

X86桌面太耗电?ARM桌面性能太烂?试试友善之臂的新系统
嵌入式技术
描述
现在市面上有很多64位多核A53的卡片电脑,比如树莓派3、香橙派win、友善之臂K1+等。这些神奇的小电脑在功耗方面的表现非常好,CPU的性能也尚可,所以有不少玩家用它们DIY了笔记本,代替那些X86的高耗电机器,当日常的个人电脑用。
但是,大家都在抱怨ARM桌面的用户体验不好。CPU还是不够快;另外,显卡实在是太垃圾了。
X86的Linux机器一般使用Intel、ATI或NVIDIA的显卡,桌面操作、视频播放或游戏娱乐的体验都比较好。ARM的机器的图形处理器就稍微寒酸一些,使用Mali 400、Mali450等低性能GPU,更糟的是在一些主线内核里还经常不带驱动。
我也觉得不能玩H264硬解和OpenGL的电脑不是一台好游戏机。。。
其实呢,友善之臂的代码小哥也嫌弃自己过去做的桌面系统固件太不好用,所以他最近给自己新做了一整套真正好用的ARM桌面Linux系统。
代码小哥找出了他们团队里最牛逼的硬件——Nano PC T4(基于RK3399)。
然后开发了整整七七四十九天,终于炼成了新固件——FriendlyDesktop18.04
这是首个支持GPU/VPU加速和4K硬解播放的Friendly系统,也是目前驱动和应用支持最完善的RK3399固件。镜像文件分享在百度网盘上RK3399-sd-开头的用于TF启动运行;RK3399-eflasher-开头的用于卡刷;RK3399-TypeC-开头的用于线刷。
代码小哥对自己的作品非常自豪,所以强烈建议我赶紧试用一下。
他说,这次的系统固件,有以下几点特性:
1) 带X桌面 LXDE,基于64位Ubuntu 18.04系统构建,支持OpenGLES加速,支持硬解播放
2) 支持SD卡启动运行,支持TF卡刷机或Type-C刷机
3) 完全保留FriendlyCore18.04 for RK3399的特性,集成带GPU和VPU加速的Qt 5.10.0
4) 内置开源硬解的4K视频播放器 QtVideoPlayer(Menu->Sound & Video->Qt5-VideoPlayer)
5) 内置 QtCreator IDE,Arduino 和 Scratch等流行开发和学习工具,开箱即用
6) 支持双屏异显 (可选择eDP/DP/HDMI 任意两路同时输出)
7) 支持eDP电容触摸屏 (HD702E)
8) 支持AP6356S无线模块 (802.11a/b/g/n/AC,BLE4.0)
9) 支持升兆以太网即插即用
10) 支持OpenCV 3.4 一键安装
11) 内置gcc版本:7.3.0
12) 内核版本:4.4.138
评测:我知道大家都对OpenGL感兴趣,那么我们先测试一下OpenGL吧。如果GPU没有正常驱动的话,玩游戏会非常卡。
在glmark里,主要是做各种多边形、纹理和着色器的测试。比如下图是个猫模型曲面漫反射渲染的测试。
下图是个玻璃材质着色器渲染兔子模型的测试。
不同的渲染项目下,计算量是不同的,各个测试的帧数记录在终端输出上。
这块板子的处理器RK3399是大小核架构的。其中,CPU ID号0到3的四个是低速的A53核心,CPU ID号4和5的两个是高性能的A72核心。
在上一篇文章里,我们已经知道大小核这种奇葩架构的多线程能力并不好。
所以,测试时候,如果不指定核心,让操作系统瞎调度,并不能发挥系统的真正实力(虽然帧数也挺不错的,毫无卡顿)。比如第一项是45FPS。
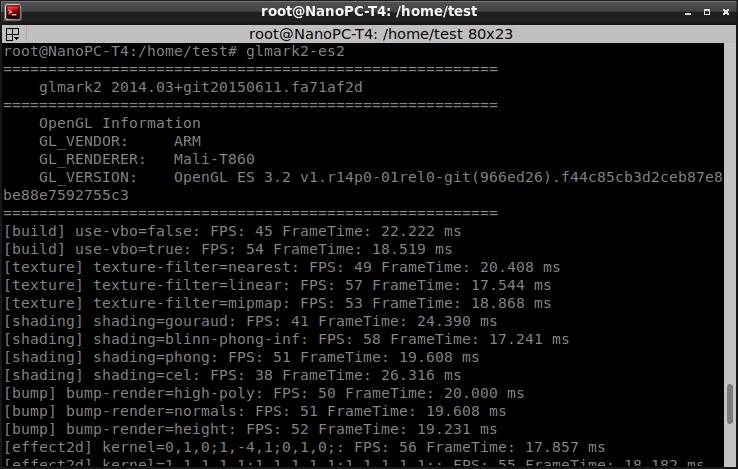
当指定使用CPU ID号4和5的两个高性能A72核心时候,测试得到的帧数比刚才要高一些。比如第一项是57FPS。
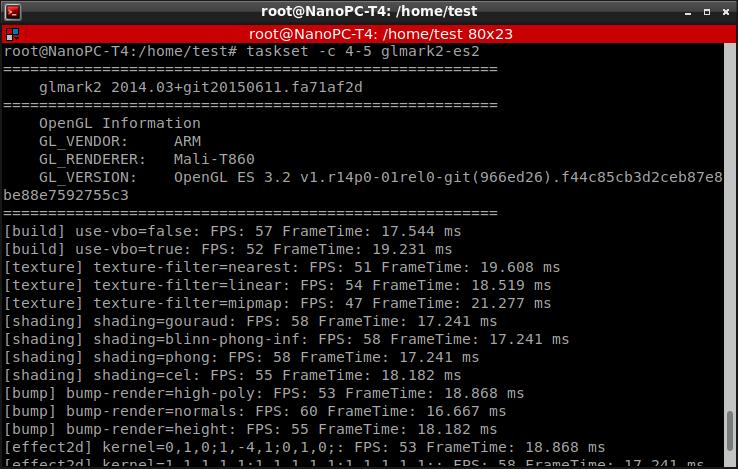
我们稍微等待一下,等所有GPU测试项目都跑完。整个过程都非常流畅,帧数都保持再30帧以上;这说明一般的OpenGL渲染程序或游戏跑起来都不会有太大的问题(这个测试模拟了你在游戏时候实时渲染不同的场景)。
接下来我们来试一下OpenCV人脸识别的例子。我们关注一下识别的速度,大约是100毫秒,也就是说可以达到10Hz的识别速度。
对于RK3399,我们也要关注一下大小核在做OpenCV人脸识别时候的并行效果。
大小核能不能在OpenCV里正常并行加速呢?
我做了下面这几组测试。
一个A72核心单独跑这个算法,大约需要250毫秒。
两个A72并行,大约需要140毫秒。速度比单个A72快。
换做是一个比较慢的A53核心单独跑,大约需要450毫秒。
四个A53并行,大约需要140毫秒。并行提速效果不错。
如果2个A72+4个A53一起上,时间只要大约100毫秒。在OpenCV测试里,大小核一起上的速度是最快的。
在上面这个测试里,我们可以发现RK3399的大小核在OpenCV并行计算过程中的效率还是可以的,能大幅提高计算速度;并不会因为大小核之间的速率不一致而在调度过程中浪费太多资源。(但是我们不要高兴的太早,最后面的测试里会发现,有时会发生“逆加速”)
一个额外的小测试:前段时间,有网友在云汉试用群里反映Nano PC T4的DDR3内存写入速度只有300MB每秒,慢得跟树莓派3的DDR2差不多。正好我这次拿到Nano PC T4实物了,我们就测试一下。
内存写入速度的测试代码如下。这是个6线程写入的例子,稍作修改就可以改成4线程写入。程序的算法很简单,分配1GB的内存空间并填满1,测多少时间完成。

代码编译运行结果如下(绝无作弊)
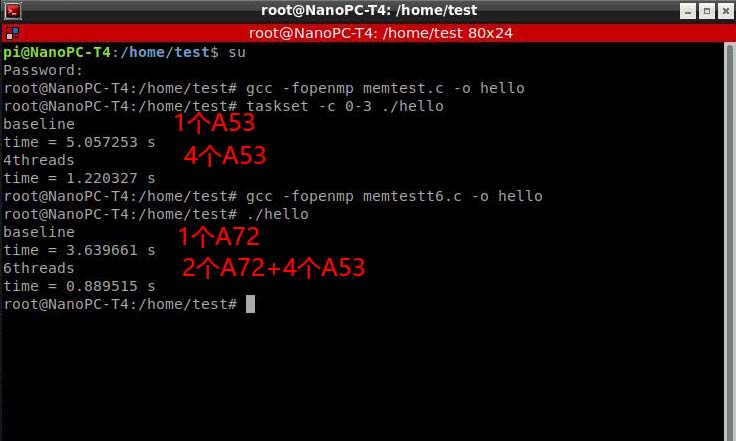
我们可以发现,不管是1个A53还是4个A53并行写入,都不能把内存的写入带宽耗尽。当2个A72和4个A53一起并行写入时,速度大约是1.125GB每秒。大家可能对这个速度没有概念,1.125GB每秒有多快呢?我们跟搭载DDR4的RK3328板子比较一下吧,那个板子的评测地址在http://www.ickey.cc/e/video/detail/57.html。
3328板子的DDR4内存写入速度是1.089GB每秒。Nano Pi T4的DDR3内存写入速度是1.125GB每秒。
大家可以发现T4虽然内存规格低了一些,但是实际使用时候也是一点都不吃亏的。因为内存写入瓶颈是在处理器,RK3399的处理器比较好,往内存写入数据的速度快。
所以,那天在云汉试用群里的那个大兄弟,是冤枉Nano PC T4 了。
另一个额外的小测试:上一篇文章《大小核的OpenMP多线程并行计算测试》里,我们已经知道大小核在并行时候是会浪费很多资源在不同速度进程的调度上的。我们今天再做个测试,如果指定用哪几个CPU做并行,效果是不是能好一些?
测试代码如下。

测试过程的截图如下,分别对不指定CPU(系统自动调度),指定只用A53,和只用A72做了对比。
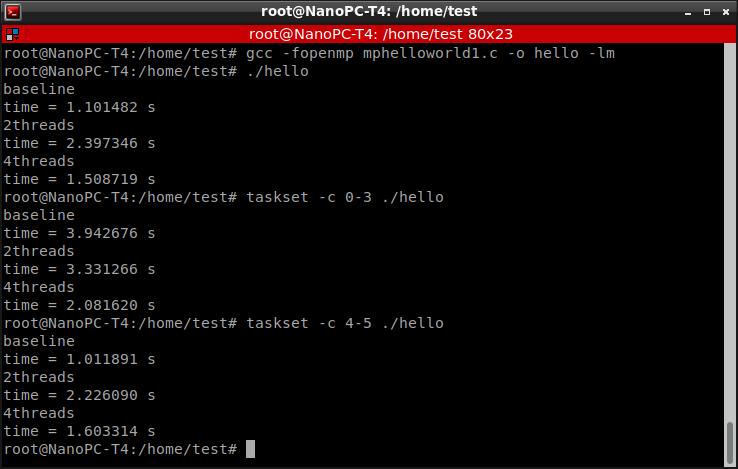
如果不指定CPU,单线程耗时1.10秒;这个速度介于指定A53单线程(3.94秒)和指定A72单线程(1.01秒)之间,但是更接近A72单线程时候的耗时。这说明系统的自动调度效率还是比较高的,能主动让A72去执行大计算量的工作。
所以,对于单线程的工作,我们只要让系统自己去调度就好了。
A53的单核计算速度很慢,但是4核并行时候的提速效果较好,计算耗时从3.94秒降至2.08秒,耗时减少一半。
所以,对于那种又需要省电又需要一定计算能力的工作,可以采用指定4个A53并行的方式来做。
A72的单核能力不错,但是越并越慢。单核A72时候速度最快,只要1.01秒。指定两个A72并行时候,速度反而变慢了。
可能是ARM得罪了OpenMP吧,所以OpenMP对ARM的最新A72内核做了坑爹的“逆优化”
但是不管怎么说,速度依然是很快的,日常游戏和看视频娱乐都没有问题。
-
深入了解CPU两大架构ARM与X862016-05-30 19238
-
X86架构和ARM架构2011-11-30 41754
-
X86与ARM,江湖厮杀鹿死谁手?2016-08-04 4568
-
win7桌面背景无法修改怎么办2012-11-12 3056
-
高保真2.1桌面音响2013-09-15 10112
-
从移动到桌面—ARM挑战X862016-08-31 3507
-
【ROC-RK3568-PC开发板试用体验】Ubuntu20.04桌面系统体验升级与GCC安装2022-09-04 1557
-
ARM进军服务器 看Intel如何应对2011-12-13 682
-
戴尔WP原型机曝光 搭载x86桌面处理器可当PC用2016-11-08 852
-
骁龙820支持Win10运行x86程序 性能可媲美i3!2016-12-10 4565
-
MIUI12桌面设置八点小技巧2020-12-02 8621
-
arm架构和x86架构区别 linux是x86还是arm2024-01-30 25833
-
GNOME 46桌面环境发布,新增远程桌面、在线账户功能,优化多项功能2024-03-21 2404
-
KaihongOS桌面版成功适配x86设备,邀您抢先体验!2025-06-30 3248
-
深开鸿举办KaihongOS X86桌面版金牌体验官见面会,聚力共建开源鸿蒙桌面生态2026-05-14 288
全部0条评论

快来发表一下你的评论吧 !
