

ICML 2019评审结果来了!可谓是几家欢喜几家愁
电子说
描述
今天,机器学习顶会ICML 2019提交论文的评审结果出炉,可谓是几家欢喜几家愁。但网友们将更多关注点聚焦在评审机制和评审内容上,对ICML的评审结果狠狠的嘲讽了一番。
ICML 2019评审结果来了!
今天,机器学习顶会ICML的论坛可谓是炸了锅了——提交论文的作者们陆续收到了评审结果,可谓是几家欢喜几家愁。

根据网友提供的邮件截图,ICML官方描述如下:
现在,您可以查看ICML 2019提交的论文评审结果了。我们已经尽力保证每篇论文至少有3条评审结果,但是有一部分论文的评审结果可能少于3条。有一小部分论文可能会在未来一两天内陆续收到额外的评审,请在接下来的两天内查看更新情况。
但是很多作者们看到评审结果后,不禁跑到论坛上开始吐槽。Twitter网友Brandon Amos表示:

我ICML评审结果里的其中一条评论真的非常讽刺。审稿人用了几句极其错误的句子拒绝了我的论文,说我定义了|.|运算符仅用于设置基数,但在另一处用于绝对值。
而后网友Shuyu Lin跟帖表示:
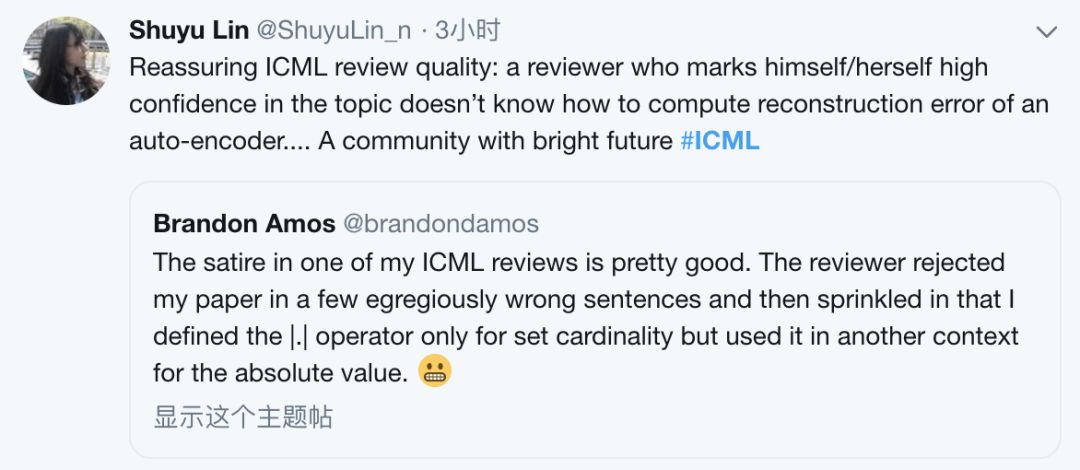
ICML评审质量令人放心:一位自称对自己高度自信的评论者不知道如何计算自动编码器的重构错误......一个前途光明的社区。
实力嘲讽?
当然,这种“热闹”话题怎么少得了Reddit用户。
网友MoreDonuts回复说:
我的论文有4个强烈接受(strong accept),评论者自称是“高度自信”,并且被推荐诺贝尔物理学奖、计算机科学奖和和平奖。你认为它有机会进入吗?
不。你至少需要一个“拒绝”。
该死,看来我该开始为NeurIPS修改论文了。
真可谓是满满的讽刺,足足的戏。
ICML 2019如何评审论文?
为何评审结果一出,便遭到了众网友的讽刺?我们先来看下ICML 2019的论文评审机制:
双盲评审
ICML 2019论文评议采用双盲模式; 即审稿人不知道作者的身份,作者也不知道审稿人身份。请尽可能以第三人称的方式引用自己之前的成果,请不要在提交的论文中添加致谢、以及公共github存储库链接。如果需要匿名引用,比如参考自己在其他地方正在评议中的成果,请将此成果作为补充材料上传。匿名是强制性要求,明确或隐含地揭示作者身份的论文可能会被拒稿。审稿人可以通过外部资源来推断出作者的身份,比如在网上发布的技术报告。这一点并不违反双盲审稿政策。
关于补充材料
本届ICML大会支持提交两种补充材料 - 补充论文和代码/数据,这些补充内容可用于提供额外证据支持。如果作者在论文中进行匿名引用,请务必上传参考文献,以便审稿人可以快速查看。请注意不要在补充材料中透露作者的身份。
关于代码提交,我们希望作者能够合理地以匿名形式提交代码和所在机构。即删除作者姓名和许可信息。ICML 2019允许通过匿名github存储库提交代码。但是,这些代码必须位于在提交截止日期后不可修改的目录中。请在提交的zip文件中的独立文本文件中输入github链接。
请注意,提交的论文必须完全独立。大会提倡审稿人查看作者提交的补充材料,但审稿人并没有此义务,我们也不希望给审稿人带来不必要的负担。作者不得利用辅助材料来延长论文长度。如果作者认为该材料对评估论文至关重要,则需要将其包含在论文中。补充材料可以zip文件或pdf格式提交。
补充材料不公布、不存档。如果要将其包含在论文的最终版本中,则必须将材料放在网站上,并在论文的最终版本中引用该网站。
审稿人匹配
为了找到适合作者提交论文的合适审稿人,我们将使用多伦多论文匹配系统(Toronto Paper Matching System)来进行协助筛选。
作为提交过程的一部分,作者需要允许使用“论文匹配服务”的许可,向ICML2019提交论文的作者应允许使用该服务。
关于一稿多投
提交与之前已发布或已接受的相同(或基本相似)的论文,或向其他会议同时提交相同论文是不合适的。此种行为违反了我们的一稿多投政策。
这个规则有几个例外:
允许提交已提交给期刊、但尚未在该期刊上发表的论文的精简版本。
作者有责任确保相关期刊允许向本会议同时提交相关论文。
下列情况下的论文允许提交:在未列入Proceeding的情况下,在会议或研讨会上提交或待提交的论文(例如ICML或NeurIPS研讨会),仅发表过摘要部分的论文。
曾作为技术报告提交的论文(或在arXiv中已提交的预印本)允许向本届ICML提交。在这种情况下,我们建议作者不要引用该报告,以保持匿名性。
论文作者对审稿意见的回复
目前暂定3月9日到3月14日期间,作者可以查看评议意见,并发表回复内容。
作者的回复的目的是改变审稿人对论文的判断,回复内容最长不超过5000个字符。论文的任何一位作者都可以输入/编辑作者回复,回复内容可以进行编辑或还原,直到截止日期为止。
论文审稿是双盲的。请勿在回复中包含可识别出作者/共同作者的任何信息。请勿在回复中包含任何网址。
作者在拟定回复内容时应该做好判断。没有必要对每个小问题或改进建议逐一回复。而应该将这些回复视作解决问题的好机会,比如针对审稿人对论文的某一点不确定、审稿人做出的错误假设、或者审稿人误解了论文中的某一部分等问题进行解释。我们建议在作者回复意见中保持礼貌和专业。
ICML 2018:接收率25%,两篇最佳论文回顾
机器学习顶会ICML 2018于7月10日~15日在瑞典首都斯德哥尔摩举办,2018年ICML共收到2473篇投稿论文,比2017年的1676篇增加了47.6%。最终入选的论文一共621篇,接收率25%。
ICML 2018最佳论文奖有两篇获奖论文,第一篇的作者分别是来自 MIT 的 Anish Athalye 以及来自UC Berkely 的 Nicholas Carlini 和 David Wagner,另一篇的作者则全部来自UC Berkely。
最佳论文一:
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Anish Athalye (MIT), Nicholas Carlini (UCB), David Wagner(UCB)
论文地址:https://arxiv.org/pdf/1802.00420.pdf

GitHub:github.com/anishathalye/obfuscated-gradients
基于神经网络的分类器通常被用于图像分类,它们的水平通常接近人类。但是,这些相似的神经网络特别容易受到对抗样本和细微的干扰输入的影响。下图是一个典型的对抗样本,对原图增加一些肉眼看不见的扰动后,InceptionV3分类器把猫分类成了鳄梨酱。根据Szegedy等人2013年的研究显示,这种“愚蠢的图像”仅用梯度下降法就能合成,这类发现为物体检测研究敲响了警钟。
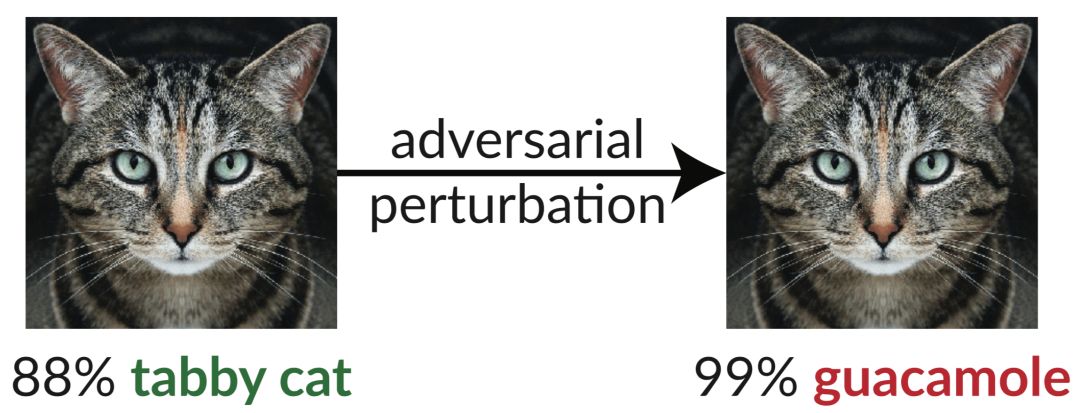
在这篇论文中,作者评估了ICLR 2018接受的9篇论文,并测试了它们面对对抗样本的稳健性。实验结果证实,在8篇有关对抗样本的防御机制的论文中,有7篇的防御机制都抵挡不住论文提出的新型攻击技术,防御水平有限。
最佳论文二:
Delayed Impact of Fair Machine Learning
Lydia Liu, Sarah Dean, Esther Rolf, Max Simchowitz, Moritz Hardt (全员UCB)
论文地址:https://arxiv.org/pdf/1803.04383

博客:bair.berkeley.edu/blog/2018/05/17/delayed-impact/
机器学习的基础理念之一是用训练减少误差,但这类系统通常会因为敏感特征(如种族和性别)产生歧视行为。其中的一个原因可能是数据中存在偏见,比如在贷款、招聘、刑事司法和广告等应用领域中,机器学习系统会因为学习了存在于数据中的历史偏见,对现实中的弱势群体造成伤害,因而受到批评。
那么,你对于今年的评审结果,还算满意吗?
-
半导体大厂Q1财报,几家欢喜几家愁!2020-05-11 5801
-
国内20家MCU上市公司今年上半年表现:几家欢喜几家愁2022-09-13 6572
-
智能照明浪潮起,几家欢喜几家愁?2016-04-01 1467
-
四大通信设备厂商发布成绩单,几家欢喜几家愁2018-04-10 29174
-
五分钟看完IIHS乘客侧25%偏置碰撞测试,结果几家欢喜几家愁2018-07-19 19226
-
50家锂电板块企业业绩预报出炉,几家欢喜几家愁2019-07-21 3308
-
苹果、三星、英特尔、索尼、松下二季度财报公布 几家欢喜几家忧!2019-08-02 9194
-
业绩公告:麦捷科技2019上半年业绩预告不甚理想2019-08-08 4017
-
2020年互联网行业又会有几家欢喜几家愁呢?2020-01-03 3123
-
蕴藏万亿市场空间的物联网,几家欢喜几家愁2020-02-03 2594
全部0条评论

快来发表一下你的评论吧 !
