

盘点数据科学和机器学习面试中的常见问题
电子说
描述
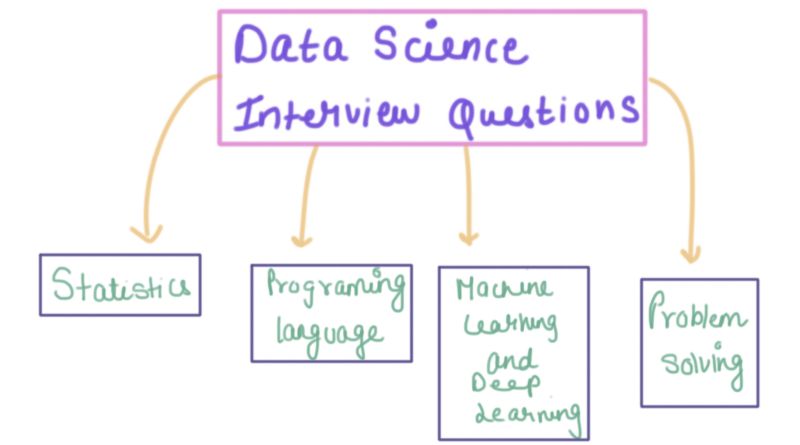
本文盘点了数据科学和机器学习面试中的常见问题,着眼于不同类型的面试问题。如果您计划向数据科学领域转行,这些问题一定会有所帮助。本文约5000字,阅读大约需要10分钟。
技术的不断进步使得数据和信息的产生速度今非昔比,并且呈现出继续增长的趋势。此外,目前对解释、分析和使用这些数据的技术人员需求也很高,这在未来几年内会呈指数增长。这些新角色涵盖了从战略、运营到管理的所有方面。因此,当前和未来的需求将需要更多的数据科学家、数据工程师、数据战略家和首席数据官这样类似的角色。
本文将着眼于不同类型的面试问题。如果您计划向数据科学领域转行,这些问题一定会有所帮助。
统计学及数据科学面试题答案
在统计学研究中,统计学中最常见的三个“平均值”是均值,中位数和众数:
算术平均值:它是统计学中的一个重要概念。算术平均值也可称为平均值,它是通过将两个或多个数字/变量相加,然后将总和除以数字/变量的总数而获得的数量或变量。
中位数:中位数也是观察一组数据平均情况的一种方法。它是一组数字的中间数字。结果有两种可能性,因为数据总数可能是奇数,也可能是偶数。如果总数是奇数,则将组中的数字从最小到最大排列。中位数恰好是位于中间的数,两侧的数量相等。如果总数是偶数,则按顺序排列数字并选择两个中间数字并加上它们然后除以2,它将是该组的中位数。
众数:众数也是观察平均情况的方法之一。众数是一个数字,指在一组数字中出现最多的数字。有些数列可能没有任何众数;有些可能有两个众数,称为双峰数列。
标准差(Sigma):标准差用于衡量数据在统计数据中的离散程度。
回归:回归是统计建模中的一种分析方法。这是衡量变量间关系的统计过程;它决定了一个变量和一系列其他自变量之间关系的强度。
线性回归:是预测分析中使用的统计技术之一,该技术将确定自变量对因变量的影响强度。
统计学的两个主要分支:
描述性统计:描述性统计使用类似均值或标准差的指数来总结样本数据。描述性统计方法包括展示、组织和描述数据。
推断性统计:推断统计得出的结论来自随机变化的数据,如观察误差和样本变异。
相关性:相关性被认为是测量和估计两个变量间定量关系的最佳技术。相关性可以衡量两个变量相关程度的强弱。
协方差:协方差对应的两个变量一同变化,它用于度量两个随机变量在周期中的变化程度。这是一个统计术语;它解释了一对随机变量之间的关系,其中一个变量的变化时,另一个变量如何变化。
协方差和相关性是两个数学概念;这两种方法在统计学中被广泛使用。相关性和协方差都可以构建关系,并且还可测量两个随机变量之间的依赖关系。虽然这两者在数学上有相似之处,但它们含义并不同。
结合数据分析,统计可以用于分析数据,并帮助企业做出正确的决策。预测性“分析”和“统计”对于分析当前数据和历史数据以预测未来事件非常有用。
统计数据可用于许多研究领域。以下列举了统计的应用领域:
科学
技术
商业
生物学
计算机科学
化学
支持决策
提供比较
解释已经发生的行为
预测未来
估计未知数量
在统计研究中,通过结构化和统一处理,样本是从统计总体中收集或处理的一组或部分数据,并且样本中的元素被称为样本点。
以下是4种抽样方法:
聚类抽样:在聚类抽样方法中,总体将被分为群组或群集。
简单随机抽样:这种抽样方法仅仅遵循随机分配。
分层抽样:在分层抽样中,数据将分为组或分层。
系统抽样:根据系统抽样方法,每隔k个成员,从总体中抽取一个。
当我们在统计中进行假设检验时,p值有助于我们确定结果的显著性。这些假设检验仅仅是为了检验关于总体假设的有效性。零假设是指假设和样本没有显著性差异,这种差异指抽样或实验本身造成的差异。
数据科学是数据驱动的科学,它还涉及自动化科学方法、算法、系统和过程的跨学科领域,以任何形式(结构化或非结构化)从数据中提取信息和知识。此外,它与数据挖掘有相似之处,它们都从数据中抽象出有用的信息。
数据科学包括数理统计以及计算机科学和应用。此外,结合了统计学、可视化、应用数学、计算机科学等各个领域,数据科学将海量数据转化为洞见。
同样,统计学是数据科学的主要组成部分之一。统计学是数学商业的一个分支,它包括数据的收集、分析、解释、组织和展示。
R语言类面试题答案
R是数据分析软件,主要的服务对象是分析师、量化分析人员、统计学家、数据科学家等。
R提供的函数是:
均值
中位数
分布
协方差
回归
非线性模型
混合效果
广义线性模型(GLM)
广义加性模型(GAM)等等
在R控制台中输入命令(“Rcmdr”)将启动R Commander GUI。
使用R commander导入R中的数据,有三种方法可以输入数据。
你可以通过Data<- New Data Set 直接输入数据
从纯文本(ASCII)或其他文件(SPSS,Minitab等)导入数据
通过键入数据集的名称或在对话框中选择数据集来读取数据集
虽然R可以轻松连接到DBMS,但不是数据库
R不包含任何图形用户界面
虽然它可以连接到Excel / Microsoft Office,但R语言不提供任何数据的电子表格视图
在R中,在程序的任何地方,你必须在#sign前面加上代码行,例如:
减法
除法
注意运算顺序
要在R中保存数据,有很多方法,但最简单的方法是:
Data > Active Data Set > Export Active dataset,将出现一个对话框,当单击确定时,对话框将根据常用的方式保存数据。
你可以通过cor()函数返回相关系数,cov()函数返回协方差。
在R中,t.test()函数用于进行各种t检验。 t检验是统计学中最常见的检验,用于确定两组的均值是否相等。
With()函数类似于SAS中的DATA,它将表达式应用于数据集。
BY()函数将函数应用于因子的每个水平。它类似于SAS中的BY。
R 有如下这些数据结构:
向量
矩阵
数组
数据框
通用的形式是:
Mymatrix< - matrix (vector, nrow=r, ncol=c , byrow=FALSE, dimnames = list ( char_vector_ rowname, char_vector_colnames)
在R中,缺失值由NA(Not Available)表示,不可能的值由符号NaN(not a number)表示。
为了重新整理数据,R提供了各种方法,转置是重塑数据集的最简单的方法。为了转置矩阵或数据框,可以使用t()函数。
通过一个或多个BY变量,使得折叠R中的数据变得容易。使用aggregate()函数时,BY变量应该在列表中。
机器学习类面试题答案
机器学习是人工智能的一种应用,它为系统提供了自动学习和改进经验的能力,而无需明确的编程。此外,机器学习侧重于开发可以访问数据并自主学习的程序。
在很多领域,机器人正在取代人类。这是因为编程使得机器人可以基于从传感器收集的数据来执行任务。他们从数据中学习并智能地运作。
机器学习中不同类型的算法技术如下:
强化学习
监督学习
无监督学习
半监督学习
转导
元学习
监督学习是一个需要标记训练集数据的过程,而无监督学习则不需要数据标记。
无监督学习包括如下:
数据聚类
数据的降维表示
探索数据
探索坐标和相关性
识别异常观测
监督学习包括如下:
分类
语音识别
回归
预测时间序列
注释字符串
朴素贝叶斯的优点:
分类器比判别模型更快收敛
它可以忽略特征之间的相互作用
朴素贝叶斯的缺点是:
不适用连续性特征
它对数据分布做出了非常强的假设
在数据稀缺的情况下不能很好地工作
朴素贝叶斯是如此的不成熟,因为它假设数据集中所有特征同等重要且独立。
过拟合:统计模型侧重于随机误差或噪声而不是探索关系,或模型过于复杂。
回答:
过拟合的一个重要原因和可能性是用于训练模型的标准与用于判断模型功效的标准不同。
避免过拟合方式:
大量数据
交叉验证
五种常用的机器学习算法:
决策树
概率网络
最近邻
支持向量机
神经网络
机器学习算法的应用案例:
欺诈检测
人脸识别
自然语言处理
市场细分
文本分类
生物信息学
参数模型是指参数有限且用于预测新数据的模型,你只需知道模型的参数即可。
非参数模型是指参数数量无限的模型,允许更大的灵活性且用于预测新数据,你需要了解模型的参数并熟悉已收集的观测数据。
在机器学习中构建假设或模型的三个阶段是:
模型构建
模型测试
模型应用
归纳逻辑编程(ILP):是机器学习的一个子领域,它使用代表背景知识和案例的逻辑程序。
分类和回归之间的区别如下:
分类是关于识别类别的组成,而回归涉及预测因变量。
这两种技术都与预测相关。
分类预测类别的归属,而回归预测来自连续集的值。
当模型需要返回数据集中的数据点的归属类别时,回归不是首选。
归纳机器学习和演绎机器学习的区别:机器学习模型通过从一组观察实例中学习,得出一个广义结论;演绎学习要基于一些已知结论,得出结果。
决策树的优点是:
决策树易于理解
非参数
调整的参数相对较少
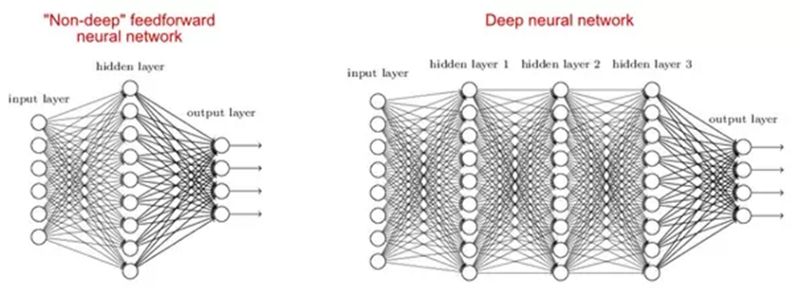
机器学习领域专注于深受大脑启发的深度人工神经网络。Alexey Grigorevich Ivakhnenko将深度学习网络带入大众视野。如今它已应用于各种领域,如计算机视觉、语音识别和自然语言处理。
有研究表明,浅网和深网都可以适应任何功能,但由于深度网络有几个不同类型的隐藏层,因此相比于参数更少的浅模型,它们能够构建或提取更好的特征。
代价函数:神经网络对于给定训练样本和预期输出的准确度的度量。它是一个值,而非向量,因为它支撑了整个神经网络的性能。它可以计算如下平均误差函数:
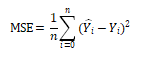
其中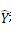 和期望值Y是我们想要最小化的。
和期望值Y是我们想要最小化的。
梯度下降:一种基本的优化算法,用于学习最小化代价函数的参数值。此外,它是一种迭代算法,它在最陡下降的方向上移动,由梯度的负值定义。我们计算给定参数的成本函数的梯度下降,并通过以下公式更新参数:
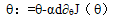
其中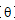 是参数向量,α 是学习率,J(
是参数向量,α 是学习率,J(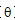 )是成本函数。
)是成本函数。
反向传播:一种用于多层神经网络的训练算法。在此方法中,我们将误差从网络末端移动到网络内的所有权重,从而进行梯度的高效计算。它包括以下几个步骤:
训练的前向传播以产生输出。
然后可以使用目标值和输出值误差导数来计算输出激活。
然后我们返回传播以计算前一个输出激活的误差导数,并对所有隐藏层继续此操作。
使用之前计算的输出和所有隐藏层的导数,我们计算关于权重的误差导数。
然后更新权重。
随机梯度下降:我们仅使用单个训练样本来计算梯度和更新参数。
批量梯度下降:我们计算整个数据集的梯度,并在每次迭代时进行更新。
小批量梯度下降:它是最流行的优化算法之一。它是随机梯度下降的变体,但不是单个训练示例,使用小批量样本。
小批量梯度下降的好处
与随机梯度下降相比,这更有效。
通过找到平面最小值来提高泛化性。
小批量有助于估计整个训练集的梯度,这有助于我们避免局部最小值。
在反向传播期间要使用数据标准化。数据规范化背后的主要动机是减少或消除数据冗余。在这里,我们重新调整值以适应特定范围,以实现更好的收敛。
权重初始化:非常重要的步骤之一。糟糕的权重初始化可能会阻止网络学习,但良好的权重初始化有助于更快的收敛和整体误差优化。偏差通常可以初始化为零。设置权重的规则应接近于零,而不是太小。
自编码:一种使用反向传播原理的自主机器学习算法,其中目标值设置为等于所提供的输入。在内部有一个隐藏层,用于描述用于表示输入的代码。自编码的一些重要特征:
它是一种类似于主成分分析(PCA)的无监督机器学习算法
最小化与主成分分析相同的目标函数
它是一个神经网络
神经网络的目标输出是其输入
玻尔兹曼机(Boltzmann Machine):一种问题解决方案的优化方法。玻尔兹曼机的工作基本是为了优化给定问题的权重和数量。关于玻尔兹曼机的一些要点如下:
它使用循环结构。
由随机神经元组成,其中包括两种可能的状态之一,1或0。
其中的神经元处于连通状态(自由状态)或断开状态(冻结状态)。
如果我们在离散Hopfield网络上应用模拟退火,那么它将成为玻尔兹曼机。
激活函数:一种将非线性引入神经网络的方法,它有助于学习更复杂的函数。没有它,神经网络只能学习线性函数。线性函数是输入数据的线性组合。
-
25个机器学习面试题,你都会吗?2018-09-29 4927
-
单片机面试常见问题及答案2021-07-19 2934
-
关于stm32浮点数常见问题分享不看肯定后悔2021-10-21 3042
-
嵌入式面试常见问题汇总,绝对实用2021-12-24 1480
-
Microsoft.Net常见问题集锦(DotNet面试题汇2009-06-09 561
-
Protel使用中的常见问题及解答2017-01-16 748
-
机器学习应用中的常见问题分类问题你了解多少2018-03-29 15511
-
ic设计工程师面试常见问题_20个面试常见问题盘点2018-04-27 24125
-
电气二次常见问题有哪些_40个电气二次常见问题盘点2018-05-31 5739
-
2018年数据科学和机器学习工具调查2018-06-07 4942
-
Airbnb机器学习和数据科学团队经验分享2018-07-07 4382
-
最常见的机器学习面试问题及其相应的回答2019-09-20 3606
-
目前机器学习面临的常见问题和挑战2020-10-23 17979
-
常见的MySQL高频面试题2021-02-08 2929
-
CAN总线常见问题解答2021-12-27 2391
全部0条评论

快来发表一下你的评论吧 !
