

拓展可能 向世界问好 联想栗子板初评
嵌入式技术
描述
2018年末,联想推出了一种基于TI AM5708芯片的SBC,名字叫栗子板(派)。与树莓派一样,栗子板也是只有信用卡一样大,但是麻雀虽小五脏俱全。最近,机缘巧合下,本人也有幸得到了一块栗子板。
栗子板的计算处理芯片是TI的AM5708,这是款单核ARM Cortex A15处理器。大家都知道,虽然A15是款很多年前出的32位的老内核,但是实际上,它的浮点性能要高于近年的64位的A53内核。
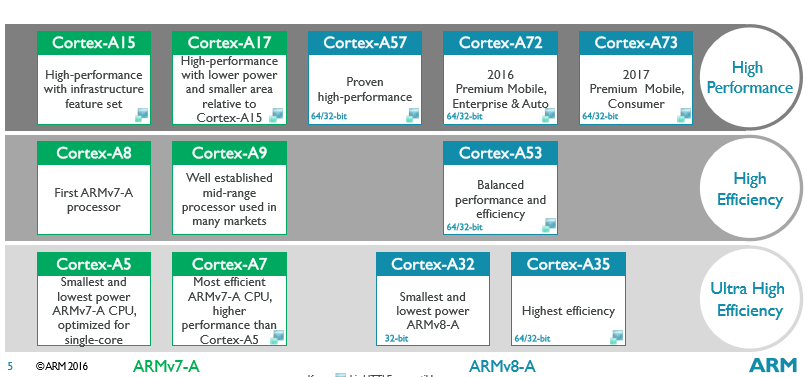
当然,对于传统的A15核心的处理器芯片来说,由于要跑Linux,在一些需要较高时间精度的工控场景中还是有些力不从心的;这时候就需要在应用场景中再增加一片独立的微控制器(MCU)了。不过,对于AM5708来说,这都不是事儿!
在实时控制的应用场景中,这款AM5708芯片有一个大大的亮点,就是集成了Cortex M4内核,作为Cortex A15的协处理器,弥补了IO输出的实时性能。这种实时性能,在做小计算量的信号处理时候也能体现,Cortex M4内部也是集成了浮点计算单元的。
另一方面,在需要大计算量的实时信号处理的应用场景中,这款AM5708芯片又有另一个亮点,就是集成了C66DSP核心,其浮点性能要好于Cortex-M4或Cortex-A15内部集成的浮点单元。
唠了半天的嗑了,相信大家已经迫不及待地想要实机玩玩啦。不管是骡子是马,赶紧拉出来遛儿啊!我们这就把电源线和网线接上(其中,供电线是USB Type-C接口)。
上电以后,发现联想的代码小哥哥贴心地帮我们预装了Linux操作系统(可以!这很Lenovo);默认已开启SSH服务,并且root密码为空,让我们入手测试更加便利。大家可以通过passwd命令自己设置个喜欢的密码。
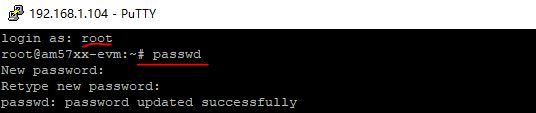
以上这步看似很简单,但是也充分体现了代码小哥哥对我们的关怀;因为SSH登录的前提是网卡开机启动并开启DHCP,SSH服务也设置为开机启动,防火墙关闭或打开22端口。
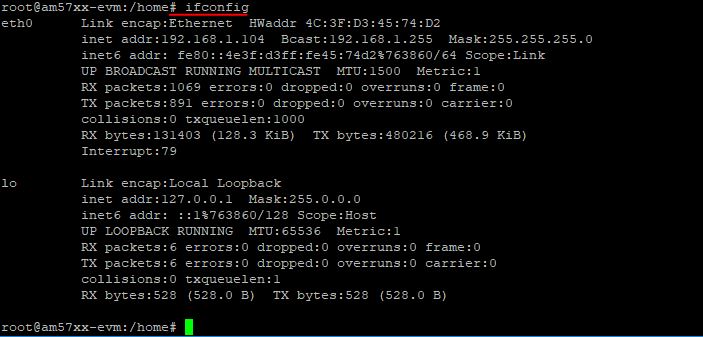
我们顺便看看网卡的MAC和IP吧,命令是ifconfig。这个命令的前提是已经安装了net-tools,再次感谢一下贴心的代码小哥!
如果net-tools没有安装,要查看网卡信息也是可以的;不过需要通过ip addr命令来实现。
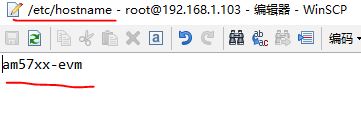
通过hostname命令,我们可以查看电脑名。

Hostname的修改位置在下图左上角的红线所示的目录里,你也可以把图片靠近中部的红线标记的字符串改成你喜欢的名字。
查看系统内核信息的方法,本人至少可以想到两种,如下图红线标记处所示。一种是通过uname命令输出;另一种是用cat命令把内核信息的文件打印到终端上。

查看etc目录的设置文件时,我偶然地看到了一个有趣的文件夹,从名字意思上判断,里面放置的是某种可视化脚本。本人比较好奇地把它点开了,但是发现里面的脚本都没有执行权限;于是我自(no)作(zuo)主(no)张(die)地给添加上了执行权限,编号是755。我好奇地执行了一下其中一个字面意思是输出温度的脚本,但是运行结束以后啥也没有输出。当然,板子也没有BOOM。
于是我更加好奇地把脚本文件打开了。一看,原来是脚本里面漏写了输出语句。
然后,顺理成章地,我把这个脚本修改了一下,如下图所示。其中,图片左上角红线标记了脚本文件所在路径,中下部的各条红线标记了我添加的那几个输出语句。
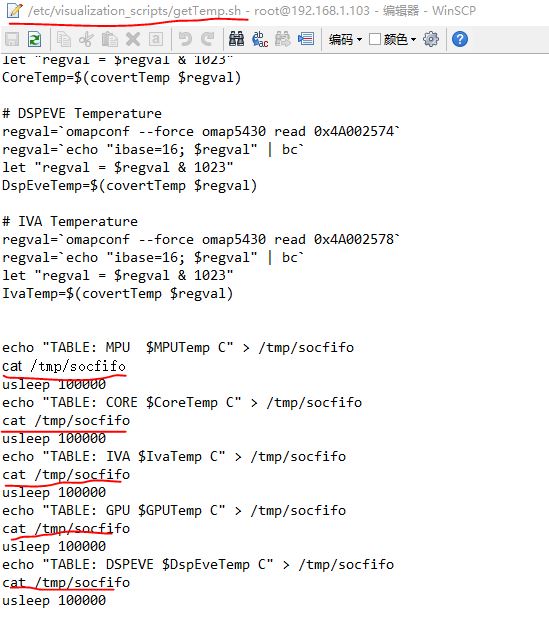
执行一下这个脚本,成功输出温度了。
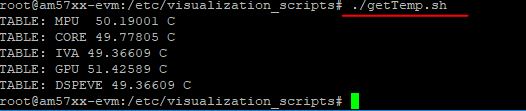
您也许会发现处理器温度的数值,看上去略微有些高。毕竟在室温约25度的情况下,带着散热片,都达到了近50度。
但是大家请不要方。
毕竟,这是款汽车级处理器啊!
它具有很广的许用温宽(-40~125摄氏度)。值得一提的是,这个125摄氏度并不是存放温度,而是实实在在的带电工作的许用温度,并且已经考虑安全余量了。因此,50度完全在安全裕度内!
接下来,想必大家很想看看栗子板在跑实际项目时候的性能,比如您自编的C语言程序。我在测试各种板子时候,写过不少有趣的代码;虽然都只是些花拳绣腿,但是用来做评测是够用了的。这些代码都被共享在我的开源页面上了。
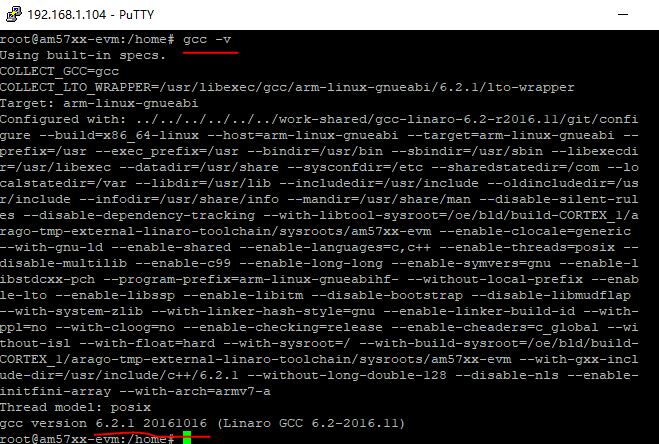
栗子板已经安装了C语言编译器,可以用gcc -v命令查看编译器版本。如果你想要编译CPP代码,可以用G++,也已经装上了。
我们的第一个测试代码是内存写入速度测试。
测试前先用free -m命令看一下内存使用情况。别一下子来个1GB的写入然后就给撑爆了哈!

上图中,我们发现,可以使用的内存大约是685MB。那就取个整,来个100MB的写入测试吧。,
于是,我们写了个代码,先测试了单线程的写入100MB并记录写入消耗时间;然后使用OpenMP并行库做了多线程协同写入100MB数据的测试。
#include #include #include #include #include "unistd.h"#define MICRO_IN_SEC 1000000.00double microtime();int main(){ int i = 25000000; int ii = 0; int *p1,*p2; double start_time, end_time, dt, dt_err; start_time = microtime(); dt_err = microtime() - start_time; printf("baseline "); start_time = microtime(); p1 = malloc(sizeof(int)*i); for (ii = 0; ii
其中,代码第11行的i变量定义的是数组长度。接着在第21行里,我们申请了100MB的空间。然后通过一个for循环往里写入数据。每个32位int的长度是4字节,因此i的值是25000000。
编译并执行这个程序,通过打印的结果,我们可以推算出这款板子的内存写入速度,单线程下是200MB每秒左右;并且单线程下已经达到峰值(当然,还没有达到内存的理论带宽)。只是由于处理器核心性能和数量的限制,即使开启的线程再多也不会有提速了。

作为对比,瑞芯微RK3399芯片(包含2个A72核心+4个A53核心)搭载DDR3内存的工况,我也做了测试,同样的内存写入算法,但是修改了写入量(写入1GB)。
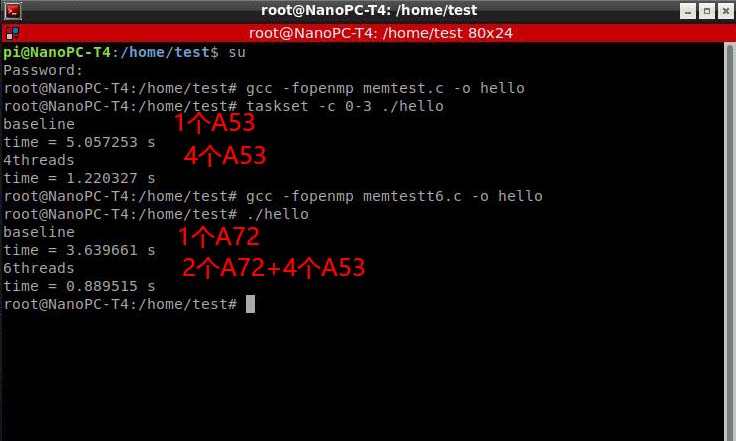
A53核心的单线程写入速度也是200MB每秒左右(与AM5708的A15的单线程成绩差不多);
A72核心的单线程写入速度可以超过300MB每秒;
当6个核心共同并行时,内存写入速度可以超过1GB每秒。
这里,我剧透一下,联想即将推出一款搭载RK3399处理芯片的栗子板,规格与友善之臂的RK3399一致!到时候大家都能感受一下那惊人的内存写入速度。
既然已经做了内存测试,CPU浮点计算测试当然也不能少了。
下面,我将使用本人自创的山寨版SuperPi,它会计算圆周率并记录计算时间。并行库依然使用OpenMP。
程序代码如下:
#include #include #include #include #include "unistd.h"#include #define MICRO_IN_SEC 1000000.00double microtime();int main(){ double s = 1; double pi = 0; double i = 1.0; double n = 1.0; double dt_err; double dt; double p; double start_time, end_time; long cnt = 0; start_time = microtime(); dt_err = microtime() - start_time; printf("baseline "); start_time = microtime(); for (cnt = 0; cnt<100000000; cnt++) { pi += i; n = n + 2; s = -s; i = s / n; } pi = 4 * pi; dt = microtime() - start_time - dt_err; printf("time = %lf s ", dt); s = 1; pi = 0; i = 1.0; n = 1.0; printf("2threads "); start_time = microtime();#pragma omp parallel for num_threads(2) for (cnt = 0; cnt<100000000; cnt++) { pi += i; n = n + 2; s = -s; i = s / n; } pi = 4 * pi; dt = microtime() - start_time - dt_err; printf("time = %lf s ", dt); s = 1; pi = 0; i = 1.0; n = 1.0; printf("4threads "); start_time = microtime();#pragma omp parallel for num_threads(4) for (cnt = 0; cnt<100000000; cnt++) { pi += i; n = n + 2; s = -s; i = s / n; } pi = 4 * pi; dt = microtime() - start_time - dt_err; printf("time = %lf s ", dt); return 1;}double microtime() { int tv_sec, tv_usec; double time; struct timeval tv; struct timezone tz; gettimeofday(&tv, &tz); return tv.tv_sec + tv.tv_usec / MICRO_IN_SEC;}
其中,第23行到34行,先做了一个单线程的计算,并计时。
接着,第36行到53行,是个2线程并行计算测试。
然后,第55行到72行,是个4线程并行计算测试。
编译并运行,截图如下:
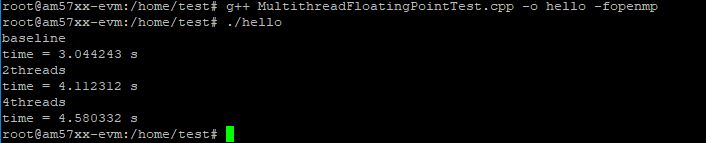
我们可以发现,单线程条件下,大约3秒就可以跑完这个算法。
然后,因为处理器芯片本身的性能限制(单线程就达到满载了),多线程工况下并不能获得更高的速度,而且并行的线程越多,效率越低。4线程并行条件与单线程相比,计算时间从约3秒延长至约4.5秒,甚至达到了50%的“减速比”。
这里,我也可以贴上其他处理器芯片跑相同算法时候的成绩。比如三星的S5P6818,这是个8核Cortex A53内核的处理器,测试结果如下图所示。

我们可以发现一个有趣的现象,64位的A53内核虽然是新内核,但是它的单线程浮点计算能力是要低于老的32位的A15内核低。A15只要约3秒就能算完的算例,放到A53上就需要4秒。也就是说,A15内核与A53相比约有30%的浮点性能提升。诚然,从核心数量和多线程并行角度来看,AM5708与S5P6818相比,总体上还是吃亏的。S5P6818通过8核并行,浮点性能可以达到AM5708的200%(AM5708是约3秒,S5P6818是约1.45秒)
对了,顺便再插一嘴,我们再换个处理器。RK3399的一个A72核心单跑,浮点性能就能超越S5P6818的8个A53一起上。有图为证。下图中,baseline的那条1.083秒就是RK3399的A72核心以单线程跑出来的。

所以,想必各位跑分强迫症已经是迫不及待想玩RK3399了吧。A72核心是2016年出的高性能核心,是要替代A15和A17的。
-
这届世界杯,是联想的AI绿茵场2026-06-17 11135
-
2026年FIFA世界杯联想嘉年华首站正式开启2026-06-16 235
-
联想集团单季营业额首次突破千亿元大关2021-01-14 3241
-
联想集团计划登陆科创板,有助于释放公司价值2021-01-13 1963
-
向联想Yoga Slim 7i Carbon问好2020-10-14 3638
-
【MPS电源评估板试用申请】栗子派P710电源测试---基于MPM54304和EVREF0103电源板2020-06-18 1297
-
联想Leez SBC在MWC2019发布了,你怎么看?2019-02-26 6726
-
联想回归Motorola!?可能弃用Lenovo Moto品牌2017-06-06 1344
-
cc2541开发板存储不够,怎么拓展?2016-03-28 3465
-
首次参加电子发烧友论坛,向大家问好!2016-01-08 4827
-
向各位朋友们问好2014-08-24 2387
-
COB Edwards parts向各位问好2013-03-01 1353
-
华为可能超联想进世界500强2008-08-02 656
全部0条评论

快来发表一下你的评论吧 !
