

微软、中科大开源基于深度高分辨表示学习的姿态估计算法
电子说
描述
昨天arXiv出现了好几篇被CVPR 2019接收的论文。
其中来自微软和中国科技大学研究学者的论文《Deep High-Resolution Representation Learning for Human Pose Estimation》和相应代码甫一公布,立刻引起大家的关注,不到一天之内,github上已有将近50颗星。
今天就跟大家一起来品读此文妙处。
该文作者信息:

该文为第一作者Ke Sun在微软亚洲研究院实习期间发明的算法。
基本思想
作者观察到,现有姿态估计算法中往往网络会有先降低分辨率再恢复高分辨率的过程,比如下面的几种典型网络。
为便于表达,在下面的a、b、c、d四幅图中,同一水平线上的特征图为相同分辨率,越向下分辨率越小,在最终的高分辨率特征图heatmap中计算姿态估计的关键点。
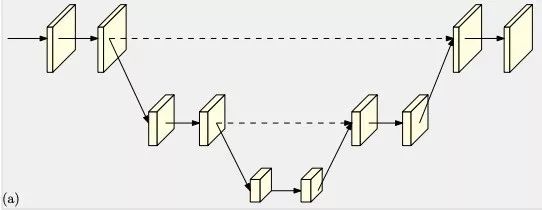
Hourglass

Cascaded pyramid networks
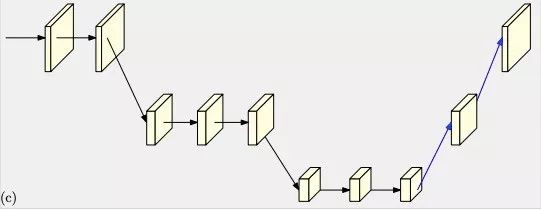
Simple baseline
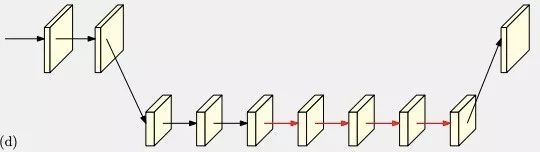
Combined with dilated convolutions
其中的网络结构说明如下:

作者希望不要有这个分辨率恢复的过程,在网络各个阶段都存在高分辨率特征图。
下图简洁明了地表达作者的思想。
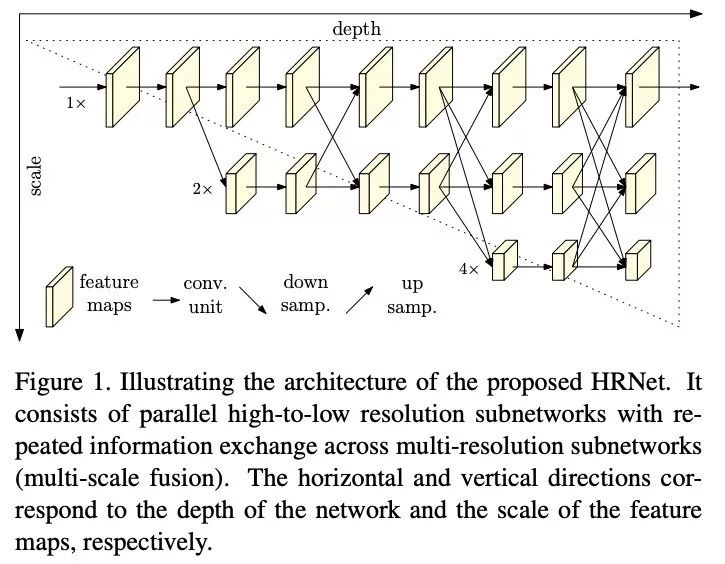
在上图中网络向右侧方向,深度不断加深,网络向下方向,特征图被下采样分辨率越小,相同深度高分辨率和低分辨率特征图在中间有互相融合的过程。
作者描述这种结构为不同分辨率子网络并行前进。
关键点的heatmap是在最后的高分辨率特征图上计算的。
网络中不同分辨率子网络特征图融合过程如下:

主要是使用strided 3*3的卷积来下采样和up sample 1*1卷积上采样。
这么做有什么好处?
作者认为:
1)一直维护了高分辨率特征图,不需要恢复分辨率。
2)多次重复融合特征的多分辨率表示。
实验结果
该算法在COCO姿态估计数据集的验证集上测试结果:
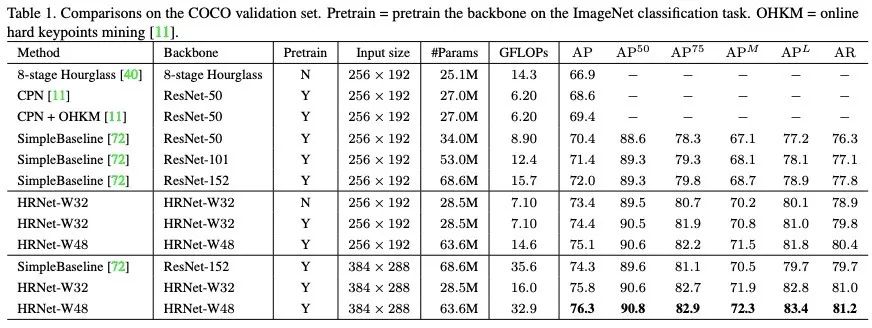
与目前的state-of-the-art比较,取得了各个指标的最高值。相同分辨率的输入图像,与之前的最好算法相比增长了3个百分点!
在COCO test-dev数据集上,同样一骑绝尘!
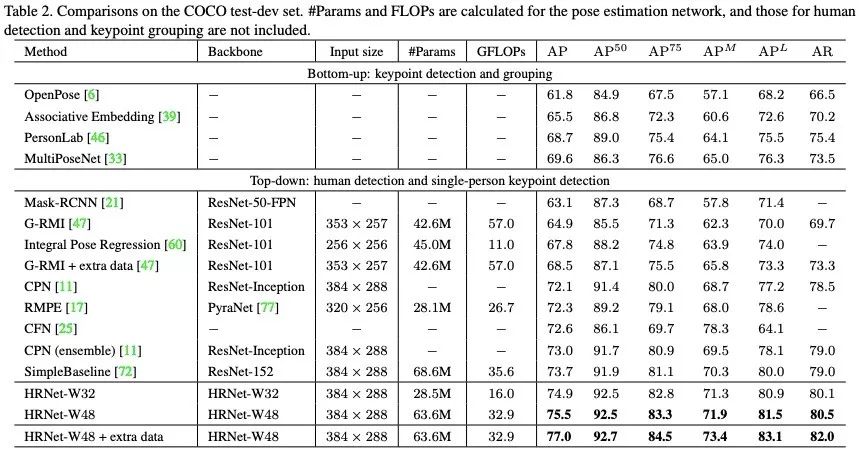
在MPII test 数据集上,同样取得了最好的结果!

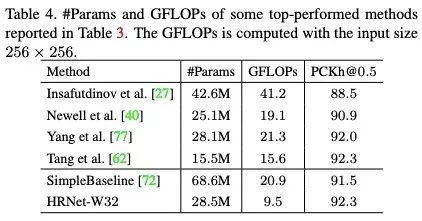
作者进一步与之前最好模型比较了参数量、计算量,该文发明的HRNet-W32在精度最高的同时,计算量最低!
如下图:
在PoseTrack2017姿态跟踪数据集上的结果比较:
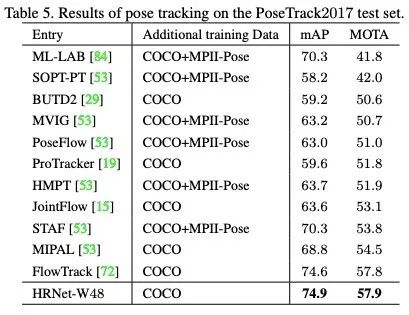
同样取得了最好的结果。
下图是算法姿态估计的结果示例:
(请点击查看大图)
不仅仅是姿态估计
作者在官网指出,深度高分辨率网络不仅对姿态估计有效,也可以应用到计算机视觉的其他任务,诸如语义分割、人脸对齐、目标检测、图像分类中,期待更多具有说服力的结果公布。
-
基于飞控的姿态估计算法作用及原理2023-11-13 2562
-
在医疗AI领域砥砺前行的中科大学子2021-05-10 6083
-
基于深度学习的二维人体姿态估计算法2021-04-27 1218
-
基于深度学习的二维人体姿态估计方法2021-03-22 1376
-
51单片机资料(中科大)2014-06-23 7754
-
溷沌数字通信(中科大出版的)2012-08-16 3484
-
中科大嵌入式课件全集2012-08-14 10943
-
51单片机C语言编程入门(中科大)2012-08-06 7424
-
华中科大发的论文《新一代TSC2046触摸屏控制器》2012-08-03 2572
-
微机原理与接口技术 中科大教材2009-12-07 10315
-
人口模型讲义 (中科大课程)2009-09-15 526
-
中科院中科大2003年量子力学考研试题答案2008-11-25 2125
全部0条评论

快来发表一下你的评论吧 !
