

循环神经网络RNN学习笔记
电子说
描述
一、循环神经网络简介
循环神经网络,英文全称:Recurrent Neural Network,或简单记为RNN。需要注意的是,递归神经网络(Recursive Neural Network)的简写也是RNN,但通常RNN指循环神经网络。循环神经网络是一类用于处理序列数据的神经网络。它与其他神经网络的不同是,RNN可以更好的去处理序列的信息,即认准了前后的输入之间存在关系。在NLP中,去理解一整句话,孤立的理解组成这句话的词显然是不够的,我们需要整体的处理由这些词连接起来的整个序列。
如:(1) 我饿了,我要去食堂___。(2) 我饭卡丢了,我要去食堂___。很显然,第一句话是想表明去食堂就餐,而第二句则很有可能因为刚吃过饭,发现饭卡不见了,去食堂寻找饭卡。而在此之前,我们常用的语言模型是N-Gram,无论何种语境,可能去食堂大概率匹配的是“吃饭”而不在乎之前的信息。RNN就解决了N-Gram的缺陷,它在理论上可以往前(后)看任意多个词。
此文是我在学习RNN中所做的笔记,参考资料在文末提及。
二、循环神经网络分类
a.简单的MLP神经网络
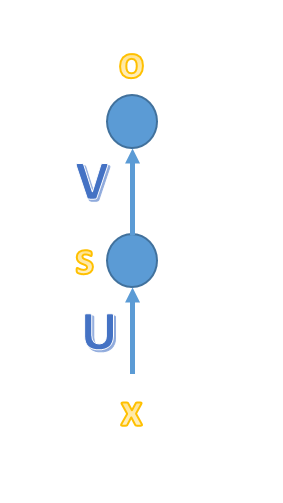
简单的MLP三层网络模型,x、o为向量,分别表示输入层、输出层的值;U、V为矩阵,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵。
b.循环神经网络
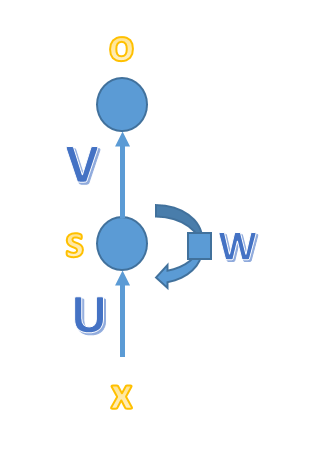
与简单的MLP神经网络不容的是,循环神经网络的隐藏层的值s不仅取决于当前的这次输入x,还取决于上一次隐藏层的值s。权重就在W就是隐藏层上一次的值作为这一次输入的输入的权重。将上图展开:
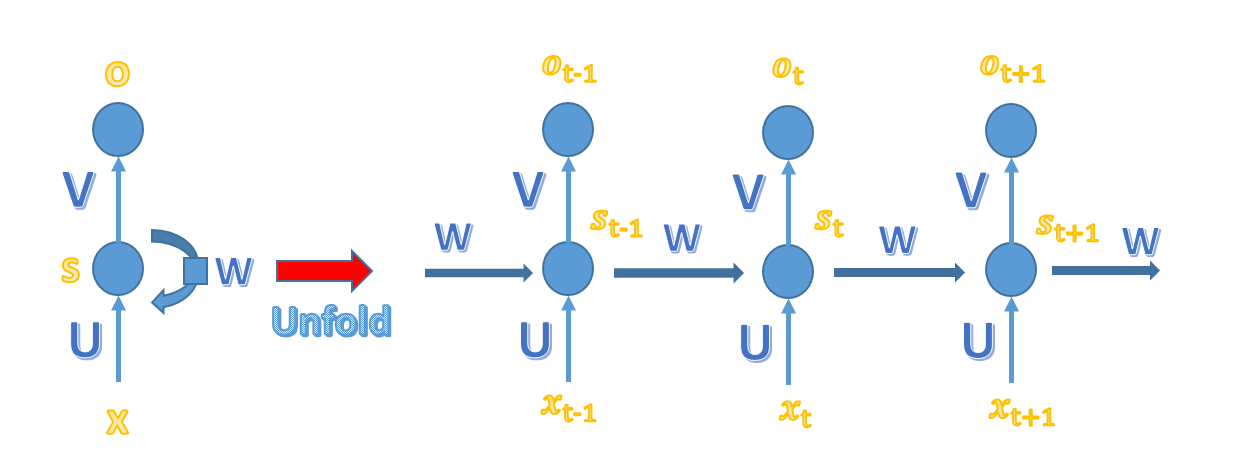
由上图可知以下公式,其中 V 是输出层权重矩阵,g 是激活函数;U 是输入x的权重矩阵,W 是上一次的值 st-1 作为这一次的输入的权重矩阵,f 是激活函数。
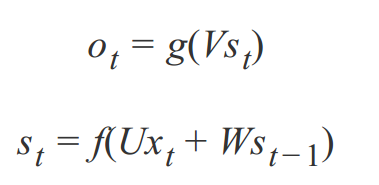
反复带入,即可得到:
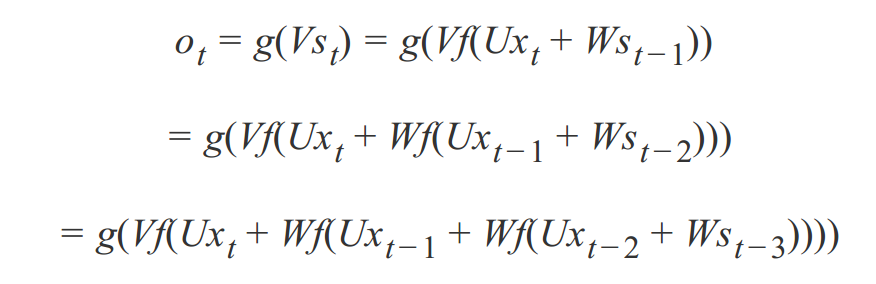
可见,循环神经网络的输出值 ot 受之前的输出值 xt 、xt-1、xt-2 所影响。
c. 双向循环神经网络
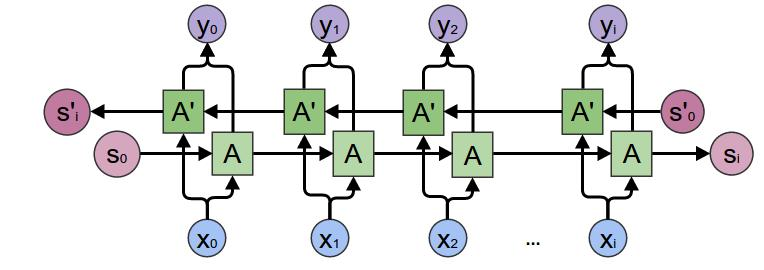
双向循环神经网络的计算方法:
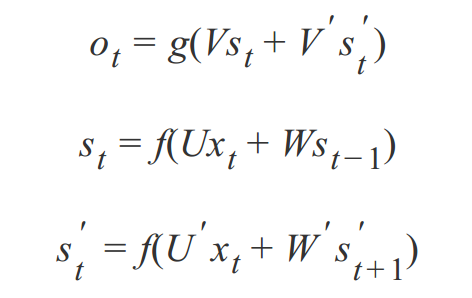
从上面三个公式可以看出: 正向计算时,隐藏层的值与 st 和 st-1 有关,而反向计算时,隐藏层的值与 s't 和 s't+1 有关;最终的输出取决于正向与反向计算的加和。
d、深度循环神经网络
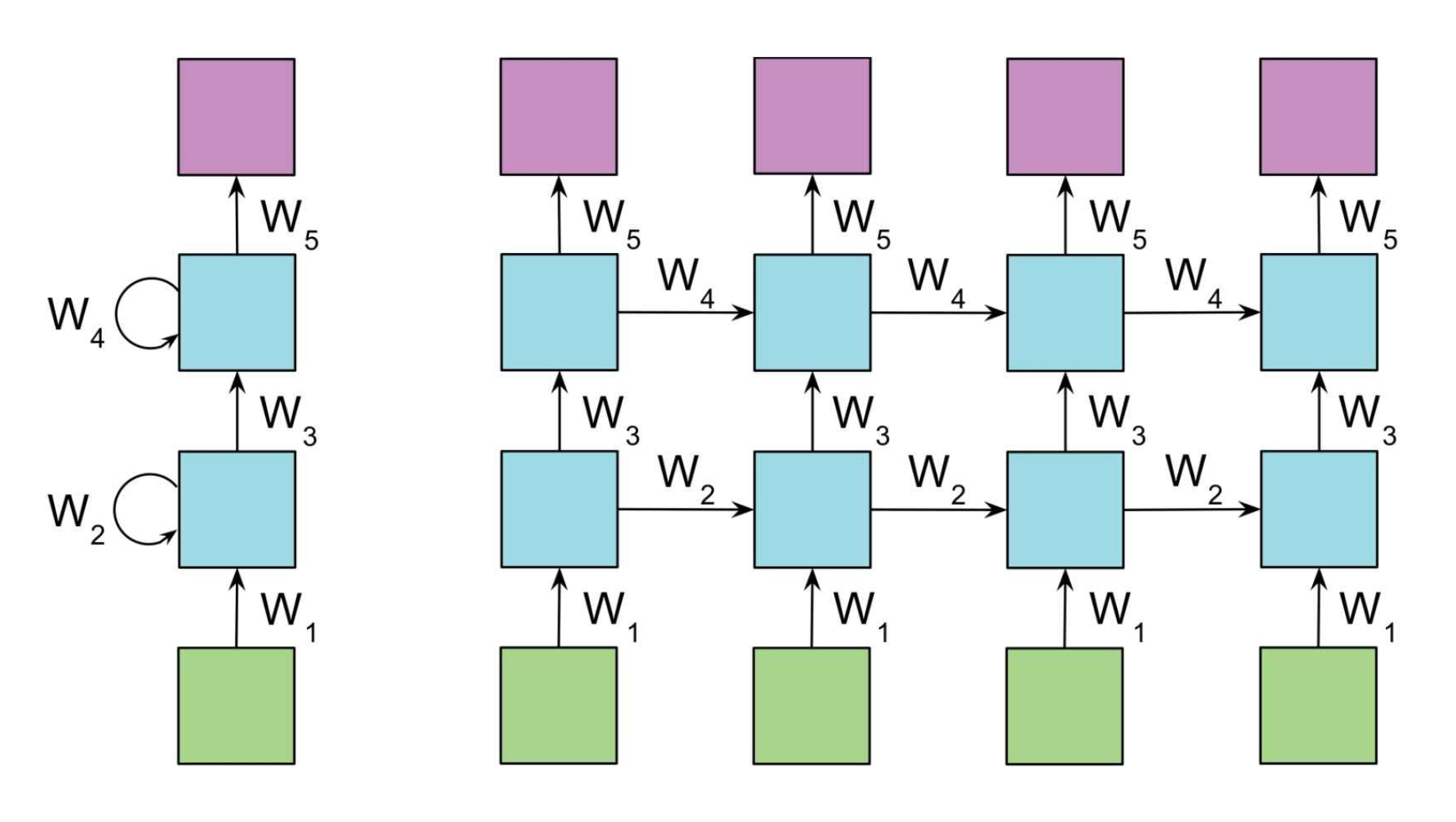
此前介绍的循环神经网络只有一个输入层、一个循环层和一个输出层。与全连接神经网络以及卷积神经网络一样,可以把它推广到任意多个隐藏层的情况,得到深层循环神经网络。深度循环神经网络包含多个隐藏层(上图为了表示清楚,只列举了2层),并且也继承了双向循环神经网络的特点。由之前的公式类推,我们可以得到深度循环神经网络的计算方式:
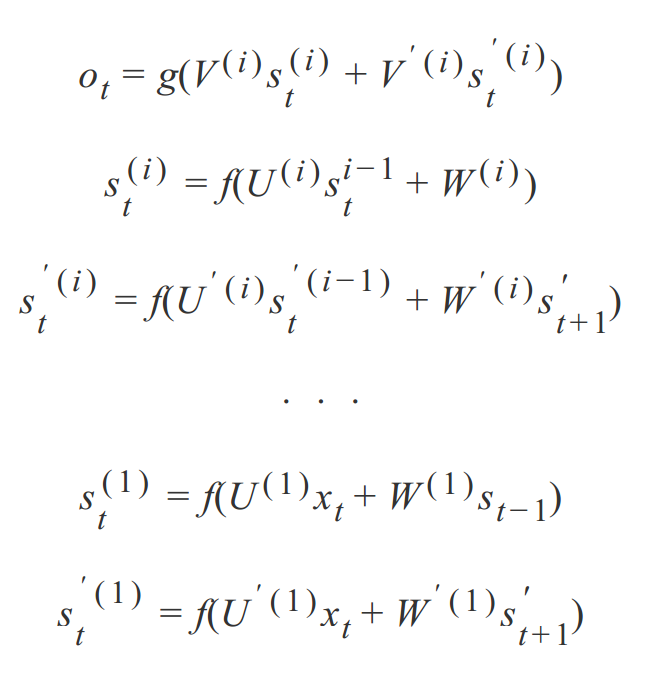
深层神经网络有3个方案:第一种叫做 Deep Input-to-Hidden Function,它在循环层之前加入多个普通的全连接层,将输入向量进行多层映射之后再送入循环层进行处理。第二种方案是 Deep Hidden-to-Hidden Transition,它使用多个循环层,这和前馈神经网络类似,唯一不同的是计算隐含层输出的时候需要利用本隐含层上一时刻的值。第三种方案是 Deep Hidden-to-Output Function,它在循环层到输出层之间加入多个全连接层,这与第一种情况类似。上面公式展示的应为第二种情况。
由于循环层一般用 tanh 作为激活函数,层次过多之后会导致梯度消失问题。后面会提及。
三、网络的训练及BPTT
循环神经网络的输入是序列数据,每个训练样本是一个时间序列,包含多个相同维度的向量。网络的参数如何通过训练确定?这里就要使用解决循环神经网络训练问题的 Back Propagation Through Time 算法,简称BPTT。
循环神经网络的每个训练样本是一个时间序列,同一个训练样本前后时刻的输入值之间有关联,每个样本的序列长度可能不相同。训练时先对这个序列中的每个时刻的输入值进行正向传播,再通过反向传播计算出参数的梯度值并更新参数。
它包含三个步骤:(1)正向计算每个神经元的输出值;(2)反向计算每个神经元的误差项 δj ,它是误差函数E 对神经元 j 的加权输入 netj 的偏导数;(3)计算每个权重的梯度;(4)用随机梯度下降算法更新权重。具体的算法推导我会在之后的笔记整理中总结。
四、梯度爆炸、梯度消失
循环神经网络在进行反向传播时也面临梯度消失或者梯度爆炸问题,这种问题表现在时间轴上。如果输入序列的长度很长,人们很难进行有效的参数更新。通常来说梯度爆炸更容易处理一些。因为梯度爆炸时,我们的程序会收到NaN的错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
(1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以多开梯度消失的区域。
(2) 使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。
(3) 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和 门控循环单元 (GRU),这是最流行的做法。
五、练手项目
可以参考github上比较出名的char_RNN的代码来提高自己的兴趣。该项目就是通过训练语料来自己写诗、歌、文。
下图是我的训练结果:
(1) 一首诗,这首通过RNN训练写出的诗还是不错的。“秋”与“春”是对应的,描绘的是诗人在秋日,欣赏的山中风景。不禁感叹,自己的青春已去,自己也已经白首,吟唱着这首诗(编不下去了…)。
(2) 通过自己找的《三体》全集,来训练出的小说片段。可以看到,只能模仿句式,不能有准确表达,所以逻辑不通的,但是形式是很像刘慈欣的写法了。
- 相关推荐
- 热点推荐
- 神经网络
-
LSTM神经网络与传统RNN的区别2024-11-13 1751
-
rnn是什么神经网络2024-07-05 2016
-
什么是RNN(循环神经网络)?RNN的基本原理和优缺点2024-07-04 8458
-
卷积神经网络与循环神经网络的区别2024-07-03 7140
-
什么是RNN (循环神经网络)?2024-02-29 5413
-
循环神经网络(RNN)和(LSTM)初学者指南2019-02-05 1308
-
循环神经网络(RNN)的详细介绍2018-05-11 14641
全部0条评论

快来发表一下你的评论吧 !
