

大疆、港科大联手!双目3D目标检测实验效果大放送
电子说
描述
CVPR 2019的文章出来了,今天聊聊双目的 3D object detection。这是一篇来自 DJI (大疆)与港科大合作的文章《Stereo R-CNN based 3D Object Detection for Autonomous Driving》,作者分别是 Peiliang Li,陈晓智(DJI,MV3D的作者)和港科大的 Shaojie Shen 老师。

论文链接,文中称代码将开源
https://arxiv.org/abs/1902.09738
1. Introduction
2018 年在 3D 检测方面的文章层出不穷,也是各个公司无人驾驶或者机器人学部门关注的重点,包含了点云,点云图像融合,以及单目 3D 检测,但是在双目视觉方面的贡献还是比较少,自从 3DOP 之后。
总体来说,图像的检测距离、图像的 density 以及 context 信息,在 3D检测中是不可或缺的一部分,因此作者在这篇文章中挖掘了双目视觉做 3D检测的的潜力。
2.Network Structure
整个网络结构分为以下的几个部分。
1). RPN部分,作者将左右目的图像通过stereoRPN产生相应的proposal。具体来说stereo RPN是在FPN的基础上,将每个FPN的scale上的feature map的进行concat的结构。
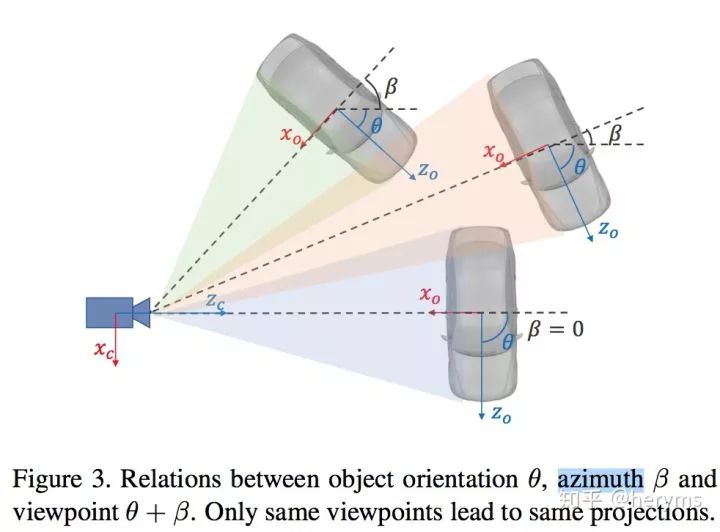
2). Stereo Regression,在RPN之后,通过RoiAlign的操作,得到each FPN scale下的left and right Roi features,然后concat相应的特征,经过fc层得到object class, stereo bounding boxes dimension还有viewpoint angle(下图所示) 的值。这里解释一下viewpoint,根据Figure3.,假定物
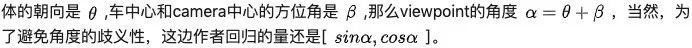
3). keypoint的检测。这里采用的是类似于mask rcnn的结构进行关键点的预测。文章定义了4个3D semantic keypoint,即车辆底部的3D corner point,同时将这4个点投影到图像,得到4个perspective keypoint,这4个点在3D bbox regression起到一定的作用,我们在下一部分再介绍。
在keypoint检测任务中,作者利用RoiAlign得到的14*14feature map,经过conv,deconv最后得到6 * 28 * 28的feature map,注意到只有keypoint的u坐标会提供2D Box以外的信息,因此,处于减少计算量的目的,作者aggregate每一列的feature,得到6 * 28的output,其中,前4个channel代表4个keypoint被投影到相应的u坐标的概率,后面两个channel代表是left or right boundary上的keypoint的概率。
3. 3D Box Estimation
通过网络回归得到的 2D box 的 dimension,viewpoint,还有 keypoint,我们可以通过一定的方式得到3D box的位置。定义 3D box 的状态x = [x, y, z, θ]。
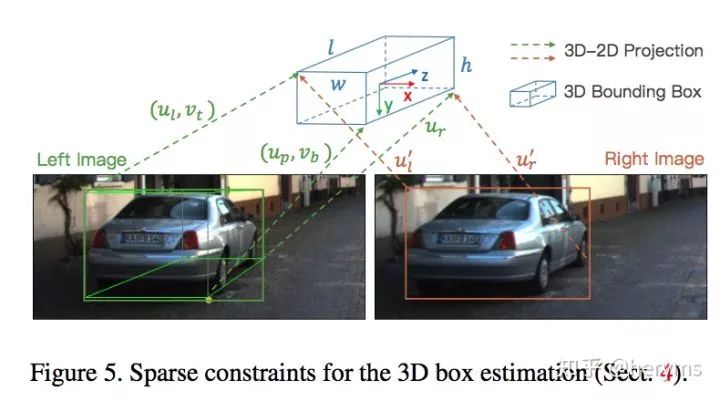
Figure 5,给出了一些稀疏的约束。包含了特征点的映射过程。这里也体现了keypoint的用处。
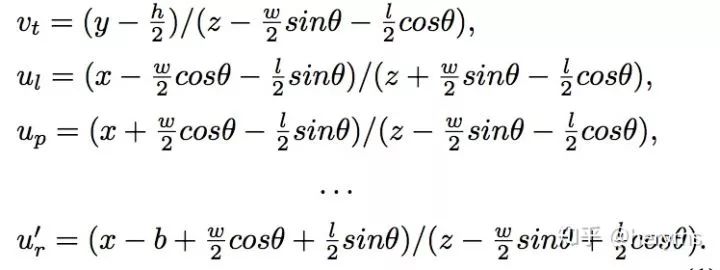
上述公式即为约束方程,因此可以通过高斯牛顿的方法直接求解。具体可以参考论文的引文17。这里我们简单证明一下第一个公式。注意,这里的假设都是u,v坐标都已经经过相机内参的归一化了。

4. Dense 3D Box Alignment
这里就回到shenshaojie老师比较熟悉的BA的过程了,由于part 3仅仅只是一个object level的深度,这里文章利用最小化左右视图的RGB的值,得到一个更加refine的过程。定义如下的误差函数
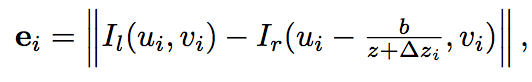
求解可以利用G20或者ceres也可以完成。整个alignment过程其实相对于深度的直接预测是更加robust的,因为这种预测方法,避免了全局的depth estimation中的一些invalid的pixel引起的ill problem的问题。
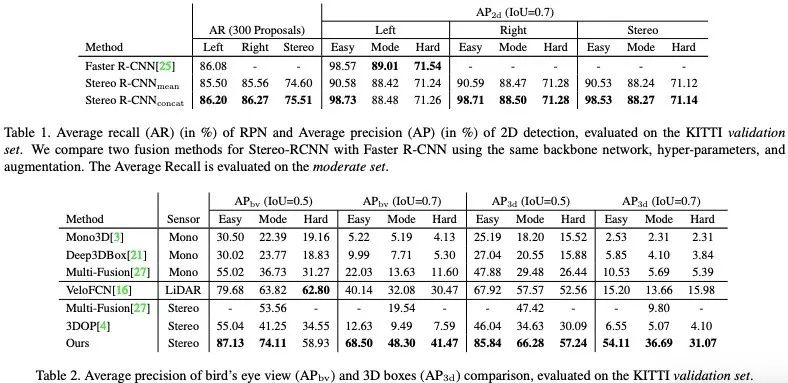
5. experiment
作者在实验这块达到了双目视觉的state-of-the-art,同时对于各个module也做了很充足的实验(这块请查看原论文)。
下面是图a、b、c为处理结果示例,每幅图像内部上中下三部分,分别为左眼图像检测结果、右眼图像检测结果、鸟瞰视图检测结果。
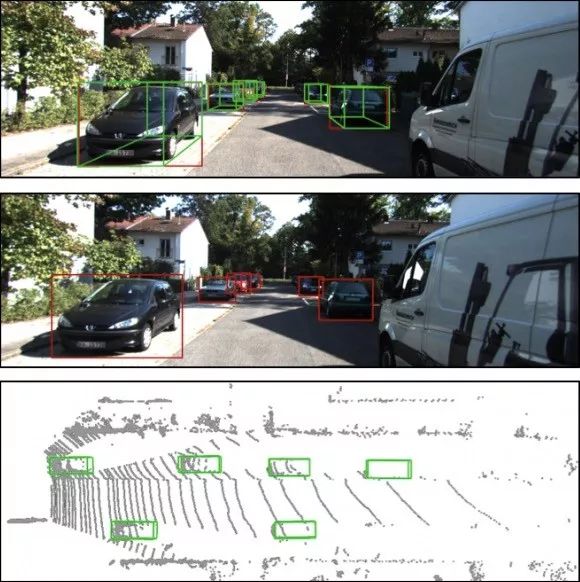
图a

图b
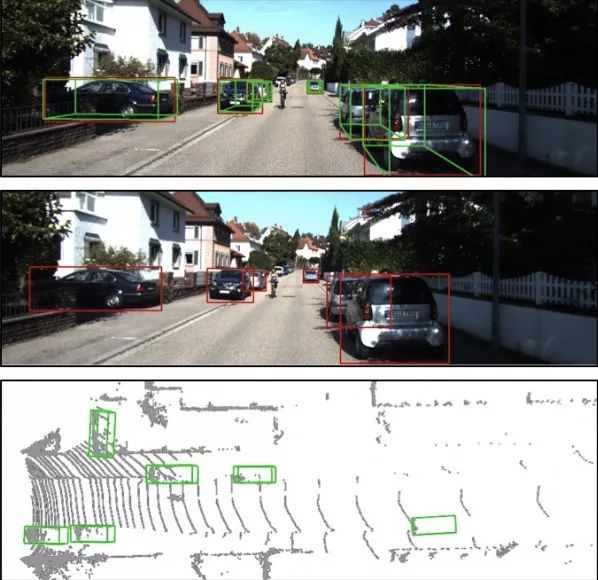
图c
6. Insight
最后谈谈文章给我的一些 insights,首先,整个文章将传统的 detection 的任务,结合了 geometry constraint 优化的方式,做到了3D位置的估计,想法其实在不少文章sfm-learner之类的文章已经有体现过了,不过用在3Ddetection上面还是比较新颖,避免了做双目匹配估计深度的过程。也属于slam跟深度学习结合的一篇文章,感兴趣的朋友可以继续看看(下面链接)相关文章
arxiv.org/abs/1802.0552
谈几点我个人意义上的不足吧,首先耗时过程 0.28s 的 inference time,不过可能作者的重点也不在这个方面,特征的利用上可以更加有效率,在实现上。其次,能不能采用deep3dbox的方式预测dimension,然后添加入优化项呢...总体来说,是一篇不错的值得一读的文章!
-
[原创]手机方案资料免费大放送啦2010-06-10 3305
-
超值大放送学习MSP430必看的几本书2012-11-22 71959
-
快来啊,DSP大放送啦2013-09-06 5583
-
MSP430单片机入门学习资料大放送2014-03-24 64494
-
周末大放送之STM32篇! 2014-05-31 更新!2014-04-27 26008
-
周末大放送之电子硬件篇!2014--04--28!2014-04-28 3398
-
竞赛小车资料豪华大放送2015-02-11 4571
-
vivado资料大放送2016-09-09 11939
-
传感器资料大放送2016-10-07 4370
-
DSP28335资料大放送2016-11-11 14982
-
FPGA学习资料大放送(不断更新)2017-04-25 22101
-
Windows Server2003秘笈大放送2010-01-30 938
-
MWC 2023 | 华为AntiDDoS明星产品精彩大放送2023-03-11 966
-
C语言小游戏源码大放送2023-11-21 657
-
如何搞定自动驾驶3D目标检测!2024-01-05 1267
全部0条评论

快来发表一下你的评论吧 !
