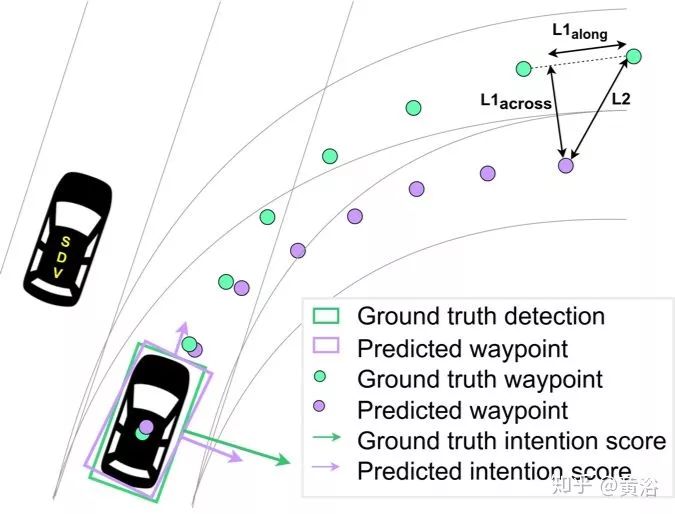
下图是输出部分:绿色是groundtruth,粉色是预测的结果,箭头表示意向分数,针对定义的8种行为类型而言,即保持车道,左转,右转,换左道,换右道,停止,泊车和其他。
下图是模型结构:一种后融合方法。
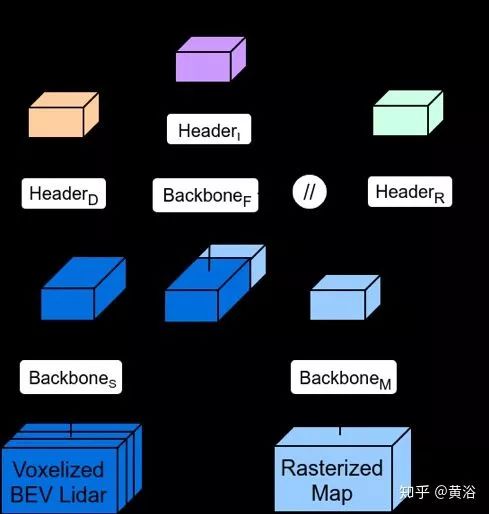
其中一些模型细节:
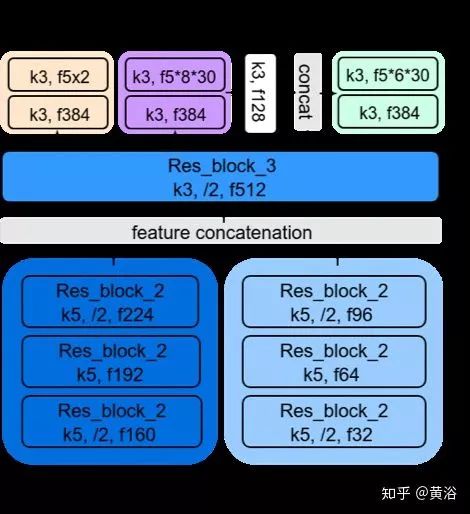
关于学习驾驶行为的工作,先介绍一篇相对旧的文章,是普林斯顿大学X教授研究组的:“DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving“。
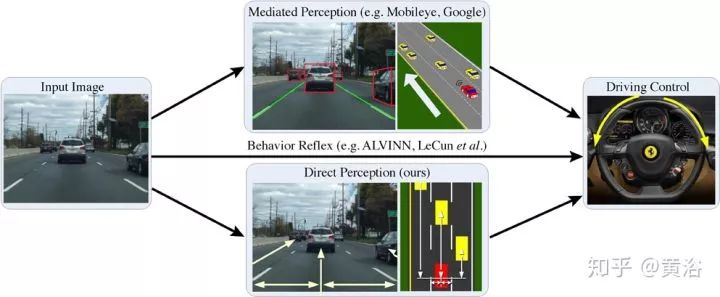
这个图对E2E学习“老”司机驾驶的方法进行划分:mediated perception,分析观测场景得到驾驶决策;behavior reflex 直接映射传感器数据(图像为例)到驾驶动作,有些类似特斯拉提出的Autopilot software 2.0;第三种方法,direct perception,作者定义affordance,标记一些如车辆相对道路的角度,到车道线的距离,和相邻车辆的距离等,这些信息由感知得到,然后映射到驾驶动作。
沿着Affordance这个思路,看看最近苏黎世ETH的驾驶行为学习工作:“Conditional Affordance Learning for Driving in Urban Environments“。
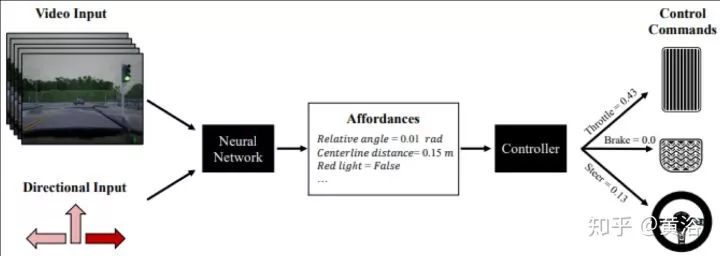
为了和模拟学习或条件性模拟学习区别开,作者称自己的方法为Conditional Affordance Learning (CAL) 。上图所示,输入的除了传感器的数据(视频为例),还有一些高级方向性的信号,即“直行“,”左行“和”右行“之类的行为类别。
下图给出系统的框图:模型训练出来一组驾驶行为Affordance,送入车辆控制器。
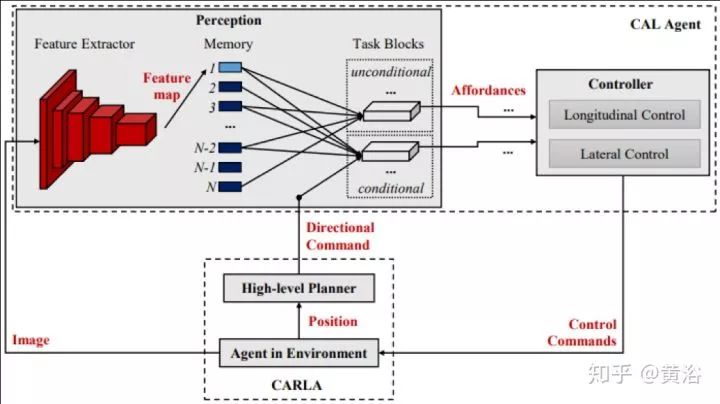
定义的Affordance见左下表:分类取决于种类(连续/离散)和条件性(红绿灯,限速)。
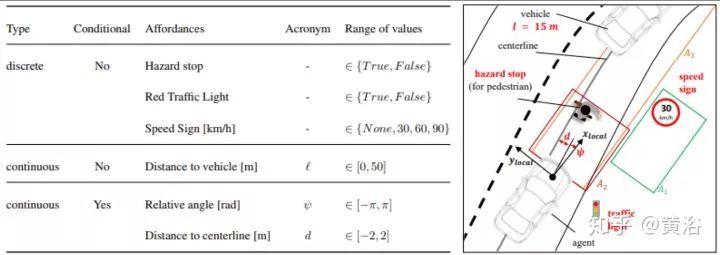
文中定义了6个危险事件:驾驶车道错误,车上行人道,闯红灯,车相撞,撞行人,和撞静态物体。训练在开源仿真模拟软件Carla进行,测试也是。
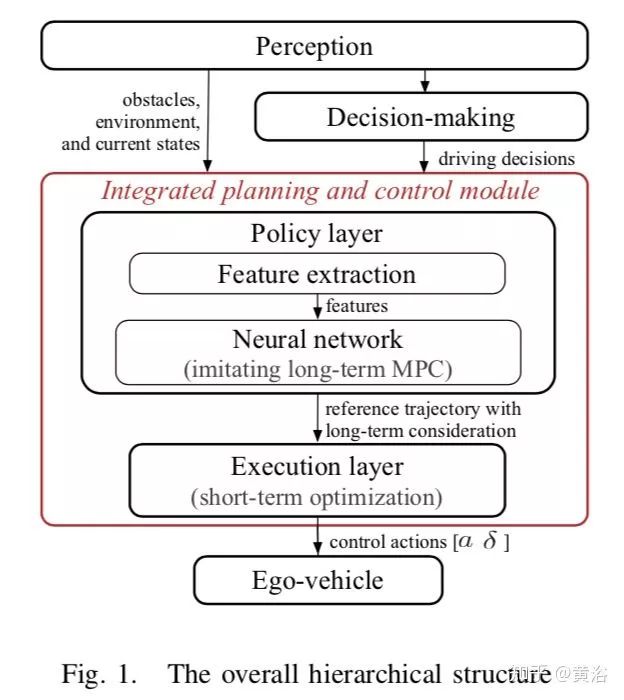
加州伯克利分校的这个工作是通过模拟学习(Imitation Learning)方法得到一个集成规划和控制的框架,结合了机器学习和优化理论的两层分级结构:“A Fast Integrated Planning and Control Framework for Autonomous Driving via Imitation Learning“ 。
这个框架的第一层是policy layer,通过NN学习长期的最优MPC驾驶策略,第二层是execution layer,主要跟踪上一层policy layer生成的参考轨迹(reference trajectory),是一个保证短期安全和可行性的基于优化的短期控制器。特别提出的一点,第一层采用在线模拟学习,其中借用了dataset aggregation(DAgger)的方法,可以快速连续地改进policy layer。
下图是整个分级二层结构:包括感知,决策,规划控制等模块。它不是一个E2E的模拟学习方法,其实包括感知在内的E2E机器学习框架是比较risky的,以前也提过这种corner case太多。
下图是定义的Sampled DAgger,用在policy layer的模拟学习:
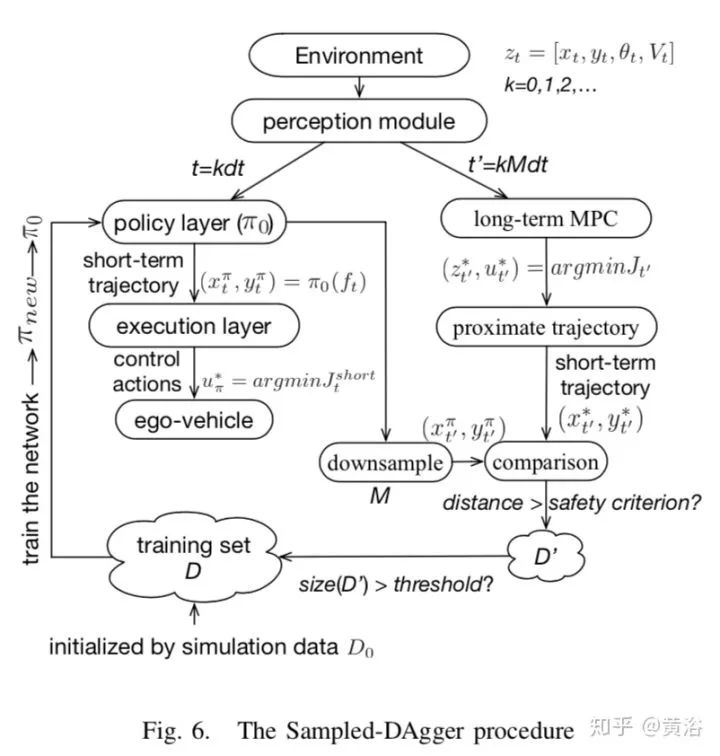
跟以前的DAgger相比,Sampled DAgger的数据效率更高。
另外,论文里做了对学习的policy泛化处理,可以用在复杂的驾驶场景,下图是一个多车道的驾驶场景:
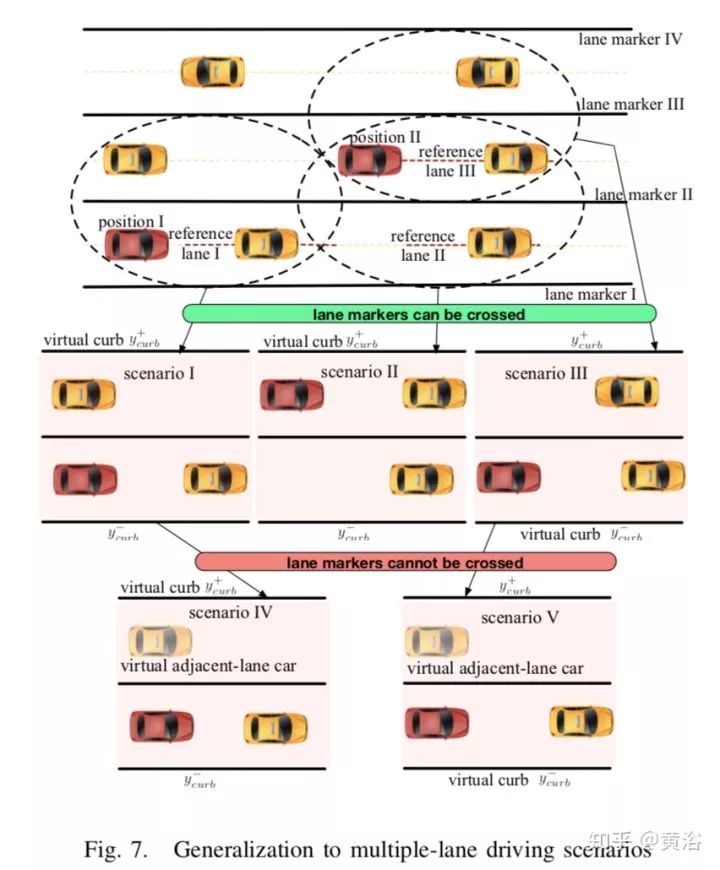
泛化就是将一个连续驾驶的问题降为一系列的抽象场景,而每个抽象场景能直接应用学习的policy模型来求解。
谷歌WayMo的最新文章介绍通过驾驶数据模拟学习驾驶策略:“ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst“。
该文反对纯粹地模拟所有数据,而是在模拟损失上附加一些损失(比如碰撞,离开路和几何上轨迹的不光滑等)来惩罚不期望出现的事件和鼓励进步,这些扰动增强了模型的鲁棒性。实验中表明ChauffeurNet模型可以处理复杂的情况。
以下图是模型的输入-输出:地图,交通灯,限速,路径,自身位置和姿态,其他车辆/行人/自行车的位置和姿态和自身姿态的过去轨迹,作为输入,而输出是自身的下一个姿态。

驾驶模型包括几个部分,如下图:FeatureNet,AgentRNN,Road Mask Net,PerceptionRNN。
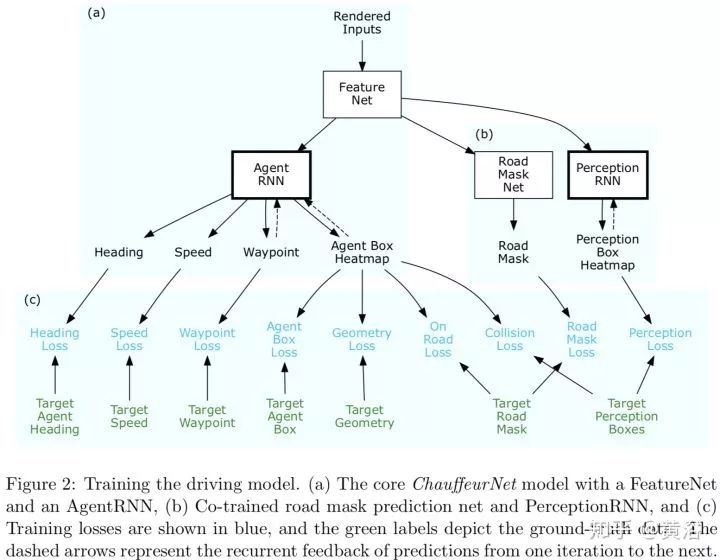
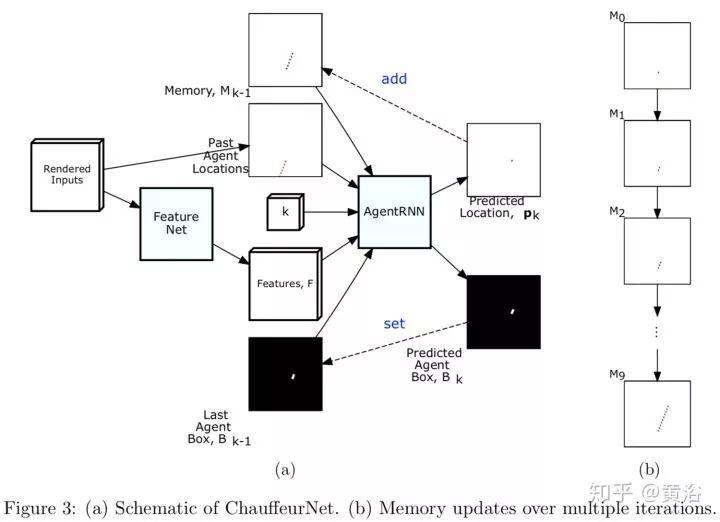
更详细的描述可以见下图:那些输入先进入FeatureNet输出Feature,然后再进入AgentRNN来预测驾驶轨迹的下一个位置,车身的heatMap,迭代次数,以前预测的Memory(单通道图像,是一个叠加型内存,每次迭代会在预测位置加一),和上次迭代预测的车身heatMap。
整个软件系统框图如下:

实验中特意提到有一个路旁停车被成功地绕开的例子。
总的看,驾驶行为的学习以及对其他车辆驾驶的预测都是目前比较关键的问题,如果感知的一些不足,可以说是一些失误,能不能被行为模型看成噪声或者干扰而成功忽略和“屏蔽”,那么就是自动驾驶模块化的研发过程中成功的进步。但目前的实验,还不能证明这一点,主要是数据不够,而且驾驶模型中ontology也不完备。
另外大家也认为感知和规划应该被看成一个整体,所以研发的次序应该是在感知和规划+控制的交替中前进,感知的进步会驱使驶决策模型的更新。
-
基于SD卡的驾驶行为再现存储系统设计2009-05-17 2714
-
无人驾驶上的车辆传感器2017-04-28 8589
-
细说关于自动驾驶那些事儿2017-05-15 7217
-
所有看见的车辆都为自动驾驶提供了动力2018-10-16 2483
-
UWB主动定位系统在自动驾驶中的应用实践2018-12-14 3302
-
高级辅助驾驶ADAS技术2019-04-03 2612
-
全高级驾驶员的感知系统2020-05-13 2988
-
从辅助驾驶到自动驾驶: 感知型车辆建立在底层高质量的传感器数据基础之上2020-06-16 2555
-
自动驾驶车辆中AI面临的挑战2021-02-22 2670
-
智能驾驶域控制器的SoC芯片选型2022-08-11 3847
-
智能传感器如何改变驾驶方式2022-11-09 705
-
如何让自动驾驶车辆看得更多2018-02-08 5113
-
推动自动驾驶汽车发展的四项技术2019-03-05 999
-
基于迁移学习的驾驶分心行为识别模型2021-04-30 1298
-
基于区块链的自动驾驶车辆电池寿命预测方法2024-01-05 1149
全部0条评论

快来发表一下你的评论吧 !
