

网络爬虫的基本工作流程
电子说
1.3w人已加入
描述
网络爬虫的基本工作流程
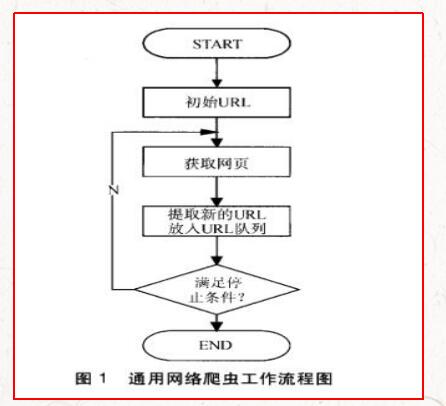
通用网络爬虫根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器去掉页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。
主题爬虫工作流程
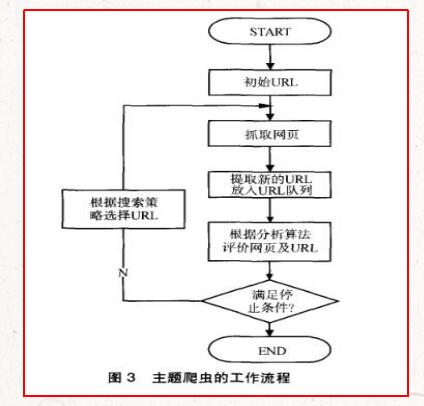
主题爬虫需要根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它会根据一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页都会被系统存储,经过一定的分析、过滤,然后建立索引,以便用户查询和检索;这一过程所得到的分析结果可以对以后的抓取过程提供反馈和指导。其工作流程如图3所示。
深度网络爬虫工作流程
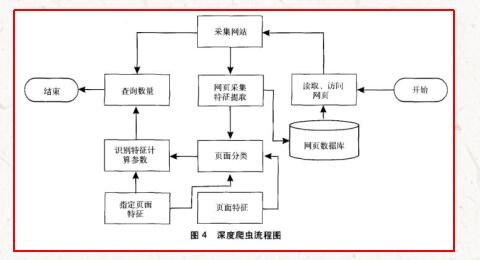
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎难以发现的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎由于技术限制而搜集不到这些高质量、高权威的信息。这些信息通常隐藏在深度Web页面的大型动态数据库中,涉及数据集成、中文语义识别等诸多领域。如此庞大的信息资源如果没有合理的、高效的方法去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
电气CAD文件中高效的工作流程2009-12-04 0
-
帮忙分析下这个设计的工作流程2012-12-07 0
-
AndroidWifi工作流程2016-11-02 0
-
在虚拟环境网络研讨会中使用ArcGIS Pro存档GIS工作流程?2018-09-07 0
-
Simulink是什么?Simulink的工作流程是怎样进行的?2021-07-09 0
-
AS068工作流程是怎样的?2021-12-07 0
-
python网络爬虫概述2022-03-21 0
-
财务管理工作流程图2009-03-30 8334
-
测试工程师工作流程有哪些2018-10-03 7738
-
雷电的4K工作流程2020-05-31 2437
-
工作流程图怎么用?有哪些绘制工作流程图的软件2020-07-28 3564
-
机器视觉系统的组成及工作流程2021-04-19 1057
-
卷积神经网络算法流程 卷积神经网络模型工作流程2023-08-21 2887
全部0条评论

快来发表一下你的评论吧 !
