

为什么要有attention机制,Attention原理
电子说
描述
1.1 attention model
为什么要有attention机制
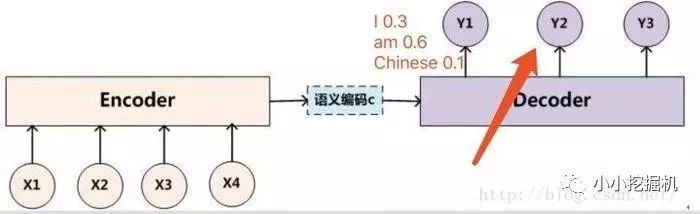
原本的Seq2seq模型只有一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。
attention即为注意力,人脑在对于的不同部分的注意力是不同的。需要attention的原因是非常直观的,当我们看一张照片时,照片上有一个人,我们的注意力会集中在这个人身上,而它身边的花草蓝天,可能就不会得到太多的注意力。也就是说,普通的模型可以看成所有部分的attention都是一样的,而这里的attention-based model对于不同的部分,重要的程度则不同,decoder中每一个时刻的状态是不同的。
Attention-based Model是什么Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
没有attention机制的encoder-decoder结构通常把encoder的最后一个状态作为decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是encoder的state毕竟是有限的,存储不了太多的信息,对于decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。attention机制的引入之后,decoder根据时刻的不同,让每一时刻的输入都有所不同。
Attention原理
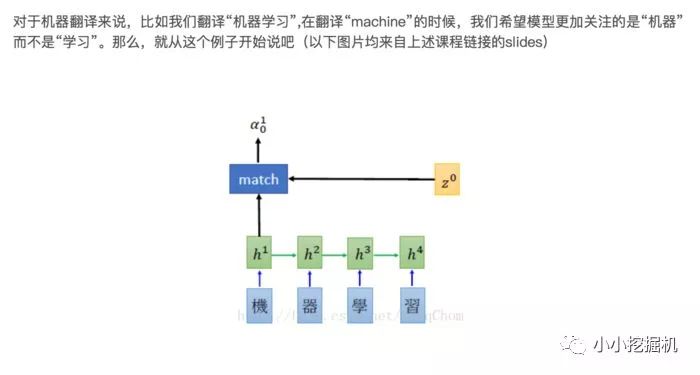

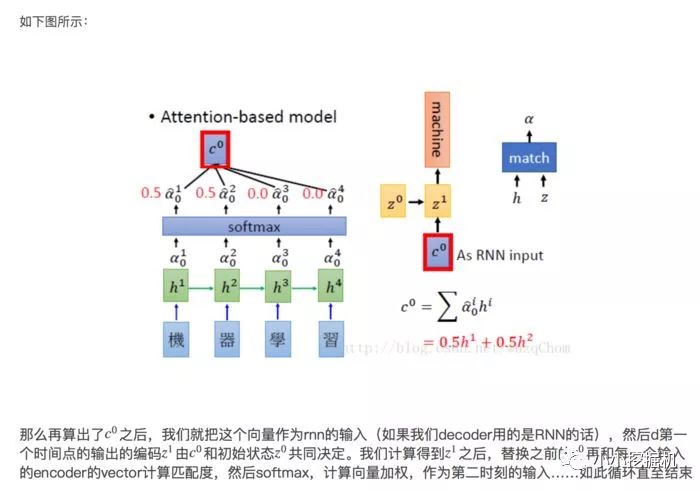
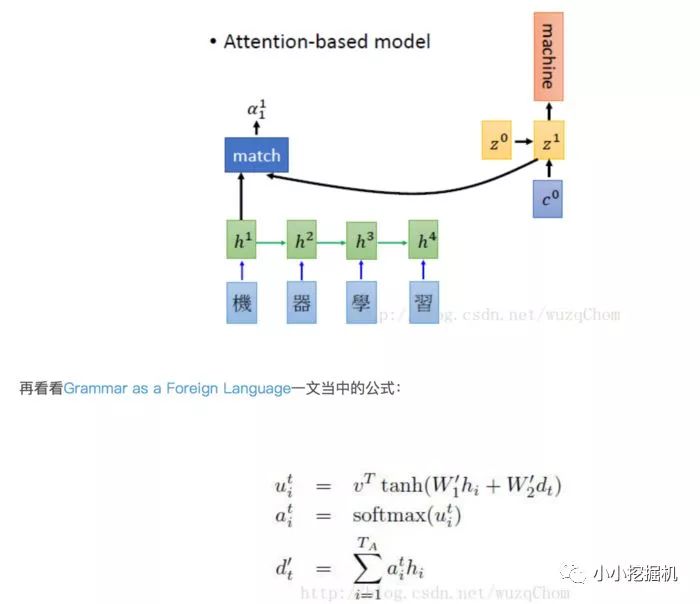
1.2 Beam Search介绍
在sequence2sequence模型中,beam search的方法只用在测试的情况,因为在训练过程中,每一个decoder的输出是有正确答案的,也就不需要beam search去加大输出的准确率。
假设现在我们用机器翻译作为例子来说明,
我们需要翻译中文“我是中国人”--->英文“I am Chinese”
假设我们的词表大小只有三个单词就是I am Chinese。那么如果我们的beam size为2的话,我们现在来解释,如下图所示,我们在decoder的过程中,有了beam search方法后,在第一次的输出,我们选取概率最大的"I"和"am"两个单词,而不是只挑选一个概率最大的单词。
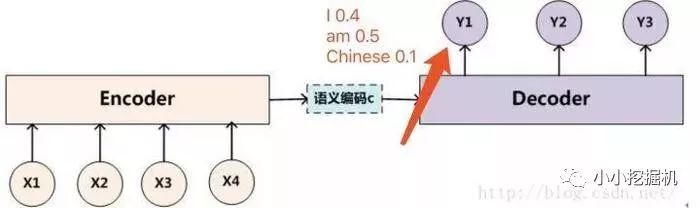
然后接下来我们要做的就是,把“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布,把“am”单词作为下一个decoder的输入算一遍也得到y2的输出概率分布。
比如将“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
比如将“am”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
那么此时我们由于我们的beam size为2,也就是我们只能保留概率最大的两个序列,此时我们可以计算所有的序列概率:
“I I” = 0.40.3 "I am" = 0.40.6 "I Chinese" = 0.4*0.1
"am I" = 0.50.3 "am am" = 0.50.3 "am Chinese" = 0.5*0.4
我们很容易得出俩个最大概率的序列为 “I am”和“am Chinese”,然后后面会不断重复这个过程,直到遇到结束符为止。
最终输出2个得分最高的序列。
这就是seq2seq中的beam search算法过程。
2.1 tf.app.flags
tf定义了tf.app.flags,用于支持接受命令行传递参数,相当于接受argv。看下面的例子:
import tensorflow as tf#第一个是参数名称,第二个参数是默认值,第三个是参数描述tf.app.flags.DEFINE_string('str_name', 'def_v_1',"descrip1")tf.app.flags.DEFINE_integer('int_name', 10,"descript2")tf.app.flags.DEFINE_boolean('bool_name', False, "descript3")FLAGS = tf.app.flags.FLAGS#必须带参数,否则:'TypeError: main() takes no arguments (1 given)'; main的参数名随意定义,无要求def main(_): print(FLAGS.str_name)print(FLAGS.int_name)print(FLAGS.bool_name)if __name__ == '__main__':tf.app.run() #执行main函数
使用命令行运行得到的输出为:
[root@AliHPC-G41-211 test]# python tt.pydef_v_110False[root@AliHPC-G41-211 test]# python tt.py --str_name test_str --int_name 99 --bool_name Truetest_str99True
2.2 tf.clip_by_global_norm
Gradient Clipping的直观作用就是让权重的更新限制在一个合适的范围。tf.clip_by_global_norm函数的作用就是通过权重梯度的总和的比率来截取多个张量的值。使用方式如下:
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
t_list 是梯度张量, clip_norm 是截取的比率, 这个函数返回截取过的梯度张量和一个所有张量的全局范数。
t_list[i] 的更新公式如下:
t_list[i] * clip_norm / max(global_norm, clip_norm)
其中global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))global_norm 是所有梯度的平方和,如果 clip_norm > global_norm ,就不进行截取。
2.3 tf中注意力机制的实现
注意力机制只在decoder中出现,在之前作对联的文章中,我们的decoder实现分三步走:定义decoder阶段要是用的Cell -》TrainingHelper+BasicDecoder的组合定义解码器-》调用dynamic_decode进行解码。
添加注意力机制主要是在第一步,对Cell进行包裹,tf中实现了两种主要的注意力机制,我们前文中所讲的注意力机制我们成为Bahdanau注意力机制,还有一种注意力机制称为Luong注意力机制,二者最主要的区别是前者为加法注意力机制,后者为乘法注意力机制。二者的更详细的介绍参考播客:http://blog.csdn.net/amds123/article/details/65938986
那么我们就来详细介绍一下 tf中注意力机制的实现:
定义cell
def _create_rnn_cell(self):def single_rnn_cell(): # 创建单个cell,这里需要注意的是一定要使用一个single_rnn_cell的函数,不然直接把cell放在MultiRNNCell # 的列表中最终模型会发生错误 single_cell = tf.contrib.rnn.LSTMCell(self.rnn_size) #添加dropout cell = tf.contrib.rnn.DropoutWrapper(single_cell, output_keep_prob=self.keep_prob_placeholder) return cell#列表中每个元素都是调用single_rnn_cell函数cell = tf.contrib.rnn.MultiRNNCell([single_rnn_cell() for _ in range(self.num_layers)])return celldecoder_cell = self._create_rnn_cell()
封装attention wrapper
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(num_units=self.rnn_size, memory=encoder_outputs, memory_sequence_length=encoder_inputs_length)#attention_mechanism = tf.contrib.seq2seq.LuongAttention(num_units=self.rnn_size, memory=encoder_outputs, memory_sequence_length=encoder_inputs_length)decoder_cell = tf.contrib.seq2seq.AttentionWrapper(cell=decoder_cell, attention_mechanism=attention_mechanism, attention_layer_size=self.rnn_size, name='Attention_Wrapper')
训练阶段,使用TrainingHelper+BasicDecoder的组合
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_inputs_embedded, sequence_length=self.decoder_targets_length, time_major=False, name='training_helper')training_decoder = tf.contrib.seq2seq.BasicDecoder(cell=decoder_cell, helper=training_helper, initial_state=decoder_initial_state, output_layer=output_layer)
调用dynamic_decode进行解码
decoder_outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=self.max_target_sequence_length)
decoder_outputs是一个namedtuple,里面包含两项(rnn_outputs, sample_id)rnn_output: [batch_size, decoder_targets_length, vocab_size],保存decode每个时刻每个单词的概率,可以用来计算loss sample_id: [batch_size], tf.int32,保存最终的编码结果。可以表示最后的答案。
代码目录如下图所示:
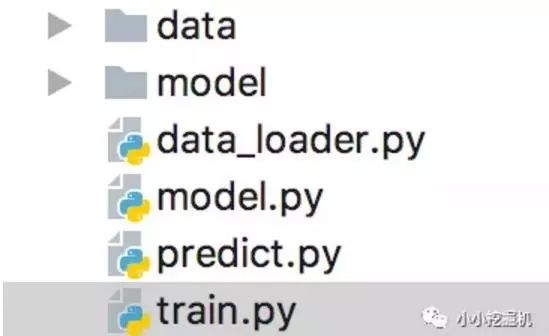
其中,data存放我们的数据,model存放我们保存的训练模型,data_loader是我们处理数据的代码,model是我们建立seq2seq模型的代码,train是我们训练模型的代码,predict是我们进行模型预测的部分。这里我们只介绍model部分,其它部分的代码大家可以参照github自己练习。
定义基本的输入输出
def __init__(self, rnn_size, num_layers, embedding_size, learning_rate, word_to_idx, mode, use_attention, beam_search, beam_size, max_gradient_norm=5.0):self.learing_rate = learning_rateself.embedding_size = embedding_sizeself.rnn_size = rnn_sizeself.num_layers = num_layersself.word_to_idx = word_to_idxself.vocab_size = len(self.word_to_idx)self.mode = modeself.use_attention = use_attentionself.beam_search = beam_searchself.beam_size = beam_sizeself.max_gradient_norm = max_gradient_norm#执行模型构建部分的代码self.build_model()
定义我们多层LSTM的网络结构这里,不论是encoder还是decoder,我们都定义一个两层的LSTMCell,同时每一个cell都添加上DropoutWrapper。
def _create_rnn_cell(self):def single_rnn_cell(): # 创建单个cell,这里需要注意的是一定要使用一个single_rnn_cell的函数,不然直接把cell放在MultiRNNCell # 的列表中最终模型会发生错误 single_cell = tf.contrib.rnn.LSTMCell(self.rnn_size) #添加dropout cell = tf.contrib.rnn.DropoutWrapper(single_cell, output_keep_prob=self.keep_prob_placeholder) return cell#列表中每个元素都是调用single_rnn_cell函数cell = tf.contrib.rnn.MultiRNNCell([single_rnn_cell() for _ in range(self.num_layers)])return cell
定义模型的placeholder
self.encoder_inputs = tf.placeholder(tf.int32, [None, None], name='encoder_inputs')self.encoder_inputs_length = tf.placeholder(tf.int32, [None], name='encoder_inputs_length')self.batch_size = tf.placeholder(tf.int32, [], name='batch_size')self.keep_prob_placeholder = tf.placeholder(tf.float32, name='keep_prob_placeholder')self.decoder_targets = tf.placeholder(tf.int32, [None, None], name='decoder_targets')self.decoder_targets_length = tf.placeholder(tf.int32, [None], name='decoder_targets_length')self.max_target_sequence_length = tf.reduce_max(self.decoder_targets_length, name='max_target_len')self.mask = tf.sequence_mask(self.decoder_targets_length,self.max_target_sequence_length, dtype=tf.float32, name='masks')
定义encoder
with tf.variable_scope('encoder'): #创建LSTMCell,两层+dropout encoder_cell = self._create_rnn_cell() #构建embedding矩阵,encoder和decoder公用该词向量矩阵 embedding = tf.get_variable('embedding', [self.vocab_size, self.embedding_size]) encoder_inputs_embedded = tf.nn.embedding_lookup(embedding, self.encoder_inputs)# 使用dynamic_rnn构建LSTM模型,将输入编码成隐层向量。# encoder_outputs用于attention,batch_size*encoder_inputs_length*rnn_size,# encoder_state用于decoder的初始化状态,batch_size*rnn_szieencoder_outputs, encoder_state = tf.nn.dynamic_rnn(encoder_cell, encoder_inputs_embedded,sequence_length=self.encoder_inputs_length,dtype=tf.float32)
定义decoder在decoder阶段,我们仍然是定义了两种模式,一种是训练,一种是预测,在训练模式下,decoder的输入是真实的target序列,而在预测时,我们可以使用贪心策略或者是beam_search策略。
with tf.variable_scope('decoder'): encoder_inputs_length = self.encoder_inputs_length # if self.beam_search: # # 如果使用beam_search,则需要将encoder的输出进行tile_batch,其实就是复制beam_size份。 # print("use beamsearch decoding..") # encoder_outputs = tf.contrib.seq2seq.tile_batch(encoder_outputs, multiplier=self.beam_size) # encoder_state = nest.map_structure(lambda s: tf.contrib.seq2seq.tile_batch(s, self.beam_size), encoder_state) # encoder_inputs_length = tf.contrib.seq2seq.tile_batch(self.encoder_inputs_length, multiplier=self.beam_size) attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(num_units=self.rnn_size, memory=encoder_outputs, memory_sequence_length=encoder_inputs_length) #attention_mechanism = tf.contrib.seq2seq.LuongAttention(num_units=self.rnn_size, memory=encoder_outputs, memory_sequence_length=encoder_inputs_length) # 定义decoder阶段要是用的LSTMCell,然后为其封装attention wrapper decoder_cell = self._create_rnn_cell() decoder_cell = tf.contrib.seq2seq.AttentionWrapper(cell=decoder_cell, attention_mechanism=attention_mechanism, attention_layer_size=self.rnn_size, name='Attention_Wrapper') #如果使用beam_seach则batch_size = self.batch_size * self.beam_size。因为之前已经复制过一次 #batch_size = self.batch_size if not self.beam_search else self.batch_size * self.beam_size batch_size = self.batch_size #定义decoder阶段的初始化状态,直接使用encoder阶段的最后一个隐层状态进行赋值 decoder_initial_state = decoder_cell.zero_state(batch_size=batch_size, dtype=tf.float32).clone(cell_state=encoder_state) output_layer = tf.layers.Dense(self.vocab_size, kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1)) if self.mode == 'train': # 定义decoder阶段的输入,其实就是在decoder的target开始处添加一个
训练阶段对于训练阶段,需要执行self.train_op, self.loss, self.summary_op三个op,并传入相应的数据
def train(self, sess, batch):#对于训练阶段,需要执行self.train_op, self.loss, self.summary_op三个op,并传入相应的数据feed_dict = {self.encoder_inputs: batch.encoder_inputs,self.encoder_inputs_length: batch.encoder_inputs_length,self.decoder_targets: batch.decoder_targets,self.decoder_targets_length: batch.decoder_targets_length,self.keep_prob_placeholder: 0.5,self.batch_size: len(batch.encoder_inputs)}_, loss, summary = sess.run([self.train_op, self.loss, self.summary_op], feed_dict=feed_dict)return loss, summary
评估阶段对于eval阶段,不需要反向传播,所以只执行self.loss, self.summary_op两个op,并传入相应的数据
def eval(self, sess, batch):# 对于eval阶段,不需要反向传播,所以只执行self.loss, self.summary_op两个op,并传入相应的数据feed_dict = {self.encoder_inputs: batch.encoder_inputs,self.encoder_inputs_length: batch.encoder_inputs_length,self.decoder_targets: batch.decoder_targets,self.decoder_targets_length: batch.decoder_targets_length,self.keep_prob_placeholder: 1.0,self.batch_size: len(batch.encoder_inputs)}loss, summary = sess.run([self.loss, self.summary_op], feed_dict=feed_dict)return loss, summary
预测阶段infer阶段只需要运行最后的结果,不需要计算loss,所以feed_dict只需要传入encoder_input相应的数据即可
def infer(self, sess, batch):#infer阶段只需要运行最后的结果,不需要计算loss,所以feed_dict只需要传入encoder_input相应的数据即可feed_dict = {self.encoder_inputs: batch.encoder_inputs,self.encoder_inputs_length: batch.encoder_inputs_length,self.keep_prob_placeholder: 1.0,self.batch_size: len(batch.encoder_inputs)}predict = sess.run([self.decoder_predict_decode], feed_dict=feed_dict)return predict
-
Attention的具体原理详解2017-11-23 8508
-
深度学习模型介绍,Attention机制和其它改进2018-03-22 19533
-
将自注意力机制引入GAN,革新图像合成方式2018-05-25 18661
-
究竟Self-Attention结构是怎样的?2019-07-18 17882
-
基于BERT+Bo-LSTM+Attention的病历短文分类模型2021-04-26 1893
-
一种Attention-CNN恶意代码检测模型2021-04-27 1308
-
简述深度学习中的Attention机制2023-02-22 2850
-
计算机视觉中的注意力机制2023-05-22 751
-
详细介绍注意力机制中的掩码2023-07-17 1717
-
摩尔线程Round Attention优化AI对话2025-03-06 1256
全部0条评论

快来发表一下你的评论吧 !
