

GAN又开辟了新疆界,MirrorGAN有多强?
电子说
描述
浙大、悉尼大学等高校研究员提出MirrorGAN,作为全局-局部注意和语义保持的文本-图像-文本框架,解决文本描述和视觉内容之间的语义一致性问题,并在COCO数据集上刷新了记录。
GAN又开辟了新疆界。
去年英伟达的StyleGAN在生成高质量和视觉逼真的图像,骗过了无数双眼睛,随后一大批假脸、假猫、假房源随之兴起,可见GAN的威力。
StyleGAN生成假脸
虽然GAN在图像方面已经取得了重大进展,但是保证文本描述和视觉内容之间的语义一致性上仍然是非常具有挑战性的。
最近,来自浙江大学、悉尼大学等高校的研究人员,提出一种新颖的全局-局部注意和语义保持的文本-图像-文本(text-to-image-to-text)框架来解决这个问题,这种框架称为MirrorGAN。

MirrorGAN有多强?
在目前较为主流的数据集COCO数据集和CUB鸟类数据集上,MirrorGAN都取得了最好成绩。
目前,论文已被CVPR2019接收。
MirrorGAN:解决文本和视觉之间语义一致性
文本生成图像(T2I)在许多应用领域具有巨大的潜力,已经成为自然语言处理和计算机视觉领域的一个活跃的研究领域。
与基本图像生成问题相反,T2I生成以文本描述为条件,而不是仅从噪声开始。利用GAN的强大功能,业界已经提出了不同的T2I方法来生成视觉上逼真的和文本相关的图像。这些方法都利用鉴别器来区分生成的图像和相应的文本对以及ground-truth图像和相应的文本对。
然而,由于文本和图像之间的区域差异,当仅依赖于这样的鉴别器时,对每对内的基础语义一致性进行建模是困难且低效的。
近年来,针对这一问题,人们利用注意机制来引导生成器在生成不同的图像区域时关注不同的单词。然而,由于文本和图像模式的多样性,仅使用单词级的注意并不能确保全局语义的一致性。如图1(b)所示:
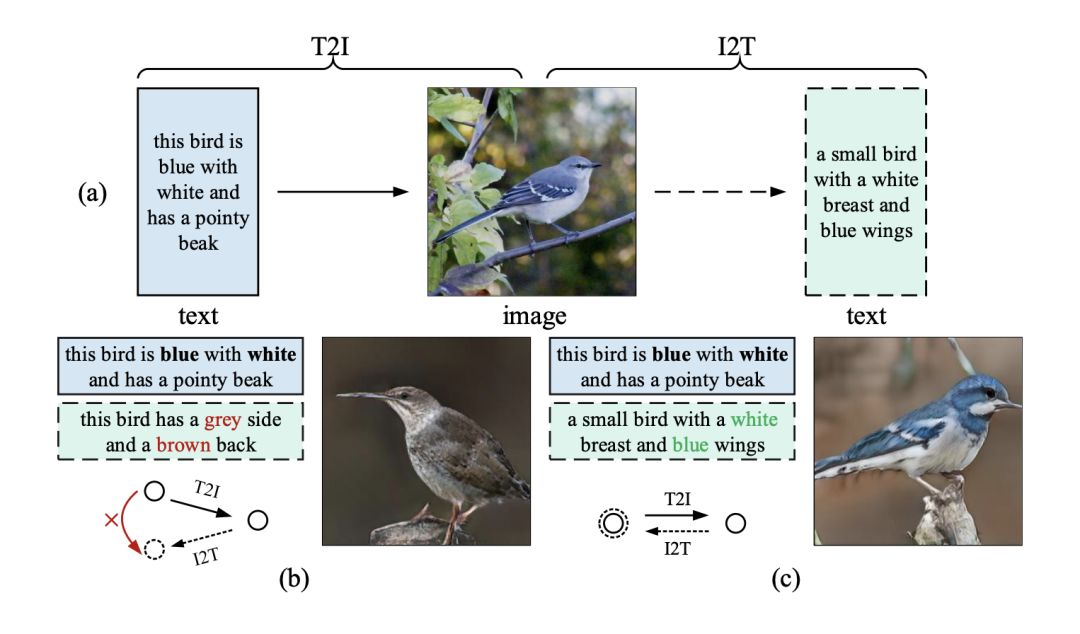
图1 (a)镜像结构的说明,体现了通过重新描述学习文本到图像生成的思想;(b)-(c)前人的研究成果与本文提出的MirrorGAN分别生成的语义不一致和一致的图像/重新描述。
T2I生成可以看作是图像标题(或图像到文本生成,I2T)的逆问题,它生成给定图像的文本描述。考虑到处理每个任务都需要对这两个领域的底层语义进行建模和对齐,因此在统一的框架中对这两个任务进行建模以利用底层的双重规则是自然和合理的。
如图1 (a)和(c)所示,如果T2I生成的图像在语义上与给定的文本描述一致,则I2T对其重新描述应该与给定的文本描述具有完全相同的语义。换句话说,生成的图像应该像一面镜子,准确地反映底层文本语义。
基于这一观察结果,论文提出了一个新的文本-图像-文本的框架——MirrorGAN来改进T2I生成,它利用了通过重新描述学习T2I生成的思想。
解剖MirrorGAN三大核心模块
对于T2I这一任务来说,主要的目标有两个:
视觉真实性;
语义
且二者需要保持一致性。
MirrorGAN利用了“文本到图像的重新描述学习生成”的思想,主要由三个模块组成:
语义文本嵌入模块(STEM);
级联图像生成的全局-局部协同关注模块(GLAM);
语义文本再生与对齐模块(STREAM)。
STEM生成单词级和句子级的嵌入;GLAM有一个级联的架构,用于从粗尺度到细尺度生成目标图像,利用局部词注意和全局句子注意,逐步增强生成图像的多样性和语义一致性;STREAM试图从生成的图像中重新生成文本描述,该图像在语义上与给定的文本描述保持一致。
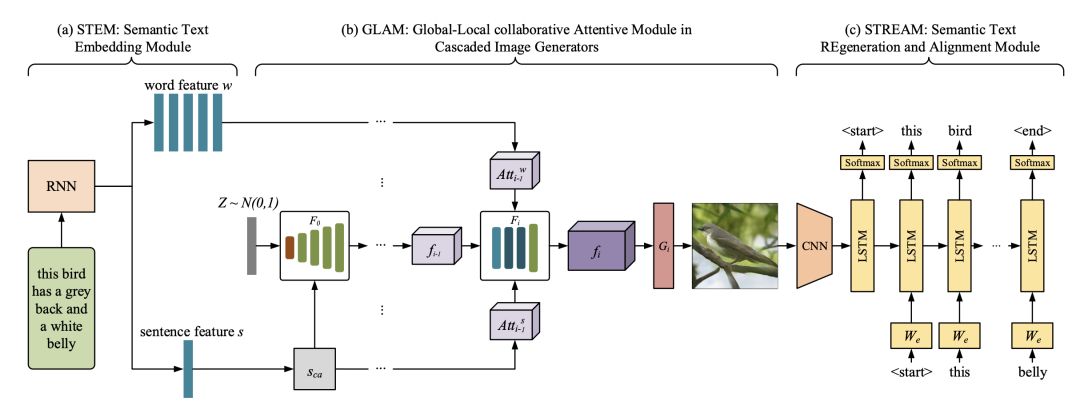
图2 MirrorGAN原理图
如图2所示,MirrorGAN通过集成T2I和I2T来体现镜像结构。
它利用了通过重新描述来学习T2I生成的想法。 生成图像后,MirrorGAN会重新生成其描述,该描述将其基础语义与给定的文本描述对齐。
以下是MirrorGAN三个模块组成:STEM,GLAM和STREAM。
STEM:语义文本嵌入模块
首先,引入语义文本嵌入模块,将给定的文本描述嵌入到局部词级特征和全局句级特征中。
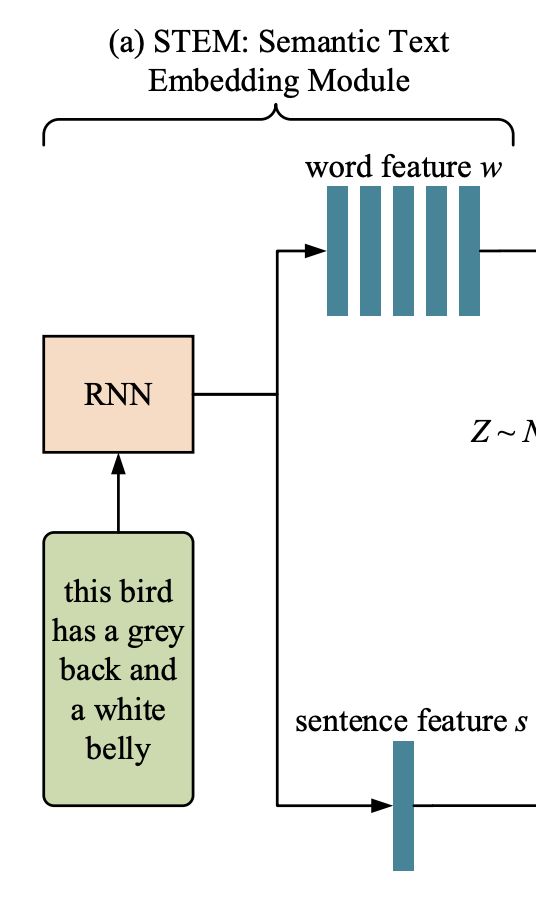
如图2最左边所示(即上图),使用一个递归神经网络(RNN)从给定的文本描述中提取语义嵌入T,包括一个嵌入w的单词和一个嵌入s的句子。
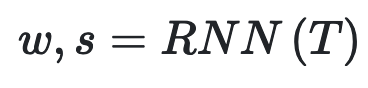
GLAM:级联图像生成的全局-局部协同关注模块
接下来,通过连续叠加三个图像生成网络,构造了一个多级级联发生器。
本文采用了《Attngan: Fine-grained text to image generation with attentional generative adversarial networks》中描述的基本结构,因为它在生成逼真的图像方面有很好的性能。
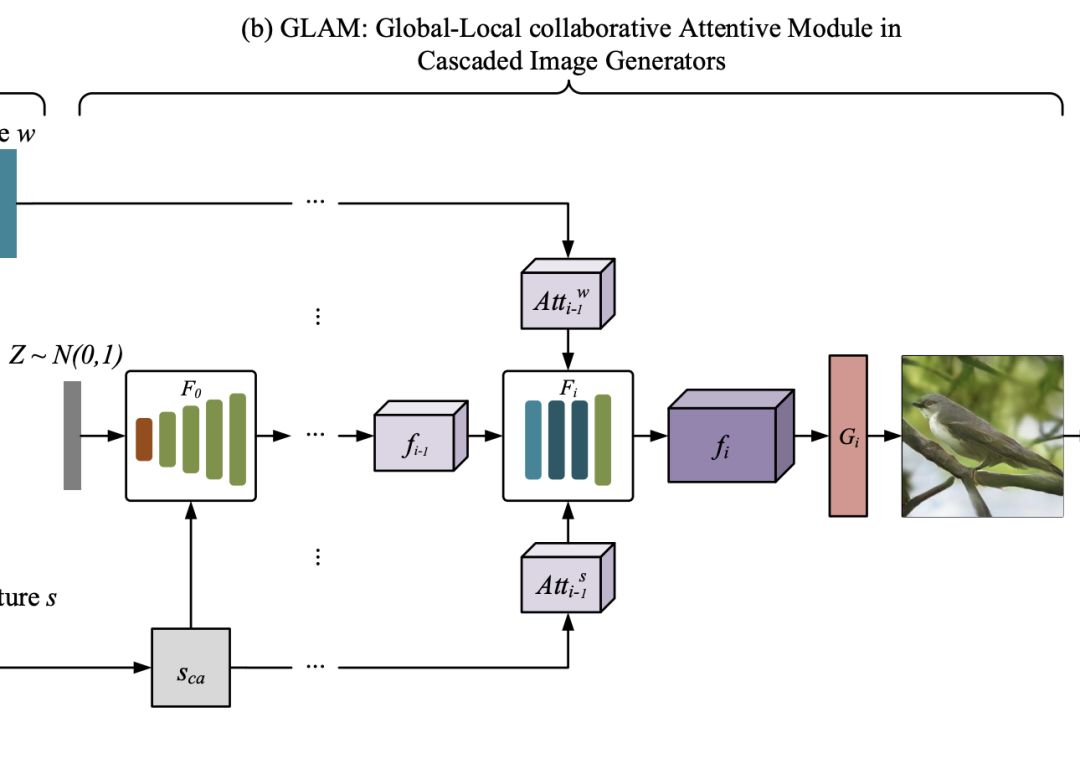
使用{F0,F1,…,Fm-1}来表示m个视觉特征变换器,并使用{G0,G1,…,Gm-1}来表示m个图像生成器。 每个阶段中的视觉特征Fi和生成的图像Ii可以表示为:
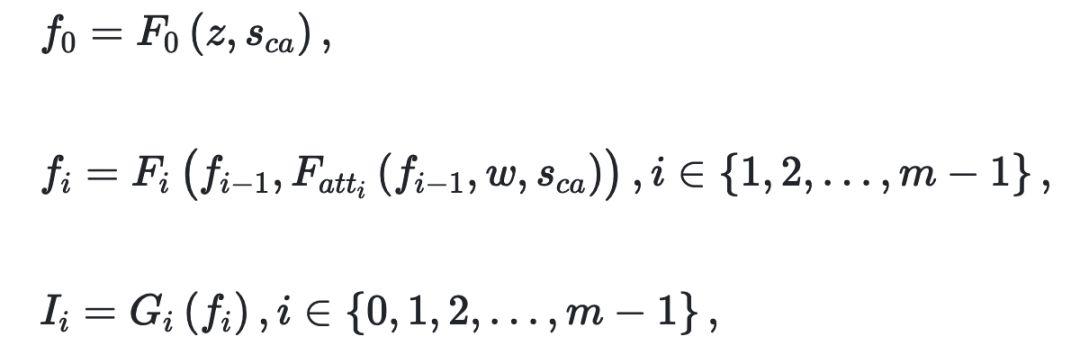
STREAM:语义文本再生与对齐模块
如上所述,MirrorGAN包括语义文本再生和对齐模块(STREAM),以从生成的图像重新生成文本描述,其在语义上与给定的文本描述对齐。
具体来说,采用了广泛使用的基于编码器解码器的图像标题框架作为基本的STREAM架构。
图像编码器是在ImageNet上预先训练的卷积神经网络(CNN),解码器是RNN。由末级生成器生成的图像Im-1输入CNN编码器和RNN解码器如下:
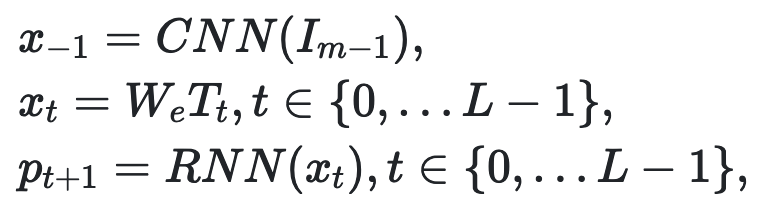
实验结果:COCO数据集上成绩最佳
那么,MirrorGAN的性能有多强呢?
首先来看一下MirrorGAN与其它最先进的T2I方法的比较,包括GAN-INT-CLS、GAWWN、StackGAN、StackGAN ++ 、PPGN和AttnGAN。
所采用的数据集是目前较为主流的数据集,分别是COCO数据集和CUB鸟类数据集:
CUB鸟类数据集包含8,855个训练图像和2,933个属于200个类别的测试图像,每个鸟类图像有10个文本描述;
OCO数据集包含82,783个训练图像和40,504个验证图像,每个图像有5个文本描述。
结果如表1所示:
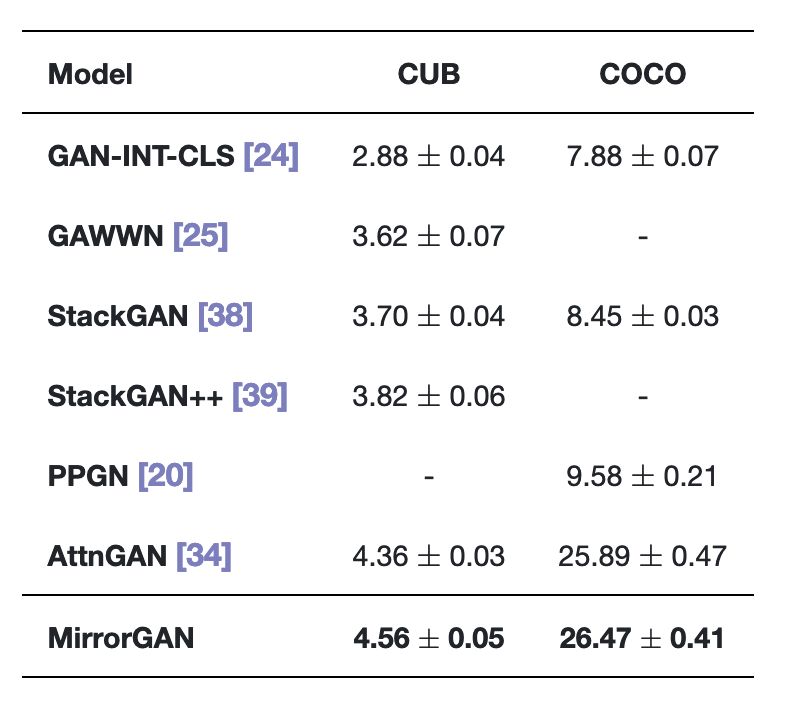
表1 在CUB和COCO数据集上,MirrorGAN和其它先进方法的结果比较
表2展示了AttnGAN和MirrorGAN在CUB和COCO数据集上的R精度得分。
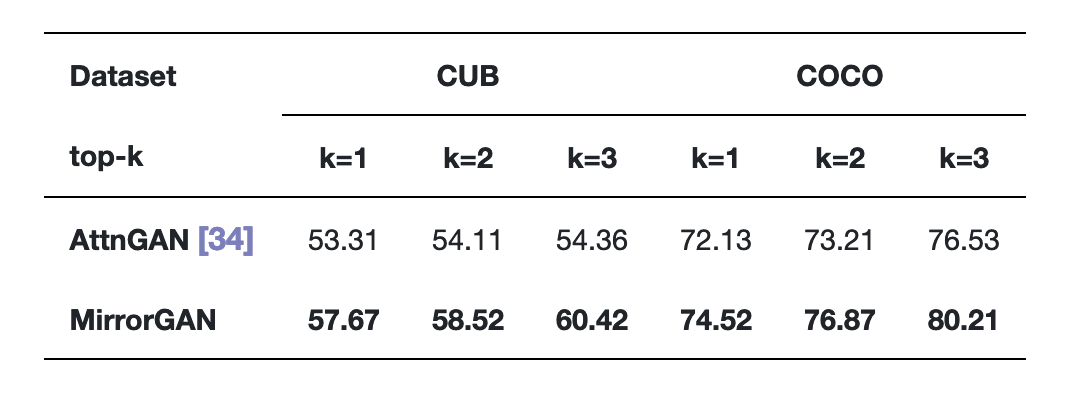
表2 在CUB和COCO数据集上,MirrorGAN和AttnGAN的R精度得分。
在所有实验比较中,MirrorGAN都表现出了更大的优势,这表明了本文提出的文本到图像到文本的框架和全局到本地的协作关注模块的优越性,因为MirrorGAN生成的高质量图像具有与输入文本描述一致的语义。
-
rt1052性能有多强?2023-10-27 712
-
DMA开辟缓存怎么使用动态内存?2023-10-23 604
-
Molex莫仕连接器的功能究竟有多强大?看他们的行业应用你就知道了!2022-12-31 12890
-
内窥镜成像探头为更广泛的成像应用开辟了道路2022-11-07 2071
-
GaN 为电源应用开辟了新领域2022-08-04 1281
-
新疆红枣质量认证+区块链溯源解决方案2021-04-03 1862
-
2020年河北gan部网络学院开始了2020-02-21 1692
-
新疆联通携手国网新疆电力成功在电力铁塔上部署了5G基站2019-09-03 2933
-
基于GaN的开关器件2019-06-21 3662
-
51单片机如何开辟栈空间?2018-12-07 4546
-
TI助力GaN技术的推广应用2018-09-10 2886
-
新疆为什么禁飞无人机_新疆无人机禁飞区域2018-03-06 60194
-
小刘老师,我是新疆的学生,但是看你好多资料都是网盘下载新疆无法用网盘下载啊2017-12-11 1815
全部0条评论

快来发表一下你的评论吧 !
