

并行超算云服务在多个地区开始试用
嵌入式技术
描述
这几年,我们已经试用过很多有趣的ARM小电脑了。
万万没想到,我竟然还获得了超算服务器的试用资格。
10月末的时候,我去了一趟西安,在工程热物理会议上做了一个小小的报告。会议间隙里,“并行®”给我推荐了一下他们的超算服务器。
与一般的多节点高性能计算服务器不同的是,它们的服务器不需要把设备运到本地,而是可以在云端操作。这种云超算平台的名字叫超算网格,是基于国家高性能计算环境与云计算技术,提供多家各大超算与数据中心的计算资源、优化网络、应用与工具、软件与服务的一站式平台,降低了高性能计算应用成本,用户不管身居何处,都能对超算“触手可及”。
超算云使用的是linux操作系统,这个与哈工大的计算服务器相同,但多了云端桌面,方便了远程操作。下面是云端桌面的客户端界面。
客户端带有网速测试功能。因为本地电脑只作为客户端,并不参与计算,所以云端对本地的网速并没有太高的要求,只要不影响正常操作就行。
用putty连接后,可以查看cpu和内存参数。当然,这里只能查看到其中一个节点的20个核。
实际使用中我们可以操作多个节点。比如8个节点,每个节点20核,就有160个核心可以用了。
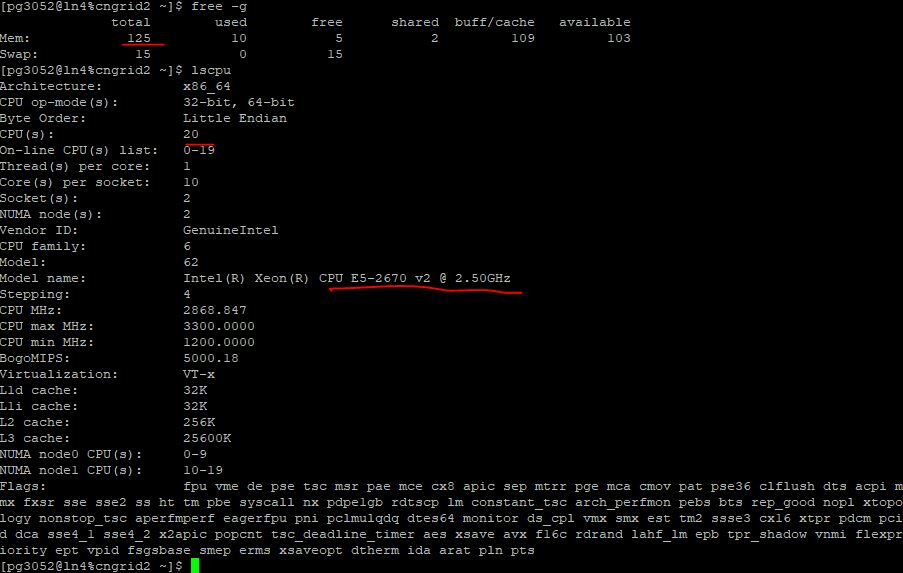
服务器已经预先装上了常用的软件和并行计算库,其中GCC版本是4.8.5
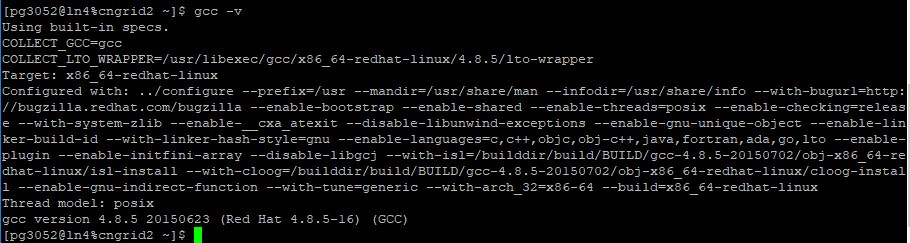
申请账号开通后,安装上fluent软件,就可以体验云端超算了。
我们把算例文件上传一下。文件稍大,是个6百万网格的流场计算算例。
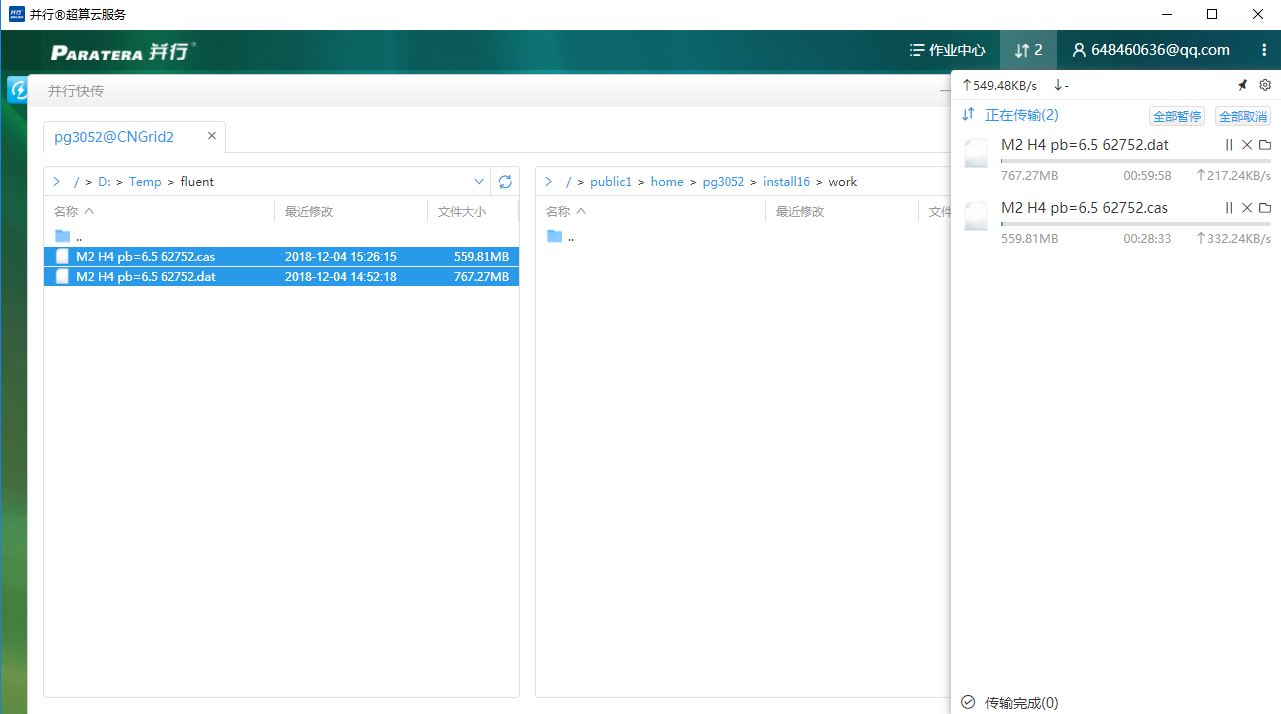
我们可以以多种方式向服务器提交计算工作
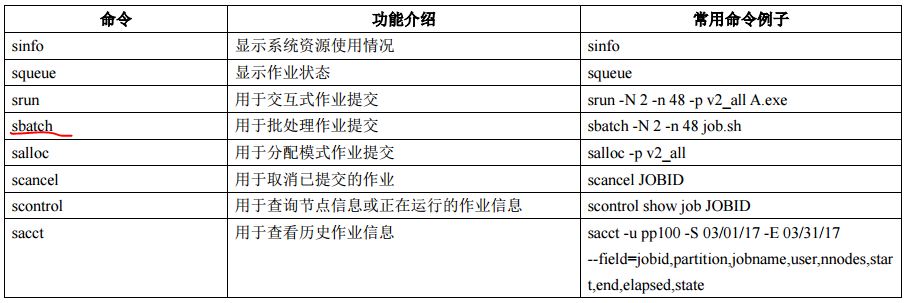
其中,srun命令属于交互式提交作业,有屏幕输出,但容易受网络波动影响,断网或关闭窗口会导致作业中断。
我们用sbatch 提交脚本。这种方式不受本地网络波动影响,提交作业后可以关闭本地电脑。由于sbatch命令没有屏幕输出,默认输出日志为提交目录下的 slurm-xxx.out文件,我们可以使用tail -f slurm-xxx.out 实时查看日志,其中 xxx 为作业号。
举个例子,把一个名字叫fluent.sh的计算脚本提交,命令可以这样写:sbatch fluent.sh
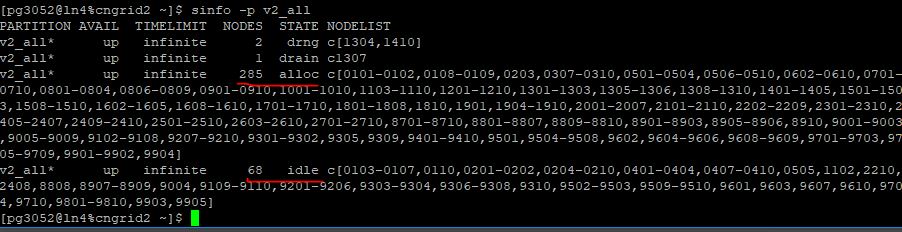
在向服务器提交计算任务前,先查看一下计算节点的空闲情况。我们发现还有六十多个节点处于闲置状态,妥妥地够用啦。
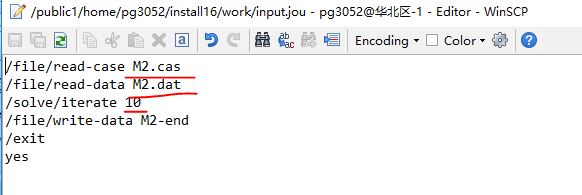
我们先写个fluent计算使用的jou文件,里面定义了算例文件名,和计算迭代次数。
这是个定常流动的计算算例,本身计算量就比非定常计算要小。
然后这里只做速度测试,所以只迭代10次。这种定常计算,正常一般都是1万次以上迭代才能获得一个收敛的结果。
然后我们写一下计算脚本,分别使用不同的节点数量进行计算速度测试。
第一个脚本使用2个节点,共40个核心并行计算
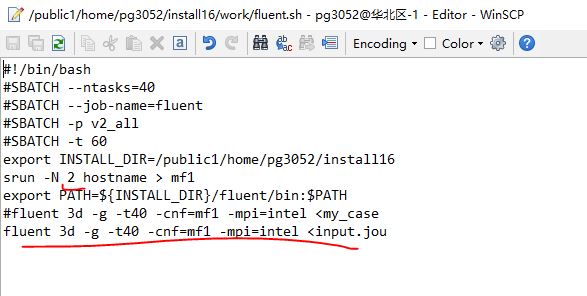
第二个脚本使用4个节点,共80个核心并行计算
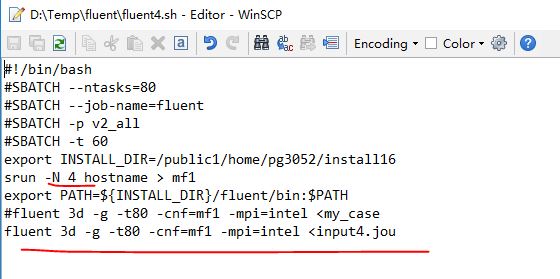
第三个脚本使用8个节点,共160个核心并行计算
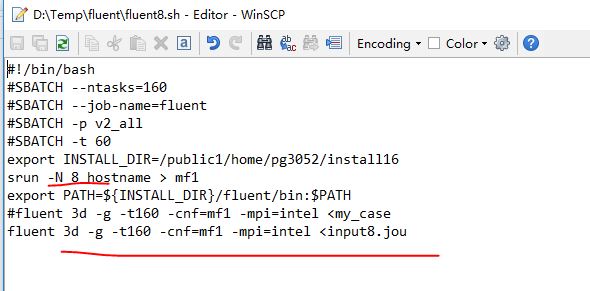
接着,提交作业,然而发现了一个小问题。Unix的文本换行格式与windows不一样。这个只要用dos2uninx命令转一下就好了。
下面,正式提交第一个工作。

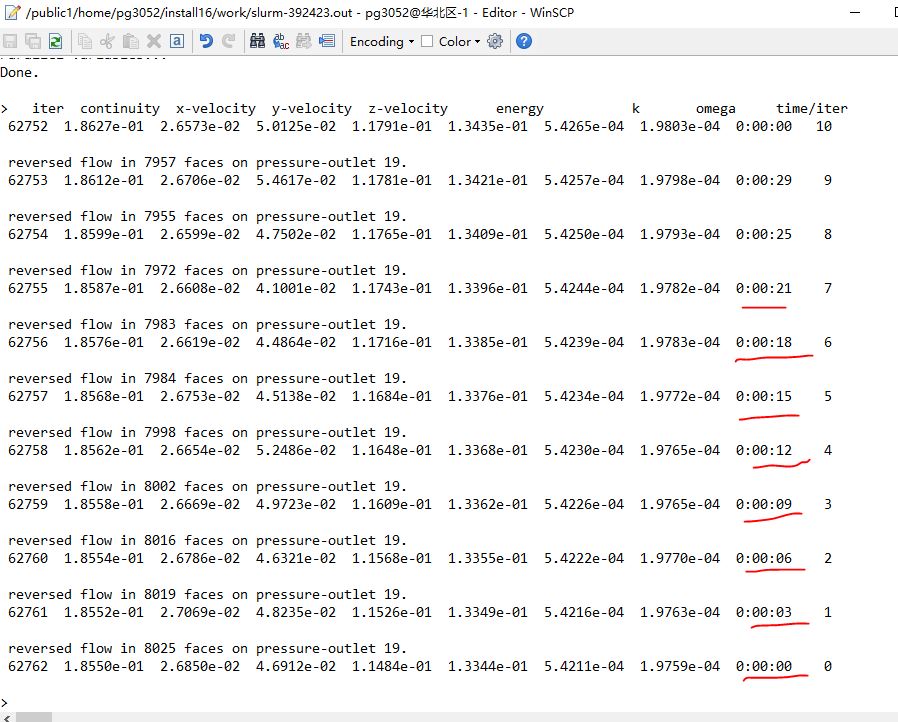
下图中,我们可以发现,两节点40个核心的计算速度还不错的。大约每3秒完成一次迭代步(刚开始,剩余时间估计还没稳定,后来就稳定了)。
这种多机并行的计算环境,CPU与内存之间的交互很快,然而机群节点间的网络传输往往会形成瓶颈,即使是千兆网络往往也会让性能大打折扣。我们用ip命令会发现这种云超算使用了一种叫IB的网卡。
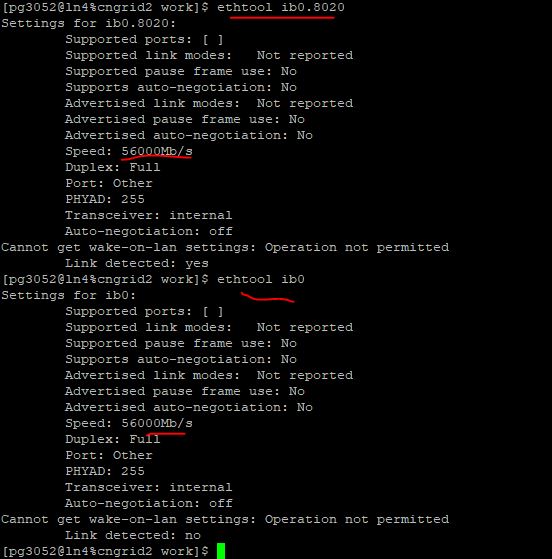
使用ethtool命令可以看到这个IB网卡的具体参数,速度达到了56Gb/s,已经超过1万兆啦。难怪并行速度那么快呢。
下一步,我们继续提交第二个测试算例,使用4节点的80核并行计算。

下图的计算结果可看出,4节点80核的计算条件下,每步迭代时间在1至2秒之间。
再提交第三个160核的计算任务吧。
这一步,发生了一些郁闷的事情。当申请的节点比较多时,需要排队。
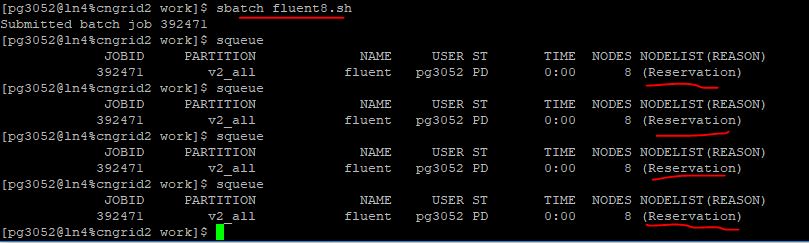
我们排了几分钟,还没排上,等不及了,最后就取消这个任务了。

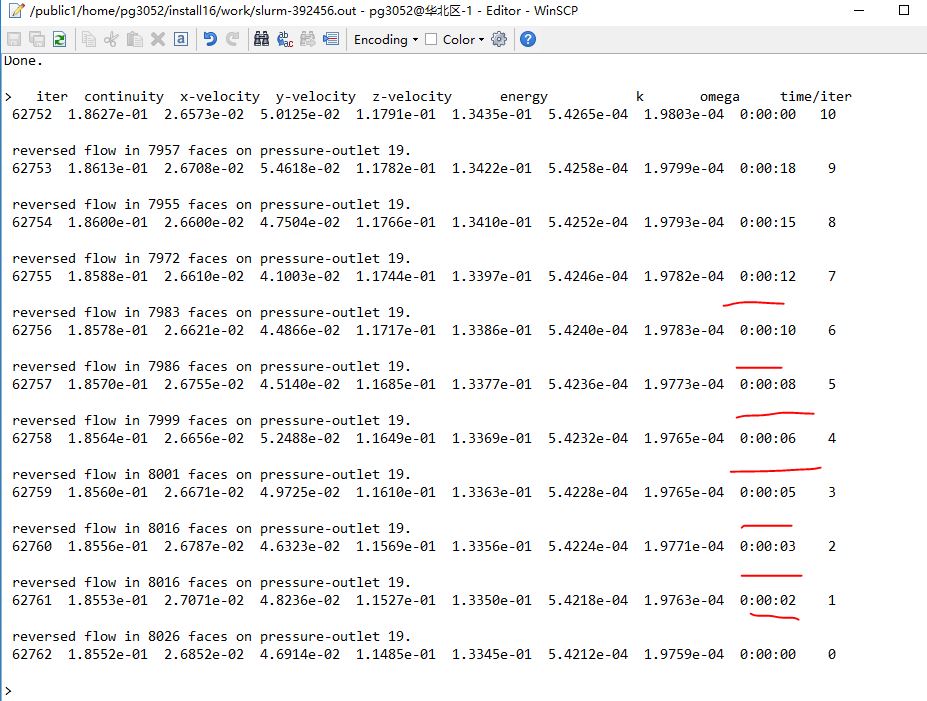
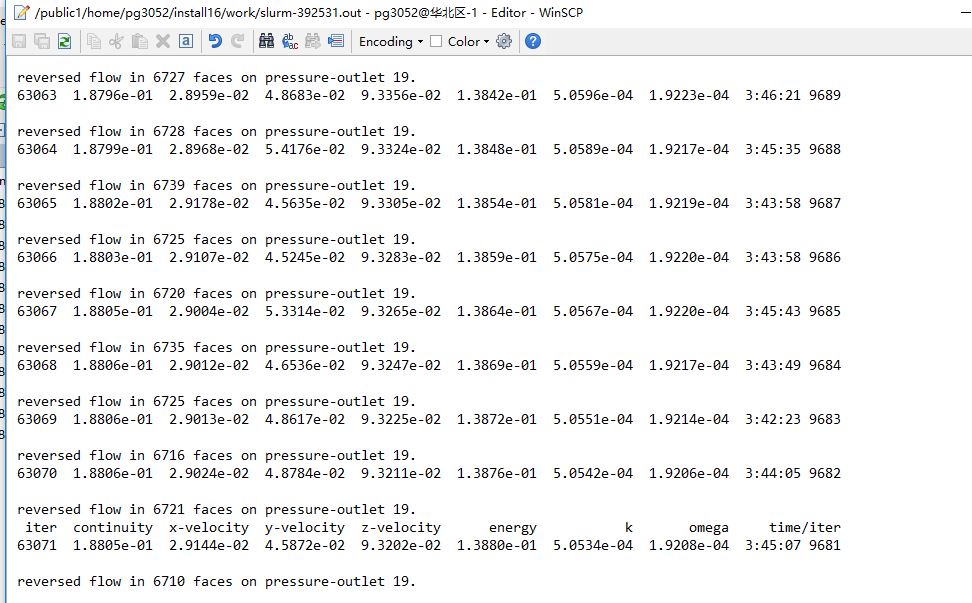
最后,我们模拟正常的计算情况,来一次1万步的迭代计算。
其中计算资源使用4个节点,80核并行。

算了几步以后,通过下面这个输出文件,我们可以发现计算总耗时约在4小时左右,也就是说平均约1.4秒就能完成一个迭代步。
以上就是并行®超算云服务的试用体验。
我觉得,这种服务器的性能是非常好的,内存大,CPU速度快,CPU核心数量多,甚至可以用50个节点进行一千核的并行计算(只是需要排队)。当然,这些都不是最大的亮点了,最大的亮点是在云平台。
我们不用担心占地面积是否过大,不用担心供电功率是否足够,更不用担心噪音扰民,只要通过云端操作就可以把需要巨大计算量的工作给搞定了。
- 相关推荐
- 热点推荐
- 云服务
-
超享云服务器是什么意思?是免费的吗2024-10-08 717
-
北鲲云超算平台推动云计算为各行业提供服务2021-09-11 848
-
并行科技聚合全国各大超算中心与数据中心资源助推云上科研2020-09-30 3495
-
服务器群打造“娱乐云”2011-07-07 2408
-
苹果iTunes开始国内首推MobileMe服务2010-02-25 831
全部0条评论

快来发表一下你的评论吧 !
