

你了解Linux 3.10 kernel bridge的转发逻辑?
嵌入式技术
描述
前分析过linux kernel 2.6.32的bridge转发逻辑,下面分析一下linux kernel 3.10的bridge转发逻辑。这样正是CentOS 5和CentOS 7对应的内核。3.10 kernel中bridge逻辑的最大改变就是增加了vlan处理逻辑以及brdige入口函数的设置。
1. netdev_rx_handler_register
在分析之前首先要介绍一个重要函数:netdev_rx_handler_register,这个函数是2.6内核所没有的。
netdev_rx_handler_register
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/*
* dev: 要注册接收函数的dev
* rx_handler: 要注册的接收函数
* rx_handler_data: 指向rx_handler_data使用的数据
*/
int netdev_rx_handler_register(struct net_device *dev,
rx_handler_func_t *rx_handler,
void *rx_handler_data)
{
ASSERT_RTNL();
if (dev->rx_handler)
return -EBUSY;
/* Note: rx_handler_data must be set before rx_handler */
rcu_assign_pointer(dev->rx_handler_data, rx_handler_data);
rcu_assign_pointer(dev->rx_handler, rx_handler);
return 0;
}
这个函数可以给设备(net_device)注册接收函数,然后在__netif_receive_skb函数中根据接收skb的设备接口,再调用这个被注册的接收函数。比如为网桥下的接口注册br_handle_frame函数,为bonding接口注册bond_handle_frame函数。这相对于老式的网桥处理更灵活,有了这个机制也可以在模块中自行注册处理函数。比如3.10中的openvswitch(OpenvSwitch在3.10已经合入了内核)创建netdev vport的函数netdev_create。
netdev_create
1
2
3
4
5
6
7
static struct vport *netdev_create(const struct vport_parms *parms)
{
struct vport *vport;
/....../
err = netdev_rx_handler_register(netdev_vport->dev, netdev_frame_hook,vport);
/....../
}
这个函数在创建netdev vport时将设备的接收函数设置为netdev_frame_hook函数,这也是整个openvswitch的入口函数,如果查看OpenvSwitch的源码可以看到当安装于2.6内核时这里是替换掉bridge的br_handle_frame_hook函数,从而由bridge逻辑进入OpenvSwitch逻辑。
2. Bridge转发逻辑分析
还是先从netif_receive_skb函数分析,这个函数算是进入协议栈的入口。
netif_receive_skb
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
int netif_receive_skb(struct sk_buff *skb)
{
int ret;
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
rcu_read_lock();
/*RPS逻辑处理,现在内核中使用了RPS机制, 将报文分散到各个cpu的接收队列中进行负载均衡处理*/
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
}
#endif
ret = __netif_receive_skb(skb);
rcu_read_unlock();
return ret;
}
netif_receive_skb只是对数据包进行了RPS的处理,然后调用__netif_receive_skb。
__netif_receive_skb并没有其他多余的处理逻辑,主要调用 __netif_receive_skb_core,这个函数才真正相当于2.6内核的netif_receive_skb。以下代码省略了和bridge无关的逻辑。
__netif_receive_skb_core
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct net_device *orig_dev;
struct net_device *null_or_dev;
bool deliver_exact = false;
int ret = NET_RX_DROP;
__be16 type;
/*......*/
orig_dev = skb->dev;
skb_reset_network_header(skb);
pt_prev = NULL;
skb->skb_iif = skb->dev->ifindex;
/*ptype_all协议处理,tcpdump抓包就在这里*/
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
/*调用接收设备的rx_handler*/
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
/*根据 skb->protocol传递给上层协议*/
type = skb->protocol;
list_for_each_entry_rcu(ptype,&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type && (ptype->dev == null_or_dev || ptype->dev == skb->dev ||ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
if (pt_prev) {
if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
goto drop;
else
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
} else {
drop:
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
ret = NET_RX_DROP;
}
out:
return ret;
}
如果一个dev被添加到一个bridge(做为bridge的一个接口),的这个接口设备的rx_handler被设置为br_handle_frame函数,这是在br_add_if函数中设置的,而br_add_if (net/bridge/br_if.c)是在向网桥设备上添加接口时设置的。进入br_handle_frame也就进入了bridge的逻辑代码。
br_add_if
1
2
3
4
5
6
int br_add_if(struct net_bridge *br, struct net_device *dev)
{
/*......*/
err = netdev_rx_handler_register(dev, br_handle_frame, p);
/*......*/
}
br_handle_frame
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
rx_handler_result_t br_handle_frame(struct sk_buff **pskb)
{
struct net_bridge_port *p;
struct sk_buff *skb = *pskb;
const unsigned char *dest = eth_hdr(skb)->h_dest;
br_should_route_hook_t *rhook;
if (unlikely(skb->pkt_type == PACKET_LOOPBACK))
return RX_HANDLER_PASS;
if (!is_valid_ether_addr(eth_hdr(skb)->h_source))
goto drop;
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
return RX_HANDLER_CONSUMED;
/*获取dev对应的bridge port*/
p = br_port_get_rcu(skb->dev);
/*特殊目的mac地址的处理*/
if (unlikely(is_link_local_ether_addr(dest))) {
/*
* See IEEE 802.1D Table 7-10 Reserved addresses
*
* Assignment Value
* Bridge Group Address 01-80-C2-00-00-00
* (MAC Control) 802.3 01-80-C2-00-00-01
* (Link Aggregation) 802.3 01-80-C2-00-00-02
* 802.1X PAE address 01-80-C2-00-00-03
*
* 802.1AB LLDP 01-80-C2-00-00-0E
*
* Others reserved for future standardization
*/
switch (dest[5]) {
case 0x00: /* Bridge Group Address */
/* If STP is turned off,then must forward to keep loop detection */
if (p->br->stp_enabled == BR_NO_STP)
goto forward;
break;
case 0x01: /* IEEE MAC (Pause) */
goto drop;
default:
/* Allow selective forwarding for most other protocols */
if (p->br->group_fwd_mask & (1u << dest[5]))
goto forward;
}
/* LOCAL_IN hook点,注意经过这个hook点并不代表发送到主机协议栈(只有特殊目的mac 01-80-C2才会走到这里)*/
if (NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN, skb, skb->dev,
NULL, br_handle_local_finish)) {
return RX_HANDLER_CONSUMED; /* consumed by filter */
} else {
*pskb = skb;
return RX_HANDLER_PASS; /* continue processing */
}
}
/*转发逻辑*/
forward:
switch (p->state) {
case BR_STATE_FORWARDING:
rhook = rcu_dereference(br_should_route_hook);
if (rhook) {
if ((*rhook)(skb)) {
*pskb = skb;
return RX_HANDLER_PASS;
}
dest = eth_hdr(skb)->h_dest;
}
/* fall through */
case BR_STATE_LEARNING:
/*skb的目的mac和bridge的mac一样,则将skb发往本机协议栈*/
if (ether_addr_equal(p->br->dev->dev_addr, dest))
skb->pkt_type = PACKET_HOST;
/*NF_BR_PRE_ROUTING hook点*/
NF_HOOK(NFPROTO_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,br_handle_frame_finish);
break;
default:
drop:
kfree_skb(skb);
}
return RX_HANDLER_CONSUMED;
}
经过NF_BR_LOCAL_IN hook点会执行br_handle_local_finish函数。
br_handle_local_finish
1
2
3
4
5
6
7
8
9
10
static int br_handle_local_finish(struct sk_buff *skb)
{
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
u16 vid = 0;
/*获取skb的vlan id(3.10的bridge支持vlan)*/
br_vlan_get_tag(skb, &vid);
/*更新bridge的mac表,注意vlan id也是参数,说明每个vlan有一个独立的mac表*/
br_fdb_update(p->br, p, eth_hdr(skb)->h_source, vid);
return 0; /* process further */
}
经过NF_BR_PRE_ROUTING hook点会执行br_handle_frame_finish函数。
br_handle_frame_finish
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
int br_handle_frame_finish(struct sk_buff *skb)
{
const unsigned char *dest = eth_hdr(skb)->h_dest;
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
struct net_bridge *br;
struct net_bridge_fdb_entry *dst;
struct net_bridge_mdb_entry *mdst;
struct sk_buff *skb2;
u16 vid = 0;
if (!p || p->state == BR_STATE_DISABLED)
goto drop;
/*这个判断主要是vlan的相关检查,如是否和接收接口配置的vlan相同*/
if (!br_allowed_ingress(p->br, nbp_get_vlan_info(p), skb, &vid))
goto out;
/* insert into forwarding database after filtering to avoid spoofing */
br = p->br;
/*更新转发数据库*/
br_fdb_update(br, p, eth_hdr(skb)->h_source, vid);
/*多播mac的处理*/
if (!is_broadcast_ether_addr(dest) && is_multicast_ether_addr(dest) &&
br_multicast_rcv(br, p, skb))
goto drop;
if (p->state == BR_STATE_LEARNING)
goto drop;
BR_INPUT_SKB_CB(skb)->brdev = br->dev;
/* The packet skb2 goes to the local host (NULL to skip). */
skb2 = NULL;
/*如果网桥被设置为混杂模式*/
if (br->dev->flags & IFF_PROMISC)
skb2 = skb;
dst = NULL;
/*如果skb的目的mac是广播*/
if (is_broadcast_ether_addr(dest))
skb2 = skb;
else if (is_multicast_ether_addr(dest)) { /*多播*/
mdst = br_mdb_get(br, skb, vid);
if (mdst || BR_INPUT_SKB_CB_MROUTERS_ONLY(skb)) {
if ((mdst && mdst->mglist) ||
br_multicast_is_router(br))
skb2 = skb;
br_multicast_forward(mdst, skb, skb2);
skb = NULL;
if (!skb2)
goto out;
} else
skb2 = skb;
br->dev->stats.multicast++;
} else if ((dst = __br_fdb_get(br, dest, vid)) && dst->is_local) {/*目的地址是本机mac,则发往本机协议栈*/
skb2 = skb;
/* Do not forward the packet since it's local. */
skb = NULL;
}
if (skb) {
if (dst) {
dst->used = jiffies;
br_forward(dst->dst, skb, skb2); //转发给目的接口
} else
br_flood_forward(br, skb, skb2); //找不到目的接口则广播
}
if (skb2)
return br_pass_frame_up(skb2); //发往本机协议栈
out:
return 0;
drop:
kfree_skb(skb);
goto out;
}
{C}
我们先看发往本机协议栈的函数br_pass_frame_up。
br_pass_frame_up
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static int br_pass_frame_up(struct sk_buff *skb)
{
struct net_device *indev, *brdev = BR_INPUT_SKB_CB(skb)->brdev;
struct net_bridge *br = netdev_priv(brdev);
//更新统计计数(略)
/* Bridge is just like any other port. Make sure the
* packet is allowed except in promisc modue when someone
* may be running packet capture.
*/
if (!(brdev->flags & IFF_PROMISC) && !br_allowed_egress(br, br_get_vlan_info(br), skb)) {
kfree_skb(skb); //如果不是混杂模式且vlan处理不合要求则丢弃
return NET_RX_DROP;
}
//vlan处理逻辑
skb = br_handle_vlan(br, br_get_vlan_info(br), skb);
if (!skb)
return NET_RX_DROP;
indev = skb->dev;
skb->dev = brdev; //重点,这里修改了skb->dev为bridge
//经过NF_BR_LOCAL_IN再次进入协议栈
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN, skb, indev, NULL,
netif_receive_skb);
}
{C}
再次进入netif_receive_skb,由于skb-dev被设置成了bridge,而bridge设备的rx_handler函数是没有被设置的,所以就不会再次进入bridge逻辑,而直接进入了主机上层协议栈。
下面看转发逻辑,转发逻辑主要在br_forward函数中,而br_forward主要调用__br_forward函数。
__br_forward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
struct net_device *indev;
//vlan处理
skb = br_handle_vlan(to->br, nbp_get_vlan_info(to), skb);
if (!skb)
return;
indev = skb->dev;
skb->dev = to->dev; //skb->dev设置为出口设备dev
skb_forward_csum(skb);
//经过NF_BR_FORWARD hook点,调用br_forward_finish
NF_HOOK(NFPROTO_BRIDGE, NF_BR_FORWARD, skb, indev, skb->dev,
br_forward_finish);
}
{C}
br_forward_finish
1
2
3
4
5
int br_forward_finish(struct sk_buff *skb)
{
//经过NF_BR_POST_ROUTING hook点,调用br_dev_queue_push_xmit
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev, br_dev_queue_push_xmit);
}
{C}
br_dev_queue_push_xmit
1
2
3
4
5
6
7
8
9
10
11
12
int br_dev_queue_push_xmit(struct sk_buff *skb)
{
/* ip_fragment doesn't copy the MAC header */
if (nf_bridge_maybe_copy_header(skb) || (packet_length(skb) > skb->dev->mtu && !skb_is_gso(skb))) {
kfree_skb(skb);
} else {
skb_push(skb, ETH_HLEN);
br_drop_fake_rtable(skb);
dev_queue_xmit(skb); //发送到链路层
}
return 0;
}
Skb进入dev_queue_xmit就会调用相应设备驱动的发送函数。也就出了bridge逻辑。所以整个3.10kernel的bridge转发逻辑如下图所示:
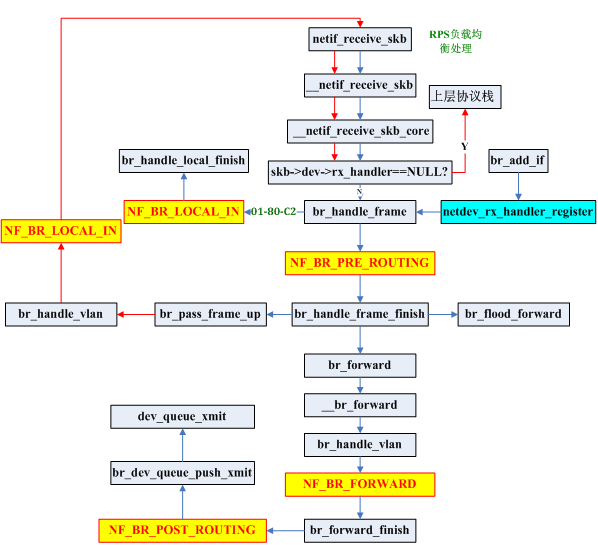
注意,和2.6kernel一样,bridge的OUTPUT hook点在bridge dev的发送函数中,这里不再分析列出。
-
编译你自己的Linux内核(Kernel)2016-11-10 5478
-
Linux中Kernel的运行原理概述2019-07-24 1974
-
Linux Kernel核心中文手册2008-12-08 658
-
Developing Linux kernel space2009-08-21 607
-
linux内核kernel-api2015-10-30 701
-
Linux之kernel_timer教程2016-04-15 738
-
在Linux运行期间升级Linux系 统Uboot+kernel+Rootfs2017-10-30 886
-
Linux-kernel-3 0的移植记录2017-10-31 772
-
你了解过Linux--start_kernel()函数?2019-05-07 2056
-
你知道linux kernel内存碎片防治技术?2019-05-10 1443
-
你了解u-boot与linux内核间的参数传递过程?2019-05-13 2552
-
Linux Kernel 5.2.2震撼发布!2019-08-09 3526
-
Linux Kernel 5.6-rc7候选版本发布2020-03-26 6229
-
Linux_Kernel_Developments内核开发2021-04-07 1045
-
Linux Kernel5.10维护周期将从2年延长至6年2021-05-24 3110
全部0条评论

快来发表一下你的评论吧 !
