

Mozilla基金会发起的Common Voice项目,发布新版语音识别数据集
电子说
描述
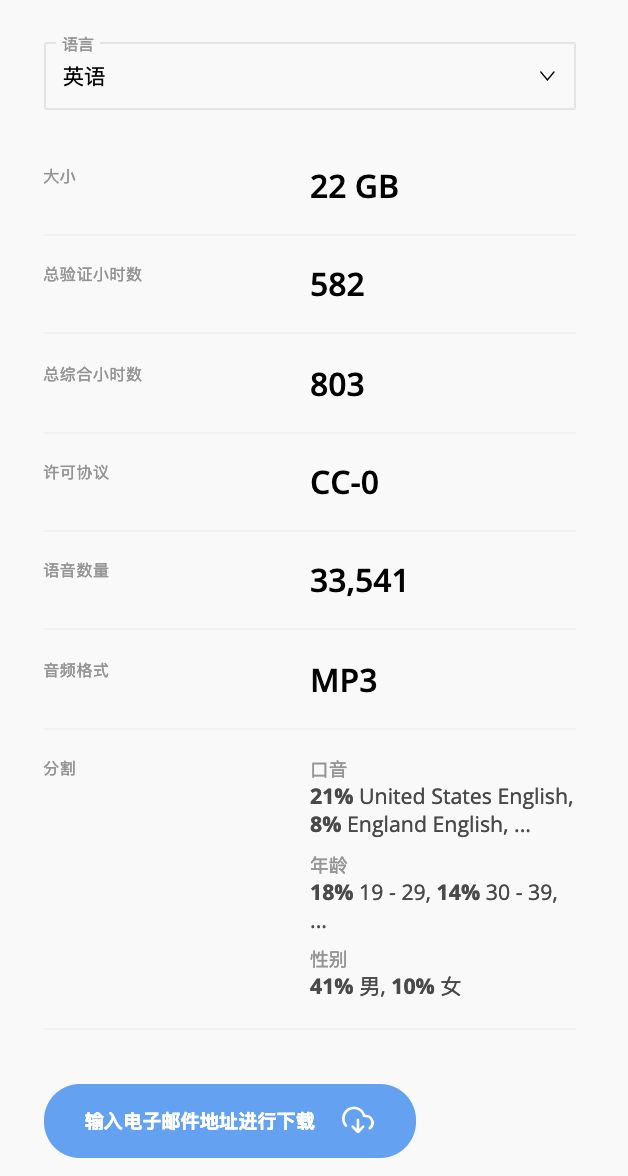
3 月 1 日,由 Mozilla 基金会发起的 Common Voice 项目,发布新版语音识别数据集,包括来自 42000 名贡献者,超过 1400 小时的语音样本数据,涵盖包括英语、法语、德语、荷兰语、汉语在内的 18 种语言。
(数据集链接:https://voice.mozilla.org/zh-CN/datasets)
Common Voice 项目可以集成到由 DeepSpeech,也就是基于 DeepSpeech 语音识别框架的一套语音转文本的开源语音识别引擎。它不仅包括语音片段,还包括对训练语音引擎有用的元数据,如说话者的年龄、性别和口音,收集这些语音片段需要做大量的工作。目前 DeepSpeech 项目已在GitHub上获得了 9418 个 Star,1674 个 fork。
(GitHub 传送门:https://github.com/mozilla/DeepSpeech)
它目前是同类项目中最大的多语言数据集之一,Mozilla 声称,此次发布的数据集比八个月前公开发布的 Common Voice 语料库要更加庞大,其中包含来自 20,000 名英语志愿者的 500 小时语音数据(400,000 条录音),而且语料库还将进一步扩充。该基金会表示,通过 Common Voice 网站和移动应用,他们正在积极开展 70 种语言的数据收集工作。
2017 年 6 月,Mozilla 宣布推出 Project Common Voice 众包计划,旨在为语音识别应用构建开源数据集。他们邀请来自世界各地的志愿者通过网络和移动应用贡献语音记录的文本片段,当然,他们会非常严格地保护项目贡献者的隐私。
2017 年 11 月,Mozilla 基金会发布了第一批 Common Voice 英语数据集成果,该数据集包括大约 500 个小时的语音数据,以及来自 20,000 个志愿者贡献的 400,000 条录音。2018 年 6 月,Mozilla 开始收集法语、德语和威尔士语等 40 多种语种的众包语音数据。
为了简化流程,Mozilla 本周还推出了一款改进的 Common Voice web 工具,其可以对不同的语音剪辑进行更改,还增加了用于查看、重新录制和跳过剪辑的新控件,一个可以快速切换仪表板的“说话”和“收听”模式的开关,以及选择退出语音会话的选项。此外,它正在推出新的配置文件功能,允许用户跨语言跟踪他们的语言进度和指标,并添加人口统计信息。
未来几个月里,Mozilla 表示将尝试不同的方法来增加数据收集的数量,提升数据质量,并且最终计划使用部分录音数据来开发语音产品。
语音技术将是一大科技技术革新,但可惜的是,目前操纵这场革新游戏的只有大型科技公司。
首先,科技巨头一般都来自科技强国,而用于训练机器的语音数据目前更偏向于英语、中文等一些特定的语言,在多样性方面,显然这并不适合全人类。
其次,像亚马逊、谷歌、苹果这样的科技巨头正在大力投资他们的智能助手,但由此产生的数据集并不对外开放,而像学生、创业公司和对构建语音设备感兴趣的人只能访问非常有限的数据集,而且可能还需要付费购买。
基于此,Mozilla 基金会认为,没有足够的数据开放给公众使用,将会扼杀科技创新,开放语音数据集则可以让更多人参与进来,让任何人都可以自由地使用该数据集,将语音技术嵌入到各种应用和服务中。这类似于 OpenStreetMap 这样的开放众包项目,该项目为开发人员提供开放且可自由使用的世界地图。
在新的数据集发布后,外国网友们也对此进行了评价:
看到开放数据领域的创新真是太好了。最近有许多断言认为,质量更高的 ML 数据将要比 ML 算法更重要,这么说是对的,特别是在语音识别等领域。然而,要赶上科技巨头还有很长的路要走。因为在 15 年前,就有公司每年会处理 100 万分钟的标签语音数据。
除非我们在这方面进行投资,否则老牌企业和新进入这个市场的企业之间的数据差距将继续扩大。
另有网友花了时间验证了一些语音,他在评论中表达了质疑称:
至少在我能听出来的范围内,我没有听到任何句子说错了。不过,我确实遇到了大量非常糟糕的样本,以至于有些难以理解。比如口音重、有背景噪音或者非常安静,而且他觉得一些“机械的”样本是通过文本转语音软件生成的。所以 Common Voice 能提供优质数据吗?
还有网友拿开源数据集 LibriSpeech 做了对比:
ASR 训练的有声读物是绝对不错的。事实上,在 Common Voice 之前,最大的 ASR 公开训练数据集是 LibriSpeech (http://www.openslr.org/12/)。同样值得注意的是,Mozilla 的 DeepSpeech 模型的第一个版本使用 LibriSpeech 进行了训练和测试。但是正如其他人提到的由于一些数据集不够好,由 Common Voice 的数据集训练的有声读物存在一些瑕疵。
但是 Common Voice 的目标不是取代 LibreSpeech 或其他开放数据集(如 TED 演讲)作为训练数据集,而是它们的有益补充。
总之,相较于目前已开源的其他语音数据集类型单一,数据量不足,数据杂乱的情况,虽然而 Common Voice 的数据集有不足,但在综合多样性、丰富性和质量方面都遥遥领先。它有望被全世界更大范围内的开发者们所关注并受益,也将为语音技术的发展带来不可估量的价值。
-
开放原子开源基金会发布150余个开源项目应用案例2025-07-28 1055
-
车内语音识别数据在智能驾驶中的价值与应用2024-02-19 1262
-
车内语音识别数据在智能驾驶中的应用与挑战2024-01-26 1930
-
车内语音识别数据:驾驶体验升级与智能出行的未来2023-11-08 995
-
车载语音识别数据的社会影响与未来展望2023-08-28 954
-
车内语音识别数据是驱动智能出行的新动力2023-07-09 955
-
人脸识别数据集应用和研究2023-04-21 1757
-
高质量手势识别数据集让手势识别算法更准确2023-04-14 1938
-
开放原子开源基金会联合发起“openDACS开源电路与系统设计自动化”开源项目2022-06-24 1834
-
OpenInfra发起“定向基金”计划,为开源项目建立可持续社区2022-06-07 1508
-
国内唯一开源基金会“开放原子开源基金会“正式成立!2020-09-10 4666
-
Mozilla使用开源Common Voice语音识别数据集进行多语言操作2018-06-12 5333
-
树莓派基金会发布桌面操作系统 PIXEL OS2016-12-31 8432
全部0条评论

快来发表一下你的评论吧 !
