

基于单帧图像,云从科技3D人体技术创造最新世界纪录
电子说
描述
3 月 19 日,根据官方消息,云从科技基于单帧图像的 3D 人体重建技术同时在 Human3.6M、Surreal 和 UP-3D 三大数据集上创造了最新的世界纪录,将原有最低误差记录大幅降低 30%。
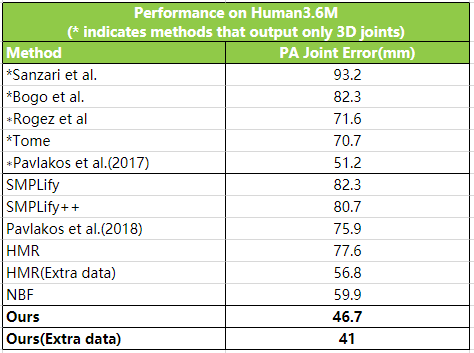
Human3.6M 数据集上对比

Surreal 数据集上对比

UP-3D 数据集上对比
3D 重建领域通常以误差(Error)作为衡量算法能力的主要指标,误差就是生成模型与实际图像的差别。一般来说,误差越低,精度越高,意味着技术的性能越好。
云从称,其 3D 人体重建技术全身精度误差(Surface Error)在 Surreal 上从 75.4 毫米降低到 52.7 毫米,关节精度误差(3D Joint Error)从 55.8 毫米降低到 40.1 毫米,Human3.6M 上的关节精度误差(3D Joint Error)从 59.9 毫米降低到 46.7 毫米,技术的执行速度从之前的上百毫秒降低到仅需 5 毫秒。
与传统关键点检测、3D 重建的区别是什么?
传统的人体关键点检测技术往往以 2D 的人体骨骼关节点检测形式出现,即通过技术预测 RGB 图像中人体的十几个关节点的坐标,一方面结果非常稀疏,将人体大为简化成骨骼的形式,另一方面结果往往只包含二维平面上的坐标预测,不能还原深度信息,因此无法体现纵深的感觉。
而基于单帧图像的 3D 重建技术不仅能输出骨骼关节点信息,更能同时预测大量的人体表面关键点信息,预测结果更加丰富,而且每个点的坐标都是 3D 的,能够体现不同躯干的纵深信息。
3D 关键点检测
传统 3D 重建技术大多需要连续的图像序列或是多视角的图像,在硬件设备上一般需要采用双目摄像机或者结构光摄像机等设备,因此在手机等便携设备上往往难以实现;另一方面,专用设备还会增加部署成本,增加大规模普及 3D 重建技术的难度。
上述突破是如何实现的?
据悉,该论文对人体具有丰富多样的姿态和穿着的特点,提出了一套全新的基于人体 3D 纵深预测的 3D 信息表征方式。通过对三原色图像(RGB,不含深度信息)的分析,预测人体的 3D 形态和姿势,并用 6 万多个点完整描绘人体,从而在人体重建技术上取得速度与精度的双突破,呈现出来的模型更精细,帧率高达到 200fps,原本由于受实时显示限制而无法实现的应用可以一一实现。
不过,基于单帧图像的 3D 重建技术对原始图像的需求放松的同时,对背后的技术提出了更难的挑战:技术需要从单帧图像中推理出人体或人脸的 3D 形态,并通过光学透视、阴影叠加等基本光学原则准确预测出各个关键点在 3D 空间的位置和朝向,从而得到人体的姿态或表情信息。
可探索的技术应用方向
人体姿态和服饰复杂多样,精度提升意味着对复杂场景的适应性更好,模型更接近真实的情况。如《阿凡达》、《阿丽塔》、漫威系列等电影中,都需要专用特效设备与面部贴点来完成精细的人像采集,基于单帧图像的 3D 人体 / 人脸重建技术,意味着可能颠覆电影视频的拍摄制作,同时降低工业级 3D 动画合成的门槛。
由于对输入图像的要求低,使 3D 重建技术将可以利用普通光学摄像头作为感知设备。例如,该技术将会使美颜 App 无需结构光摄像头也能具备高精准度的瘦身与动画合成功能。
目前,这项技术可通过重要人员影像重建、医疗仿真肢体打印、虚拟试衣、美颜化妆、表情姿态动画合成等应用场景在大型商场、直播平台、美颜软件、影视特效制作等行业普及。
-
天合光能再度刷新叠层组件功率世界纪录2025-06-13 769
-
天合光能钙钛矿晶体硅叠层技术再破世界纪录2025-04-11 755
-
中国“人造太阳”刷新世界纪录2025-01-21 834
-
天合光能创造高效n型HJT电池组件效率世界纪录2025-01-06 1158
-
我国“人造太阳”打破世界纪录2020-12-28 3833
-
通过3D打印技术的赵州桥,成功挑战了吉尼斯世界纪录2020-08-07 1203
-
德国科学家研发激光分光3D打印系统,创造新世界纪录2020-04-16 3448
-
依图ReID算法创下新世界纪录2020-04-03 3644
-
汉能薄膜发电集团宣布砷化镓薄膜单结电池转换效率达到29.1%再次刷新世界纪录2018-11-12 11106
-
基于局部姿态先验的深度图像3D人体运动捕获方法2018-01-03 994
-
德国高温燃料电池创世界纪录,寿命7万小时!2016-01-06 5123
-
固态量子存储器保真度世界纪录被刷新2012-05-14 850
-
酉阳10万人同跳摆手舞创吉尼斯世界纪录2010-10-12 1775
-
Eshow网络直播平台与世界吉尼斯世界纪录2010-08-17 5077
全部0条评论

快来发表一下你的评论吧 !
