

端到端驾驶模型的发展历程
电子说
描述
在搭建无人车时,我和小伙伴们的主要工作是建立一个驾驶模型。所谓的驾驶模型是控制无人车行驶的软件,在功能上类似于一名司机,其输入为车辆状态、周围环境信息,输出为对无人车的控制信号。在所有驾驶模型中,最简单直接的是端到端驾驶模型。端到端驾驶模型直接根据车辆状态和外部环境信息得出车辆的控制信号。从输入端(传感器的原始数据)直接映射到输出端(控制信号),中间不需要任何人工设计的特征。通常,端到端驾驶模型使用一个深度神经网络来完成这种映射,网络的所有参数为联合训练而得。这种方法因它的简洁高效而引人关注。
端到端驾驶模型的发展历程
寻找端到端驾驶模型的最早尝试,至少可以追溯到1989年的ALVINN模型【2】。ALVINN是一个三层的神经网络,它的输入包括前方道路的视频数据、激光测距仪数据,以及一个强度反馈。对视频输入,ALVINN只使用了其蓝色通道,因为在蓝色通道中,路面和非路面的对比最为强烈。对测距仪数据,神经元的激活强度正比于拍摄到的每个点到本车的距离。强度反馈描述的是在前一张图像中,路面和非路面的相对亮度。ALVINN的输出是一个指示前进方向的向量,以及输入到下一时刻的强度反馈。具体的网络结构如图一所示。
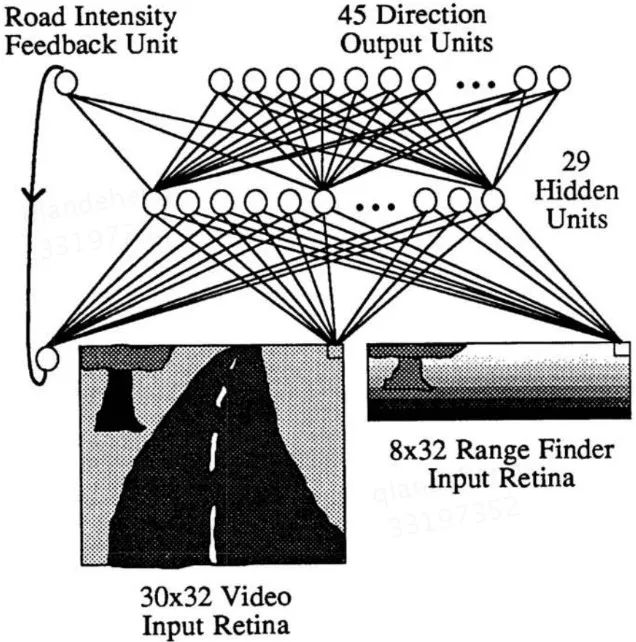
图一:ALVINN的网络结构示意图,图片引用于【2】
在训练ALVINN时,其输出的真值被设为一个分布。该分布的中心位置对应于能让车辆行驶到前方7米处的道路中心的那个方向,分布由中心向两边迅速衰减到0。此外,在训练过程中使用了大量合成的道路数据,用于提高ALVINN的泛化能力。该模型成功地以0.5米每秒的速度开过一个400米长的道路。来到1995年,卡内基梅隆大学在ALVINN的基础上通过引入虚拟摄像头的方法,使ALVINN能够检测到道路和路口【3】。另外,纽约大学的Yann LeCun在2006年给出了一个6层卷积神经网络搭建的端到端避障机器人【4】。
近年来,比较有影响力的工作是2016年NVIDIA开发的PilotNet【5】。如图二所示,该模型使用卷积层和全连层从输入图像中抽取特征,并给出方向盘的角度(转弯半径)。相应地,NVIDIA还给出了一套用于实车路测的计算平台NVIDIA PX 2。在NVIDIA的后续工作中,他们还对PilotNet内部学到的特征进行了可视化,发现PilotNet能自发地关注到障碍物、车道线等对驾驶具有重要参考价值的物体【6】。
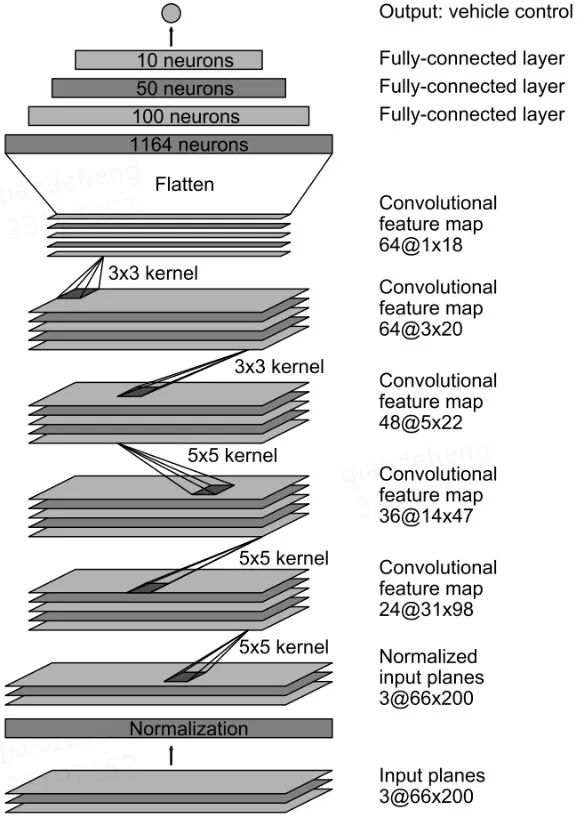
图二:PilotNet的网络结构示意图,图片引用于【5】
PilotNet之后的模型如雨后春笋般涌现。一个重要的代表是加州大学伯克利分校提出的FCN-LSTM网络【7】。如图三所示,该网络首先通过全卷积网络将图像抽象成一个向量形式的特征,然后通过长短时记忆网络将当前的特征和之前的特征融合到一起,并输出当前的控制信号。值得指出的是,该网络使用了一个图像分割任务来辅助网络的训练,用更多监督信号使网络参数从“无序”变为“有序”,这是一个有趣的尝试。以上这些工作都只关注无人车的“横向控制”,也就是方向盘的转角。罗彻斯特大学提出的Multi-modal multi-task网络【8】在前面工作的基础上,不仅给出方向盘的转角,而且给出了预期速度,也就是包含了“纵向控制”,因此完整地给出了无人车所需的最基本控制信号,其网络结构如图四所示。
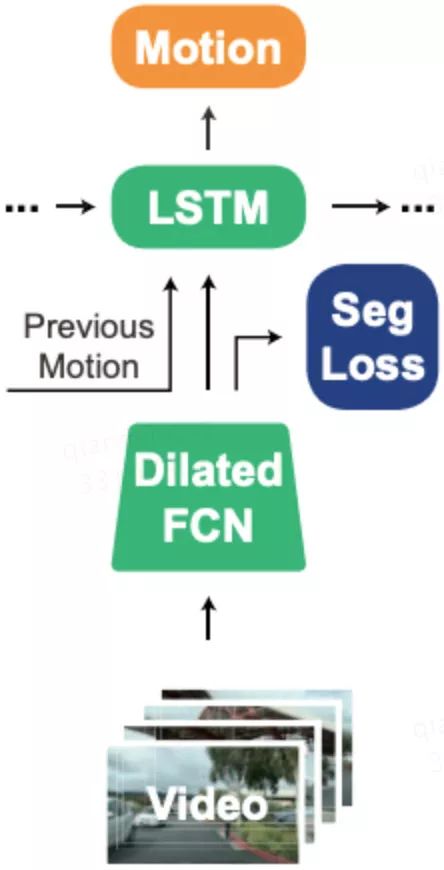
图三:FCN-LSTM网络结构示意图,图片引用于【7】
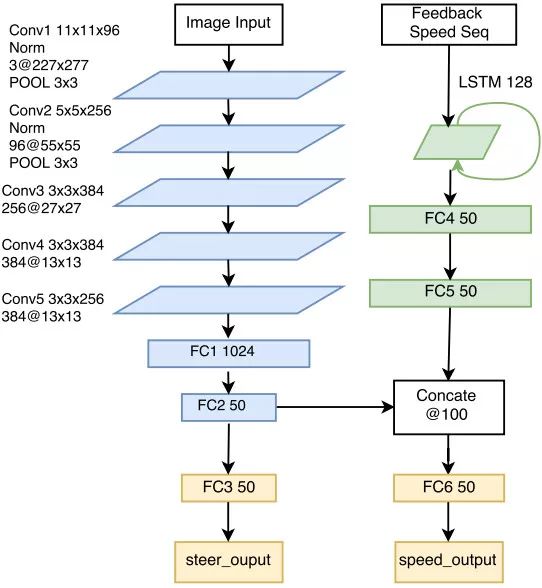
图四:Multi-modal multi-task网络结构示意图,图片引用于【8】
北京大学提出的ST-Conv + ConvLSTM + LSTM网络更加精巧【9】。如图五所示,该网络大致分成两部分,即特征提取子网络和方向角预测子网络。特征提取子网络利用了时空卷积,多尺度残差聚合,卷积长短时记忆网络等搭建技巧或模块。方向角预测子网络主要做时序信息的融合以及循环。该网络的作者还发现,无人车的横向控制和纵向控制具有较强的相关性,因此联合预测两种控制能更有效地帮助网络学习。

图五:ST-Conv+ConvLSTM+LSTM网络结构示意图,图片引用于【9】
端到端驾驶模型的特点
讲到这里,大家也许已经发现,端到端模型得益于深度学习技术的快速发展,朝着越来越精巧的方向不断发展。从最初的三层网络,逐步武装上了最新模块和技巧。在这些最新技术的加持下,端到端驾驶模型已经基本实现了直道、弯道行驶,速度控制等功能。为了让大家了解目前的端到端模型发展现状,我们从算法层面将这种模型与传统模型做一个简单对比,见下表一:
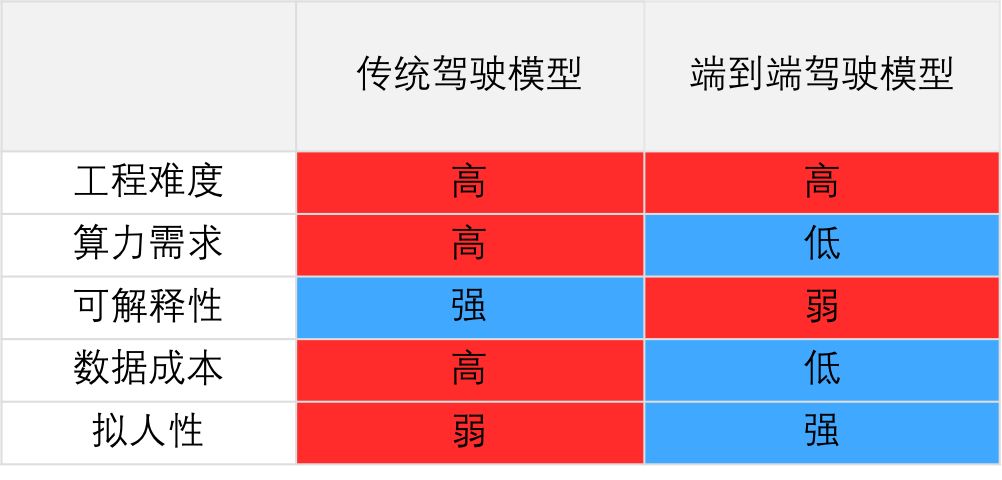
表一:传统驾驶模型和端到端模型对比
传统的模型一般将驾驶任务分割成多个子模块,例如感知、定位、地图、规划、控制等等。每个子模块完成特定的功能,某个模块的输出作为其它模块的输入,模块间相互连接,形成有向图的结构。这种方法需要人工解耦无人车的驾驶任务,设计各个子模块,而子模块的数量甚至高达上千个,导致这项工作费时费力,维护成本高昂。如此多的子模块又对车载计算平台提出了极高的要求,需要强大的算力保证各个模块能快速响应环境的变化。
此外,传统驾驶模型往往依赖高精地图,导致其数据成本高昂。这类模型通过规则化的逻辑来做无人车的运动规划与控制,又导致其驾驶风格的拟人化程度弱,影响乘坐的舒适性。作为对比,端到端模型以其简单、易用、成本低、拟人化等特点表现出很强的优势。
人们通常认为端到端驾驶模型和模块化的传统模型之间是彼此对立的,有了模块化模型就不需要端到端了。但在无人配送领域,我认为两者应该是互补的。首先,无人配送车“小、轻、慢、物”的特点【10】极大降低了其安全风险。使端到端模型的部署成为可能。然后,端到端模型可以很好地处理常见场景,而且功耗低。模块化的方法能覆盖更多场景,但功耗高。因此,一个很有价值的方向应该是联合部署端到端模型和模块化模型。在常见场景中使用端到端,在复杂场景中,切换到模块化模型。这样,我们可以在保证整体模型性能的同时,尽最大可能降低配送车的功耗。
那么是不是很快就能见到端到端驾驶模型控制的无人配送车了呢?其实,现在端到端驾驶模型还处在研究阶段。我从自己的实际工作经验中总结出以下几个难点:
1、端到端驾驶模型因其近乎黑盒的特点导致调试困难。
由于端到端模型是作为一个整体工作的,因此当该模型在某种情况下失败时,我们几乎无法找到模型中应该为这次失败负责的“子模块”,也就没办法有针对性地调优。当遇到失败例子时,通常的做法只能是添加更多的数据,期待重新训练的模型能够在下一次通过这个例子。
2、端到端驾驶模型很难引入先验知识。
目前的端到端模型更多地是在模仿人类驾驶员动作,但并不了解人类动作背后的规则。想要通过纯粹数据驱动的方式让模型学习诸如交通规则、文明驾驶等规则比较困难,还需要更多的研究。
3、端到端驾驶模型很难恰当地处理长尾场景。
对于常见场景,我们很容易通过数据驱动的方式教会端到端模型正确的处理方法。但真实路况千差万别,我们无法采集到所有场景的数据。对于模型没有见过的场景,模型的性能往往令人担忧。如何提高模型的泛化能力是一个亟待解决的问题。
4、端到端驾驶模型通常通过模仿人类驾驶员的控制行为来学习驾驶技术。
但这种方式本质上学到的是驾驶员的“平均控制信号”,而“平均控制信号”甚至可能根本就不是一个“正确”的信号。
例如在一个可以左拐和右拐的丁字路口,其平均控制信号——“直行”——就是一个错误的控制信号。因此,如何学习人类驾驶员的控制策略也有待研究。
在这个问题上,我和小伙伴们一起做了一点微小的工作,在该工作中,我们认定驾驶员在不同状态下的操作满足一个概率分布。我们通过学习这个概率分布的不同矩来估计这个分布。这样一来,驾驶员的控制策略就能很好地通过其概率分布的矩表达出来,避免了简单求“平均控制信号”的缺点。该工作已被 ROBIO 2018 接收。
端到端驾驶模型中常用方法
为了解决上面提到的各种问题,勇敢的科学家们提出了许多方法,其中最值得期待的要数深度学习技术【11】和强化学习技术【12】了。随着深度学习技术的不断发展,相信模型的可解释性、泛化能力会进一步提高。这样以来,我们或许就可以有针对性地调优网络,或者在粗糙的仿真下、在较少数据的情况下,成功地泛化到实车场景、长尾场景。强化学习这项技术在近年来取得了令人惊叹的成就。通过让无人车在仿真环境中进行强化学习,也许可以获得比人类驾驶员更优的控制方法也未可知。此外,迁移学习、对抗学习、元学习等技术高速发展,或许也会对端到端驾驶模型产生巨大影响。
我对端到端驾驶模型今后的发展充满了期待。“Two roads diverged in a wood, and I took the one less traveled by”【13】。
-
针对端到端自主驾驶模型的简单对抗实例2019-03-19 3326
-
如何基于深度神经网络设计一个端到端的自动驾驶模型?2019-04-29 5712
-
理想汽车自动驾驶端到端模型实现2024-04-12 967
-
小鹏汽车发布端到端大模型2024-05-21 1194
-
实现自动驾驶,唯有端到端?2024-08-12 2228
-
智驾进程发力?小鹏、蔚来端到端模型上车2024-09-26 994
-
连接视觉语言大模型与端到端自动驾驶2024-11-07 1174
-
自动驾驶中基于规则的决策和端到端大模型有何区别?2025-04-13 3514
-
一文带你厘清自动驾驶端到端架构差异2025-05-08 854
-
为什么自动驾驶端到端大模型有黑盒特性?2025-07-04 661
-
端到端发展趋势下,云算力如何赋能智能驾驶技术跃迁?2025-09-08 710
-
自动驾驶端到端大模型为什么会有不确定性?2025-09-28 636
-
西井科技端到端自动驾驶模型获得国际认可2025-10-15 1136
-
如何训练好自动驾驶端到端模型?2025-12-08 1162
-
Nullmax感知规划端到端大模型进化提速2025-12-22 280
全部0条评论

快来发表一下你的评论吧 !
