

像在word里一样便捷地编辑图像中的文字
电子说
描述
你想像编辑word文本一样便捷地编辑照片中的文字吗?像这样:
和这样:
让别人感觉不到任何人为编辑的迹象:
近日来自印度的研究人员们近日提出了一种基于自编码模型的字符替换方法,通过字符生成、颜色调节和重置完成对图像中目标文字的修改,并且能生成十分自然的图像,图像中被编辑过的文字毫无违和感。图片上的文字信息对于我们理解图片十分重要。字符的缺失和改变有的时候会严重的影响我们对于图像内涵的理解。除了会造成忍俊不禁的错别字,有时候还会让人们误解造成严重的损失!
另一方面,对于不同视角、环境下得到字符缺失的图片,如何进行有效的编辑和修复也是视觉领域一个重要的问题,甚至对于古文献修复和案件侦破都有着重要意义。
像编辑文本一样编辑图像中的文字
如果我们能够像文本编辑器一样编辑图像中的文字就好了。先前的人员提出过基于字符几何特征的合成方法,但却缺乏泛化性。但随着深度学习的发展,研究人员提出了利用GAN来进行字符生成,但基于GAN生成字符进行编辑的方法也需要面临一系列问题。首先基于GAN的生成需要对目标字符进行精确的识别,但字符识别本身就是一个复杂的问题,任何误差都会在整个过程积累十分有可能造成字符编辑的错误;其次,字符在同一张图像内具有多种字体类型,GAN模型需要对字体进行多次观察,并在生成前对字符进行较为严格的字体去失真过程,这对于不同情况下的字符编辑来说十分复杂。
所以研究人员聚焦字符级别的生成模型,来代替单词级别的生成模型最大化模型的灵活性和适应性。那么为了编辑图像中的文字,怎样才能又快又好呢?你需要四个步骤:定位到你要修改的字符、生成目标字符、调整目标字符的颜色、将字符融合回图像中去。这一工作的核心在于解决如何生成具有相同字体的目标字符,并为它赋予原字符相同的颜色风格。为此,研究人员提出了下图所示的FANet和ColorNet联合完成。
首先选取需要修改的字符,并利用算法将原字符转变为二值图像输入网络。FANet首先通过一个三层卷积和两次全连接将输入字符编码到512长度的向量上,其中包含了字体的风格信息。此外,目标字符的编码通过26个字符的独热编码转换到512维的编码上与先前得到的输入字符图像编码拼接得到1024维的隐空间编码。随后利用两个全连接和三次上采样最终得到与原字符相同风格的目标字符。但这时候的字符还没有颜色。那么就把原字符的颜色信息拿过来,继续进行处理。通过编码器解码器的结构,将原字符上的颜色信息迁移到了新字符上。最后对原图的对应区域进行背景去除,区域连续性处理,将得到的新字符放到合适的位置就可以得到修改后的图片了!来看看效果~~
这本jave书有点厉害!
看到这些图,你可能会觉得这些路标好像和上次看到的不一样了!
为了训练这个网络,研究人员们利用了谷歌字符库中的1000中字体,其中训练集中包含了67.6万个数据,验证集则有20.2万个数据。
最终的网络不仅可以编辑字符,同时还能由输入的单一字符生成出全部26个字母的新字体,下图中的的字体都是由一个输入字符生成出来的。
同样颜色也可以迁移,下图中的第二行表示输入字符的颜色,第三行就是将第二行的颜色迁移到第一行字符的结果。
中文字符
那么按道理,我们也可以开心的编辑照片中的汉字了。华中科技大学和旷视去年就提出了一篇可以生成各种风格汉字书法的工作,利用生成器和判别器实现了中文书法字符的合成。
这是文章中的网络结构:
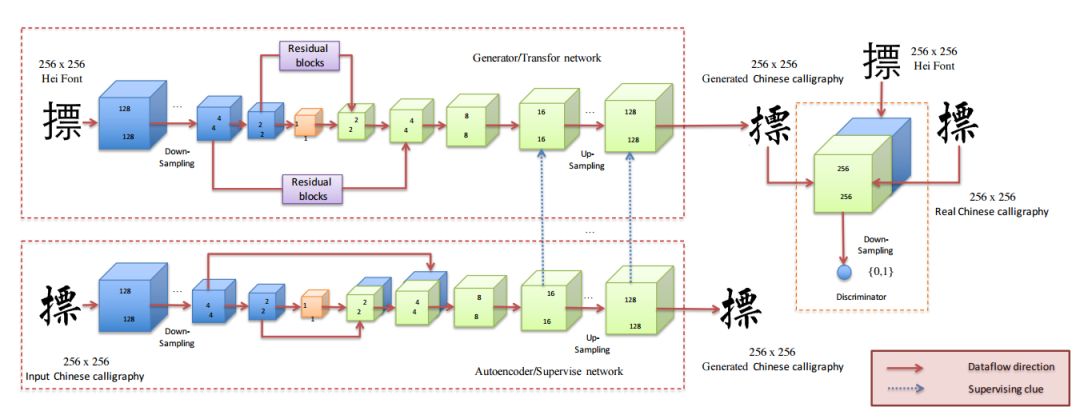
和最后得到的结果:
我们可以基于同样的思路将图像中的中文字符也进行转换,把照片中的汉字都变成优秀的书法作品啦。
-
请问在emwin TEXT控件里的文字可以更改吗?2023-11-06 568
-
有哪几种办法可实现单片机像在pc终端一样打印log呢2021-12-01 1416
-
Office Word新功能“微软编辑器”:检查并修正语法错误2020-12-24 4196
-
CAD图纸中的CAD文字复制到Word文档变成了黑色框怎么办?2020-01-20 3784
-
如何解决MathType中公式与文字错位的详细资料说明2019-05-30 2192
-
如何实现图片转Word文档2019-04-19 1841
-
请问怎么将WORD中的文字复制到虚拟机中Linux中的VI编辑器中?2019-03-27 7818
-
微软计划研究盲人VR导航系统,让盲人可以像在真实世界一样行走2018-08-02 2928
-
在Labview Communication Design System Suite中如何创建属性节点,就像在labview中右键创建属性节点一样?2018-02-03 2921
-
一年成为Emacs高手,像神一样使用编辑器2017-10-29 1343
-
pdf文件中的文字怎么进行编辑2017-07-10 2091
-
word按空格自动删除后面的文字2012-01-05 3537
-
Word篇文字录入技巧2009-03-10 3010
-
如何在Word中怎么样画电路图?2008-12-26 12323
全部0条评论

快来发表一下你的评论吧 !
