

来看看Spark和Flink各自的优劣和主要区别
电子说
描述
2018和2019年是大数据领域蓬勃发展的两年,自2019年伊始,实时流计算技术开始步入普通开发者视线,各大公司都在不遗余力地试用新的流计算框架,实时流计算引擎Spark Streaming、Kafka Streaming、Beam和Flink持续火爆。
最近Spark社区,来自Databricks、NVIDIA、Google以及阿里巴巴的工程师们正在为Apache Spark 3.0添加原生的GPU调度支持,参考(SPARK-24615和SPARK-24579)该方案将填补了Spark在GPU资源的任务调度方面的空白,极大扩展了Spark在深度学习、信号处理的应用场景。
与此同时,2019年1月底,阿里巴巴内部版本Blink正式开源!一石激起千层浪,Blink开源的消息立刻刷爆朋友圈,整个大数据计算领域一直以来由Spark独领风骚,瞬间成为两强争霸的时代。那么未来Spark和Blink的发展会碰撞出什么样的火花?谁会成为大数据实时计算领域最亮的那颗星?
我们接下来看看Spark和Flink各自的优劣和主要区别。
底层机制
Spark的数据模型是弹性分布式数据集 RDD(Resilient Distributed Dattsets),这个内存数据结构使得spark可以通过固定内存做大批量计算。初期的Spark Streaming是通过将数据流转成批(micro-batches),即收集一段时间(time-window)内到达的所有数据,并在其上进行常规批处,所以严格意义上,还不能算作流式处理。但是Spark从2.x版本开始推出基于 Continuous Processing Mode的 Structured Streaming,支持按事件时间处理和端到端的一致性,但是在功能上还有一些缺陷,比如对端到端的exactly-once语义的支持。
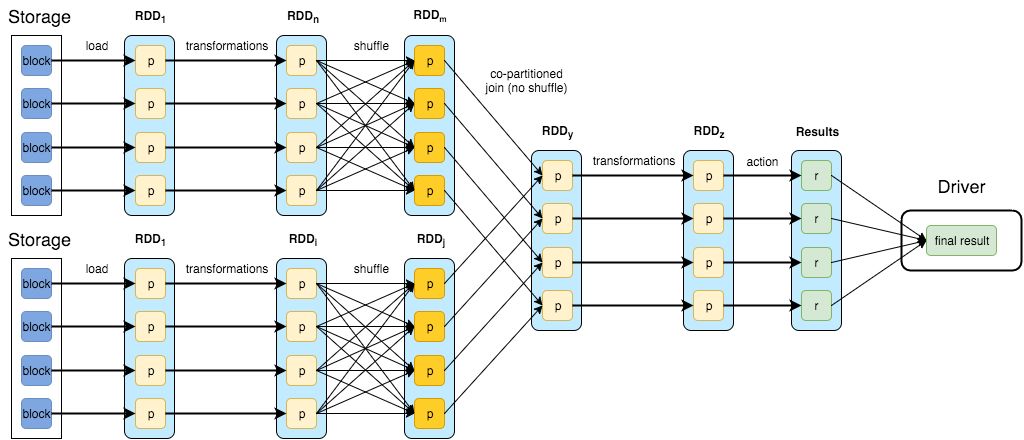
一个典型的Spark DAG示意图
Flink是统一的流和批处理框架,基本数据模型是数据流,以及事件(Event)的序列,Flink从设计之初秉持了一个观点:批是流的特例。每一条数据都可以出发计算逻辑,那么Flink的流特性已经在延迟方面占得天然优势。
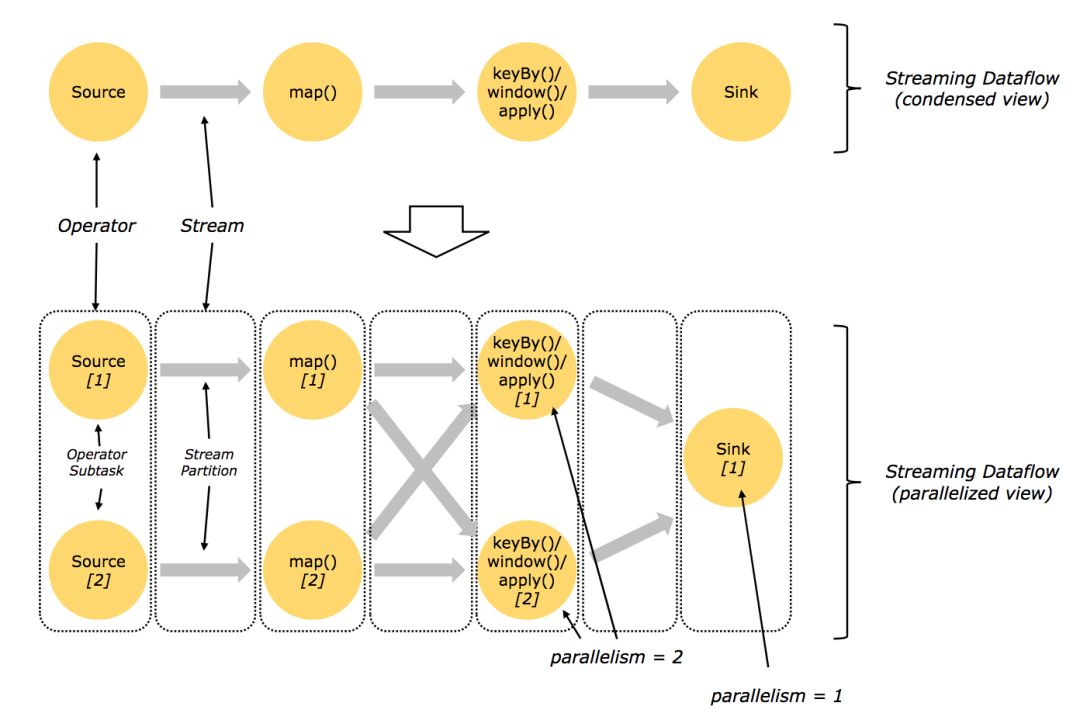
一个典型的Flink workflow示意图
Flink还提供了一个独特的概念叫做有状态的计算,它被用来处理一种情况:数据的处理和之前处理过的数据或者事件有关联。比如,在做聚合操作的时候,一个批次的数据聚合的结果依赖于之前处理过的批次。早期的Spark用户会经常受此类问题所困扰,直到Structured Streaming的出现才得已解决。
Flink从一开始就引入了state的概念来处理这种问题。为状态计算提供了一个通用的解决方案。
周边生态
在大数据领域,任何一个项目的火爆都被离不开完善的技术栈,Spark和Flink都基于对底层数据和计算调度的高度抽象的内核上开发出了批处理,流处理,结构化数据,图数据,机器学习等不同套件,完成对绝大多数数据分析领域的场景的支持,意图统一数据分析领域。
Flink和Spark都是由Scla和Java混合编程实现,Spark的核心逻辑由Scala完成,而Flink的主要核心逻辑由Java完成。在对第三方语言的支持上,Spark支持的更为广泛,Spark几乎完美的支持Scala,Java,Python,R语言编程。
Spark周边生态(图来源于官网)
与此同时,Flink&Spark官方都支持与存储系统如HDFS,S3的集成,资源管理/调度Yarn,Mesos,K8s等集成,数据库Hbase,Cassandra,消息系统Amazon,Kinesis,Kafka等。
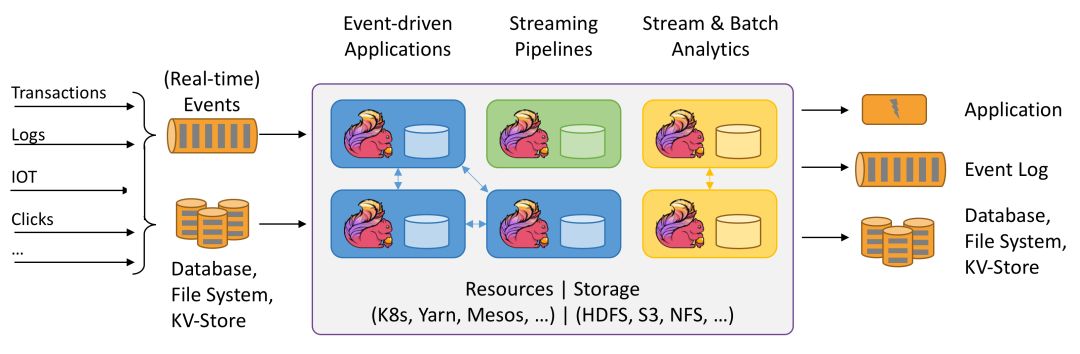
Flink周边生态(图来源于官网)
在最近的Spark+AI峰会上,Databricks公司推出了自己的统一分析平台(Unified Analytics Platform),目标是使户在一个系统里解决尽可能多的数据需求。Flink的目标和Spark一致,包含AI的统一平台也是Flink的发展方向,从技术上来看,Flink是完全有能力支持对机器学习和深度学习的集成,但目前来看,Flink仍有很长的路要走。
未来趋势
2018年是机器学习和深度学习元年,ML在数据处理领域占比越来越重。Spark和Flink在做好实时计算的同时,谁能把握住这次机会就可以在未来的发展中占得先机。另外随着5G的发展,网络传输不再是瓶颈之时,IOT的爆发式发展也将会是实时计算需求爆发之时,届时Flink在流式计算中的天然优势将发挥的淋漓尽致,Blink的开源和阿里巴巴对Blink的加持无疑又给Flink未来的发展注入一针强心剂。
总结
Spark和Flink发展至今,基本上已经是实时计算领域的事实标准。两者在易用性和生态系统建设上都投入了大量的资源,是现在和未来一段时间内大数据领域最有有力的竞争者。二者的发展是竞争中伴随着互相促进,在与机器学习集成和统一处理平台的建设上双方各有优劣,谁能尽早补齐短板就会在未来的发展中占得优势。对于普通大数据领域的开发者而言,当下也是最好的时代,可以见证两大数据引擎的蓬勃发展,除了学习别无选择,这何尝不是是一种幸运?
-
请问AD9162和AD9164的主要区别是什么?2018-08-06 6140
-
hadoop和spark的区别2018-11-30 2980
-
USART和UART的主要区别2021-08-16 2249
-
HDL语言中的unsigned与signed的主要区别是什么2021-09-24 2200
-
PLC的信号板和信号模块的主要区别是什么?2023-04-17 1764
-
树莓派和51单片机的主要区别是什么?2023-11-01 770
-
STM8L和STM8S的主要区别是什么?2023-11-02 578
-
AD9162和AD9164的主要区别是什么?2023-12-11 560
-
AMOLED与OLED的主要区别2016-10-25 1399
-
unpacked数组和packed数组的主要区别2022-10-18 4056
-
NTC与PTC的主要区别和应用2023-02-06 9350
-
步进电机和伺服电机的主要区别2023-08-21 3684
-
DCS系统与PLC系统的主要区别2024-06-06 3644
-
无刷电机和有刷电机的主要区别2024-06-07 8071
-
dwdm与wdm的主要区别2024-07-18 2556
全部0条评论

快来发表一下你的评论吧 !
