

Facebook开源服务27亿用户的硬件3件套
电子说
描述
面对每个月27亿活跃用户产生的数据量,Facebook将重心从通用硬件转向AI专用硬件。在今天的开放计算项目全球峰会上,发布并开源了3款AI硬件,分别是面向训练的Zion、面向推理的Kings Canyon及面向视频转码的Mount Shasta。
一个全家桶app,每个月要服务27亿人,不容易呐!不信你问Facebook。
为了应对大量的算力要求,这家位于Menlo Park的技术巨头,硬是从通用硬件转移到了专用加速器。这些加速器的作用,是保证其数据中心的性能,功耗和效率,特别是在AI领域。
今天,Facebook一口气推出了3款硬件产品,分别是用于AI模型培训的“下一代”硬件平台Zion;以及针对AI推理优化的定制专用集成电路Kings Canyon;以及视频转码Mount Shasta。并捐赠给旗下的开放计算项目使用。
Open Compute Project(OCP)是Facebook在2011年4月发起的一個数据中心开放架构技术发展组织,目前成员包括Intel、Red Hat、Facebook、Mozilla、Rackspace、NTT Data、百度、高盛以及Google等。https://benchlife.info/8597-2/
Facebook称这三款硬件产品将大大加速AI的训练和推理。“人工智能用于各种服务,以帮助人们进行日常互动,并为他们提供独特的个性化体验,” Facebook工程师Kevin Lee,Vijay Rao和William Christie Arnold在博客文章中写道,“在整个Facebook的基础设施中使用人工智能工作负载,能够增强各服务之间的相关性,并改善我们的用户体验。”
Zion
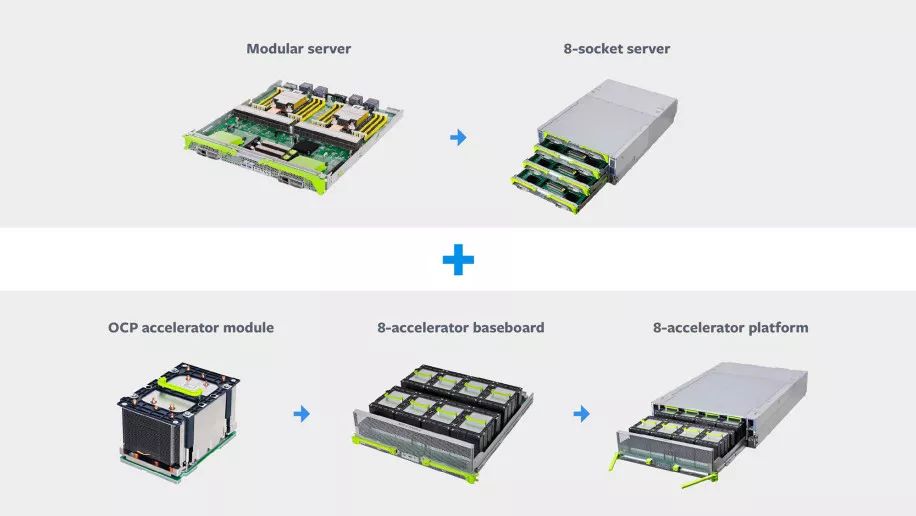
Zion为AI训练创建Block
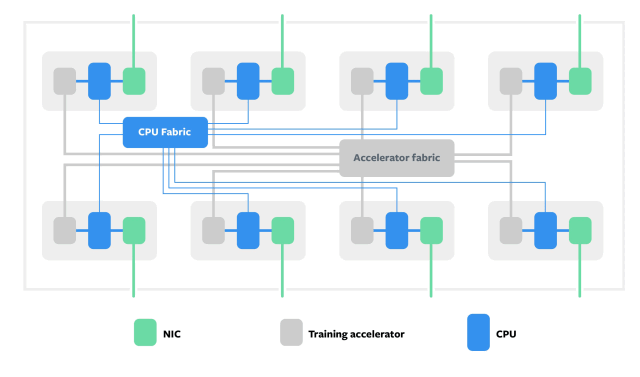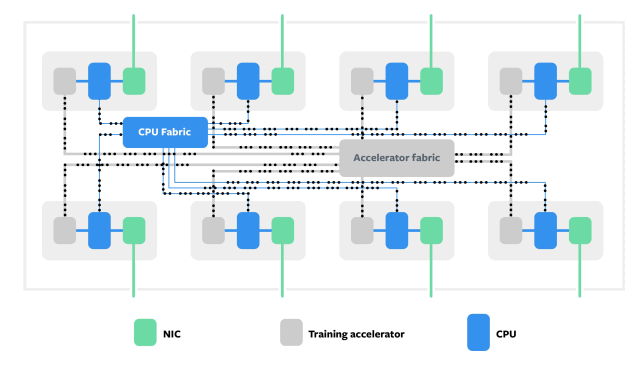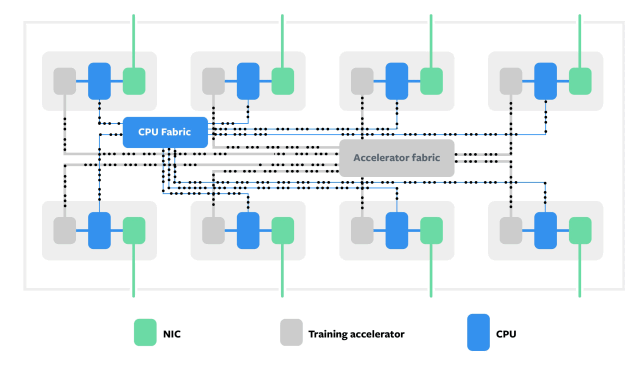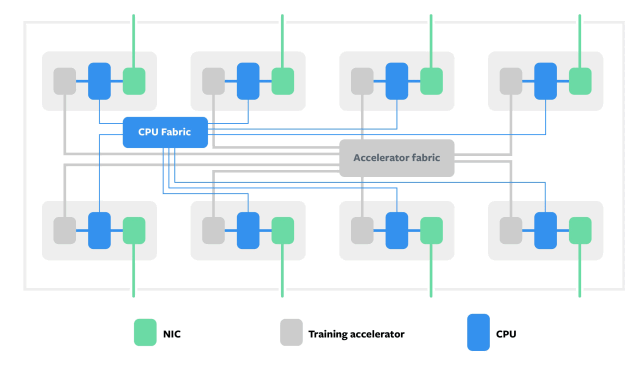
和Block之间通信
Zion专为处理包括CNN,LSTM和SparseNN在内的神经网络架构的“频谱”而量身定制。包括三个部分:拥有8个NUMA CPU插槽的服务器;配备了8加速器芯片组,以及一个厂商中立(vendor-agnostic )的OCP加速器模块(OAM)。
Zion的高内存容量和高带宽,得益于两个高速fabric,一个用来连接所有的CPU,另一个用来连接所有的加速器。除此之外,还得益于其灵活的架构,可以使用顶部扩展到单个机架中的多个服务器机架式(TOR)网络交换机。
“加速器内存带宽高但容量低,所以我们通过对模型进行分区来解决这个问题:将频繁访问的数据驻留在加速器上,而访问频率较低的数据驻留在带有CPU的DDR内存里,“Lee,Rao和Arnold解释道,“所有CPU和加速器的计算和通信都是平衡的,并通过高速和低速互连,极大地提高了效率。”
Kings Canyon
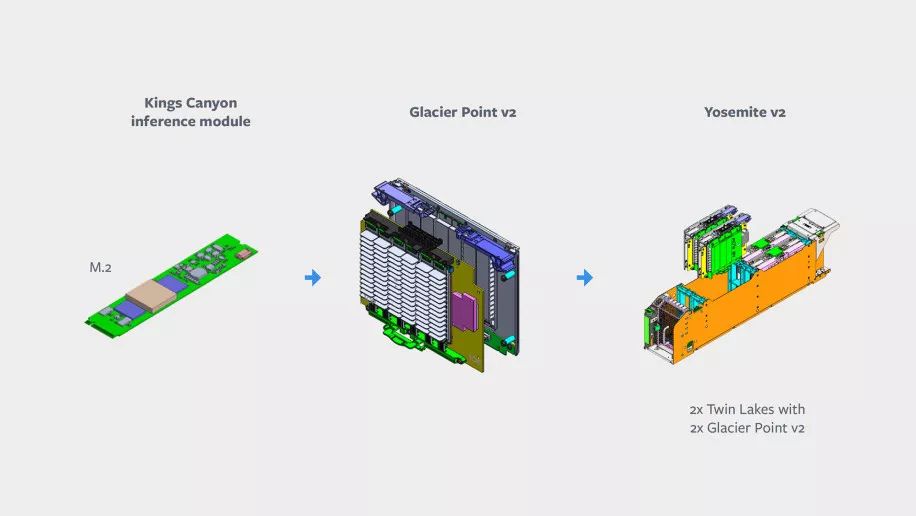
Zion为AI推理创建Block
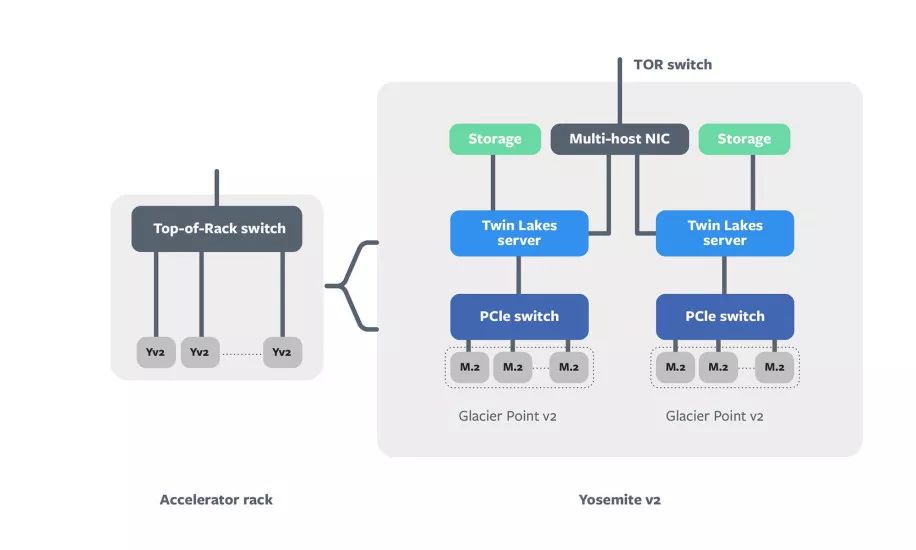
和Block之间通信
至于专为推理任务而设计的Kings Canyon共分四个部分:Kings Canyon推理M.2模块;Twin Lakes单插槽服务器;Glacier Point v2载卡;以及Facebook的Yosemite v2机箱。Facebook表示正在与Esperanto、Habana,英特尔,Marvell和高通公司合作,开发能够同时支持INT8和高精度FP16工作负载的ASIC芯片。
ASIC不运行通用代码,需要专门的编译器将图形转换为在这些加速器上执行的指令。Glow编译器的目标是从更高级别的软件堆栈中抽象出特定于供应商的硬件,以使基础架构与供应商无关。它接受来自PyTorch 1.0等框架的计算图,并为这些ML加速器生成高度优化的代码。
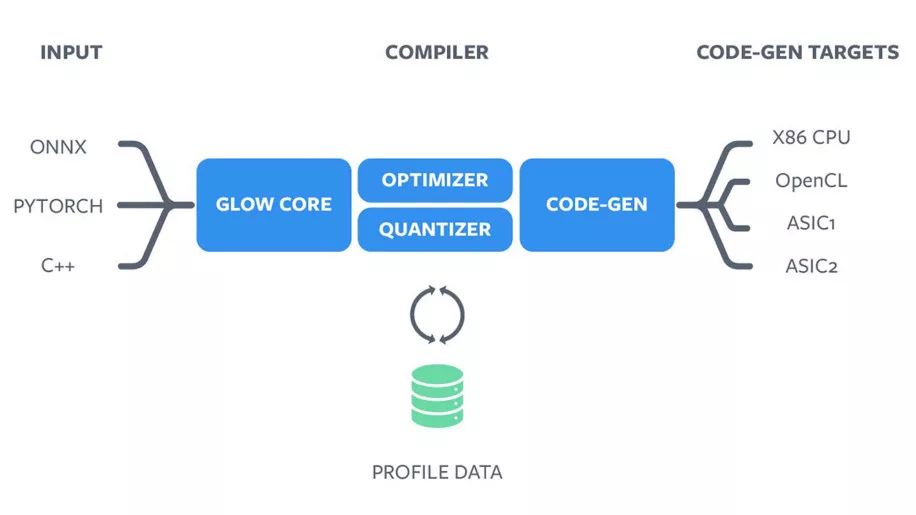
Glow编译器
Kings Canyon中的每台服务器都结合了M.2 Kings Canyon加速器,以及一个连接Twin Lakes服务器的Glacier Point v2载卡。其中两个被安装到Yosemite v2 sled中,并通过NIC链接到TOR开关。Kings Canyon模块包括一个ASIC,一个内存及其他支持组件,比如通过PCIe通道与加速器模块通信的CPU。而Glacier Point v2包含一个集成的PCIe交换机,允许服务器同时访问所有模块。
“通过适当的将模型进行分割,我们得以运行非常大的深度学习模型。例如,对于SparseNN模型,如果单个节点的内存容量不够用,就在两个节点之间对模型进行分片,从而增加模型可用的内存量。“Lee,Rao和Arnold说过,“这两个节点通过多主机NIC连接,允许高速交换。”
Mount Shasta
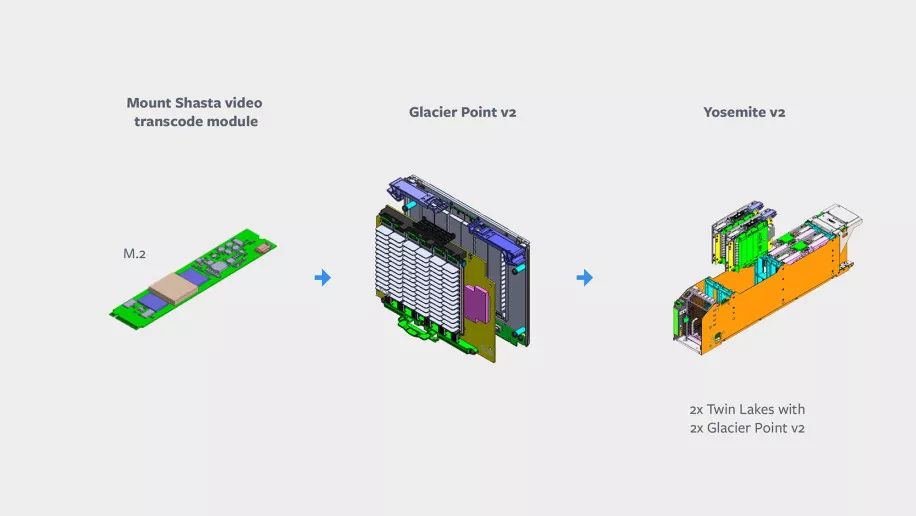
Mount Shasta是与Broadcom和Verisilicon合作开发的ASIC,专为视频转码而开发。在Facebook的数据中心内,它将被安装在带有集成散热器的M.2模块上,位于可容纳多个M.2模块的Glacier Point v2(GPv2)载板中。
Facebook表示,平均而言,预计这些芯片的效率会比目前的服务器“高出许多倍”。它的目标是在10W功率范围内,以60fps速度输入流编码效率至少比4K高出一倍。
“我们希望Zion、Kings Canyon和Mount Shasta的设计,能够满足我们在AI训练、AI推理和视频转码方面不断增长的工作量。”Lee,Rao和Arnold写道,“我们将采取硬件和软件协同设计,不断改进硬件产品的效率。但一家厂商的能力终归有限,希望更多的厂商都能够进入Facebook的生态中,共同努力。“
-
施耐德电气机器运动控制“黄金四件套”整体解决方案全面推向市场2026-01-06 602
-
福禄克过程校验仪器三件套助力高效维护2025-08-22 1370
-
医用IT系统绝缘监测及故障定位产品 (七件套)2023-07-13 2027
-
芯动科技高性能计算“三件套”IP解决方案行业领先,满足新一代SoC带宽需求2022-10-09 1778
-
新手求助modbus RTU调试四件套是什么呢2021-12-24 1507
-
手机QQ更新到 群聊三件套2020-11-19 2890
-
苹果发布全新 iWork 办公三件套:精致新设计,针对 macOS Big Sur2020-11-13 2779
-
亚为LabVIEW虚拟仪器八件套的详细资料合集免费下载2020-03-31 1319
-
七旬独居老人的“居家安防5件套”2020-02-28 4018
-
Facebook后台背后的技术2019-07-17 4124
-
Facebook背后的软件揭秘2019-07-16 2824
-
看看俄罗斯反无人机的三件套2018-12-10 5762
-
Facebook和Messenger Stories的日活跃用户已合计突破3亿大关2018-09-29 3738
-
英特尔将推数据中心节能芯片 获Facebook认可2012-12-12 2733
全部0条评论

快来发表一下你的评论吧 !
