

你了解过Linux内核的的tasklet机制和工作队列?
嵌入式技术
描述
1. Tasklet机制分析
上面我们介绍了软中断机制,linux内核为什么还要引入tasklet机制呢?主要原因是软中断的pending标志位也就32位,一般情况是不随意增加软中断处理的。而且内核也没有提供通用的增加软中断的接口。其次内,软中断处理函数要求可重入,需要考虑到竞争条件比较多,要求比较高的编程技巧。所以内核提供了tasklet这样的一种通用的机制。
其实每次写总结的文章,总是想把细节的东西说明白,所以越写越多。这样做的好处是能真正理解其中的机制。但是,内容太多的一个坏处就是难道记忆,所以,在讲清楚讲详细的同时,我还要把精髓总结出来。Tasklet的特点,也是tasklet的精髓就是:tasklet不能休眠,同一个tasklet不能在两个CPU上同时运行,但是不同tasklet可能在不同CPU上同时运行,则需要注意共享数据的保护。
主要的数据结构
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
struct tasklet_struct{ struct tasklet_struct *next; unsigned long state; atomic_t count; void (*func)(unsigned long); unsigned long data;};
1
2
3
4
5
6
7
8
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
如何使用tasklet
使用tasklet比较简单,只需要初始化一个tasklet_struct结构体,然后调用tasklet_schedule,就能利用tasklet机制执行初始化的func函数。
static inline void tasklet_schedule(struct tasklet_struct *t){ if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_schedule(t);}
1
2
3
4
5
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
tasklet_schedule处理过程也比较简单,就是把tasklet_struct结构体挂到tasklet_vec链表或者挂接到tasklet_hi_vec链表上,并调度软中断TASKLET_SOFTIRQ或者HI_SOFTIRQ
void __tasklet_schedule(struct tasklet_struct *t){ unsigned long flags;local_irq_save(flags); t->next = NULL; *__get_cpu_var(tasklet_vec).tail = t; __get_cpu_var(tasklet_vec).tail = &(t->next); raise_softirq_irqoff(TASKLET_SOFTIRQ); local_irq_restore(flags);}EXPORT_SYMBOL(__tasklet_schedule);void __tasklet_hi_schedule(struct tasklet_struct *t){ unsigned long flags; local_irq_save(flags); t->next = NULL; *__get_cpu_var(tasklet_hi_vec).tail = t; __get_cpu_var(tasklet_hi_vec).tail = &(t->next); raise_softirq_irqoff(HI_SOFTIRQ); local_irq_restore(flags);}EXPORT_SYMBOL(__tasklet_hi_schedule);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;local_irq_save(flags);
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
EXPORT_SYMBOL(__tasklet_schedule);
void __tasklet_hi_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__get_cpu_var(tasklet_hi_vec).tail = t;
__get_cpu_var(tasklet_hi_vec).tail = &(t->next);
raise_softirq_irqoff(HI_SOFTIRQ);
local_irq_restore(flags);
}
EXPORT_SYMBOL(__tasklet_hi_schedule);
Tasklet执行过程
Tasklet_action在软中断TASKLET_SOFTIRQ被调度到后会被执行,它从tasklet_vec链表中把tasklet_struct结构体都取下来,然后逐个执行。如果t->count的值等于0,说明这个tasklet在调度之后,被disable掉了,所以会将tasklet结构体重新放回到tasklet_vec链表,并重新调度TASKLET_SOFTIRQ软中断,在之后enable这个tasklet之后重新再执行它。
static void tasklet_action(struct softirq_action *a){ struct tasklet_struct *list;local_irq_disable(); list = __get_cpu_var(tasklet_vec).head; __get_cpu_var(tasklet_vec).head = NULL; __get_cpu_var(tasklet_vec).tail = &__get_cpu_var(tasklet_vec).head; local_irq_enable(); while (list) { struct tasklet_struct *t = list; list = list->next; if (tasklet_trylock(t)) { if (!atomic_read(&t->count)) { if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state)) BUG(); t->func(t->data); tasklet_unlock(t); continue; } tasklet_unlock(t); } local_irq_disable(); t->next = NULL; *__get_cpu_var(tasklet_vec).tail = t; __get_cpu_var(tasklet_vec).tail = &(t->next); __raise_softirq_irqoff(TASKLET_SOFTIRQ); local_irq_enable(); }}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;local_irq_disable();
list = __get_cpu_var(tasklet_vec).head;
__get_cpu_var(tasklet_vec).head = NULL;
__get_cpu_var(tasklet_vec).tail = &__get_cpu_var(tasklet_vec).head;
local_irq_enable();
while (list)
{
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t))
{
if (!atomic_read(&t->count))
{
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
2. Linux工作队列
前面已经介绍了tasklet机制,有了tasklet机制为什么还要增加工作队列机制呢?我的理解是由于tasklet机制的限制,变形tasklet中的回调函数有很多的限制,比如不能有休眠的操作等等。而是用工作队列机制,需要处理的函数在进程上下文中调用,休眠操作都是允许的。但是工作队列的实时性不如tasklet,采用工作队列的例程可能不能在短时间内被调用执行。
数据结构说明
首先需要说明的是workqueue_struct和cpu_workqueue_struct这两个数据结构,创建一个工作队列首先需要创建workqueue_struct,然后可以在每个CPU上创建一个cpu_workqueue_struct管理结构体。
struct cpu_workqueue_struct{ spinlock_t lock; struct list_head worklist; wait_queue_head_t more_work; struct work_struct *current_work; struct workqueue_struct *wq; struct task_struct *thread; int run_depth; /* Detect run_workqueue() recursion depth */} ____cacheline_aligned;/* * The externally visible workqueue abstraction is an array of * per-CPU workqueues: */struct workqueue_struct{ struct cpu_workqueue_struct *cpu_wq; struct list_head list; const char *name; int singlethread; int freezeable; /* Freeze threads during suspend */ int rt;#ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map;#endif};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
struct cpu_workqueue_struct
{
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
int run_depth; /* Detect run_workqueue() recursion depth */
} ____cacheline_aligned;
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct
{
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
Work_struct表示将要提交的处理的工作。
struct work_struct{ atomic_long_t data;#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */#define WORK_STRUCT_FLAG_MASK (3UL)#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK) struct list_head entry; work_func_t func;#ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map;#endif};
1
2
3
4
5
6
7
8
9
10
11
12
struct work_struct
{
atomic_long_t data;
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
上面三个数据结构的关系如下图所示
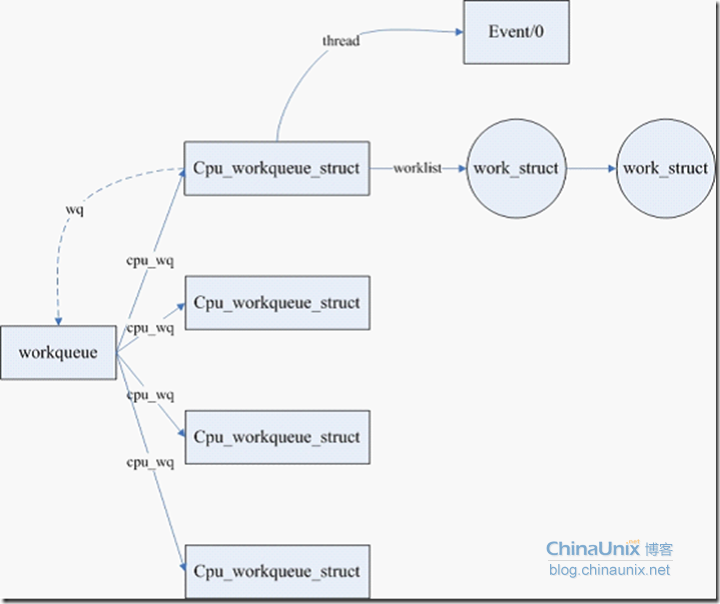
介绍主要数据结构的目的并不是想要把工作队列具体的细节说明白,主要的目的是给大家一个总的架构的轮廓。具体的分析在下面展开。从上面的该模块主要数据结构的关系来看,主要需要分析如下几个问题:
1. Workqueque是怎样创建的,包括event/0内核进程的创建
2. Work_queue是如何提交到工作队列的
3. Event/0内核进程如何处理提交到队列上的工作
Workqueque的创建
首先申请了workqueue_struct结构体内存,cpu_workqueue_struct结构体的内存。然后在init_cpu_workqueue函数中对cpu_workqueue_struct结构体进行初始化。同时调用create_workqueue_thread函数创建处理工作队列的内核进程。
create_workqueue_thread中创建了如下的内核进程
p = kthread_create(worker_thread, cwq, fmt, wq->name, cpu);
最后调用start_workqueue_thread启动新创建的进程。
struct workqueue_struct *__create_workqueue_key(const char *name, int singlethread, int freezeable, int rt, struct lock_class_key *key, const char *lock_name){ struct workqueue_struct *wq; struct cpu_workqueue_struct *cwq; int err = 0, cpu;wq = kzalloc(sizeof(*wq), GFP_KERNEL); if (!wq) return NULL; wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct); if (!wq->cpu_wq) { kfree(wq); return NULL; } wq->name = name; lockdep_init_map(&wq->lockdep_map, lock_name, key, 0); wq->singlethread = singlethread; wq->freezeable = freezeable; wq->rt = rt; INIT_LIST_HEAD(&wq->list); if (singlethread) { cwq = init_cpu_workqueue(wq, singlethread_cpu); err = create_workqueue_thread(cwq, singlethread_cpu); start_workqueue_thread(cwq, -1); } else { cpu_maps_update_begin(); /* * We must place this wq on list even if the code below fails. * cpu_down(cpu) can remove cpu from cpu_populated_map before * destroy_workqueue() takes the lock, in that case we leak * cwq[cpu]->thread. */ spin_lock(&workqueue_lock); list_add(&wq->list, &workqueues); spin_unlock(&workqueue_lock); /* * We must initialize cwqs for each possible cpu even if we * are going to call destroy_workqueue() finally. Otherwise * cpu_up() can hit the uninitialized cwq once we drop the * lock. */ for_each_possible_cpu(cpu) { cwq = init_cpu_workqueue(wq, cpu); if (err || !cpu_online(cpu)) continue; err = create_workqueue_thread(cwq, cpu); start_workqueue_thread(cwq, cpu); } cpu_maps_update_done(); } if (err) { destroy_workqueue(wq); wq = NULL; } return wq;}EXPORT_SYMBOL_GPL(__create_workqueue_key);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
struct workqueue_struct *__create_workqueue_key(const char *name,
int singlethread,
int freezeable,
int rt,
struct lock_class_key *key,
const char *lock_name)
{
struct workqueue_struct *wq;
struct cpu_workqueue_struct *cwq;
int err = 0, cpu;wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
return NULL;
wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct);
if (!wq->cpu_wq)
{
kfree(wq);
return NULL;
}
wq->name = name;
lockdep_init_map(&wq->lockdep_map, lock_name, key, 0);
wq->singlethread = singlethread;
wq->freezeable = freezeable;
wq->rt = rt;
INIT_LIST_HEAD(&wq->list);
if (singlethread)
{
cwq = init_cpu_workqueue(wq, singlethread_cpu);
err = create_workqueue_thread(cwq, singlethread_cpu);
start_workqueue_thread(cwq, -1);
}
else
{
cpu_maps_update_begin();
/*
* We must place this wq on list even if the code below fails.
* cpu_down(cpu) can remove cpu from cpu_populated_map before
* destroy_workqueue() takes the lock, in that case we leak
* cwq[cpu]->thread.
*/
spin_lock(&workqueue_lock);
list_add(&wq->list, &workqueues);
spin_unlock(&workqueue_lock);
/*
* We must initialize cwqs for each possible cpu even if we
* are going to call destroy_workqueue() finally. Otherwise
* cpu_up() can hit the uninitialized cwq once we drop the
* lock.
*/
for_each_possible_cpu(cpu)
{
cwq = init_cpu_workqueue(wq, cpu);
if (err || !cpu_online(cpu))
continue;
err = create_workqueue_thread(cwq, cpu);
start_workqueue_thread(cwq, cpu);
}
cpu_maps_update_done();
}
if (err)
{
destroy_workqueue(wq);
wq = NULL;
}
return wq;
}
EXPORT_SYMBOL_GPL(__create_workqueue_key);
向工作队列中添加工作
Shedule_work 函数向工作队列中添加任务。这个接口比较简单,无非是一些队列操作,不再叙述。
/** * schedule_work - put work task in global workqueue * @work: job to be done * * This puts a job in the kernel-global workqueue. */int schedule_work(struct work_struct *work){ return queue_work(keventd_wq, work);}EXPORT_SYMBOL(schedule_work);
1
2
3
4
5
6
7
8
9
10
11
/**
* schedule_work - put work task in global workqueue
* @work: job to be done
*
* This puts a job in the kernel-global workqueue.
*/
int schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}
EXPORT_SYMBOL(schedule_work);
工作队列内核进程的处理过程
在创建工作队列的时候,我们创建了一个或者多个进程来处理挂到队列上的工作。这个内核进程的主要函数体为worker_thread,这个函数比较有意思的地方就是,自己降低的优先级,说明worker_thread调度的优先级比较低。在系统负载大大时候,采用工作队列执行的操作可能存在较大的延迟。
就函数的执行流程来说是真心的简单,只是从队列中取出work,从队列中删除掉,清除掉pending标记,并执行work设置的回调函数。
static int worker_thread(void *__cwq){ struct cpu_workqueue_struct *cwq = __cwq; DEFINE_WAIT(wait);if (cwq->wq->freezeable) set_freezable(); set_user_nice(current, -5); for (;;) { prepare_to_wait(&cwq->more_work, &wait, TASK_INTERRUPTIBLE); if (!freezing(current) && !kthread_should_stop() && list_empty(&cwq->worklist)) schedule(); finish_wait(&cwq->more_work, &wait); try_to_freeze(); if (kthread_should_stop()) break; run_workqueue(cwq); } return 0;}static void run_workqueue(struct cpu_workqueue_struct *cwq){ spin_lock_irq(&cwq->lock); cwq->run_depth++; if (cwq->run_depth > 3) { /* morton gets to eat his hat */ printk("%s: recursion depth exceeded: %dn", __func__, cwq->run_depth); dump_stack(); } while (!list_empty(&cwq->worklist)) { struct work_struct *work = list_entry(cwq->worklist.next, struct work_struct, entry); work_func_t f = work->func;#ifdef CONFIG_LOCKDEP /* * It is permissible to free the struct work_struct * from inside the function that is called from it, * this we need to take into account for lockdep too. * To avoid bogus "held lock freed" warnings as well * as problems when looking into work->lockdep_map, * make a copy and use that here. */ struct lockdep_map lockdep_map = work->lockdep_map;#endifcwq->current_work = work; list_del_init(cwq->worklist.next); spin_unlock_irq(&cwq->lock); BUG_ON(get_wq_data(work) != cwq); work_clear_pending(work); lock_map_acquire(&cwq->wq->lockdep_map); lock_map_acquire(&lockdep_map); f(work); lock_map_release(&lockdep_map); lock_map_release(&cwq->wq->lockdep_map); if (unlikely(in_atomic() || lockdep_depth(current) > 0)) { printk(KERN_ERR "BUG: workqueue leaked lock or atomic: " "%s/0x%08x/%dn", current->comm, preempt_count(), task_pid_nr(current)); printk(KERN_ERR " last function: "); print_symbol("%sn", (unsigned long)f); debug_show_held_locks(current); dump_stack(); } spin_lock_irq(&cwq->lock); cwq->current_work = NULL; } cwq->run_depth--; spin_unlock_irq(&cwq->lock);}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
static int worker_thread(void *__cwq)
{
struct cpu_workqueue_struct *cwq = __cwq;
DEFINE_WAIT(wait);if (cwq->wq->freezeable)
set_freezable();
set_user_nice(current, -5);
for (;;)
{
prepare_to_wait(&cwq->more_work, &wait, TASK_INTERRUPTIBLE);
if (!freezing(current) &&
!kthread_should_stop() &&
list_empty(&cwq->worklist))
schedule();
finish_wait(&cwq->more_work, &wait);
try_to_freeze();
if (kthread_should_stop())
break;
run_workqueue(cwq);
}
return 0;
}
static void run_workqueue(struct cpu_workqueue_struct *cwq)
{
spin_lock_irq(&cwq->lock);
cwq->run_depth++;
if (cwq->run_depth > 3)
{
/* morton gets to eat his hat */
printk("%s: recursion depth exceeded: %dn",
__func__, cwq->run_depth);
dump_stack();
}
while (!list_empty(&cwq->worklist))
{
struct work_struct *work = list_entry(cwq->worklist.next,
struct work_struct, entry);
work_func_t f = work->func;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct
* from inside the function that is called from it,
* this we need to take into account for lockdep too.
* To avoid bogus "held lock freed" warnings as well
* as problems when looking into work->lockdep_map,
* make a copy and use that here.
*/
struct lockdep_map lockdep_map = work->lockdep_map;
#endifcwq->current_work = work;
list_del_init(cwq->worklist.next);
spin_unlock_irq(&cwq->lock);
BUG_ON(get_wq_data(work) != cwq);
work_clear_pending(work);
lock_map_acquire(&cwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
f(work);
lock_map_release(&lockdep_map);
lock_map_release(&cwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0))
{
printk(KERN_ERR "BUG: workqueue leaked lock or atomic: "
"%s/0x%08x/%dn",
current->comm, preempt_count(),
task_pid_nr(current));
printk(KERN_ERR " last function: ");
print_symbol("%sn", (unsigned long)f);
debug_show_held_locks(current);
dump_stack();
}
spin_lock_irq(&cwq->lock);
cwq->current_work = NULL;
}
cwq->run_depth--;
spin_unlock_irq(&cwq->lock);
}
-
Linux驱动开发-内核共享工作队列2022-09-17 2258
-
芯灵思SinlinxA33开发板Linux内核 tasklet 机制(附实测代码)2019-02-15 13040
-
芯灵思SinlinxA64开发板Linux内核tasklet机制(附实测代码)2019-03-12 12081
-
内核工作队列workqueue简单使用2019-06-11 1105
-
如何使用RT-Thread系统中的工作队列 ( workqueue )呢2022-06-22 3263
-
Linux之tasklet教程2016-04-15 698
-
linux kernel工作队列及源码解析2017-10-27 1165
-
linux kernel工作队列及源码详细讲解2017-11-30 930
-
基于Linux 软中断机制以及tasklet、工作队列机制分析2018-01-15 4677
-
你知道linux的工作队列?2019-04-26 1436
-
你了解过Linux内核中的Device Mapper 机制?2019-04-29 1189
-
干货:Linux内核中等待队列的四个用法2020-06-20 3565
-
Liteos-a内核工作队列的实现原理分析及经验总结——芯海科技PPG芯片CS1262接入OpenHarmony实战2022-04-26 3847
-
Linux 6.9-rc1发布,加入定时器、工作队列及AMD P-State优化2024-03-25 1195
全部0条评论

快来发表一下你的评论吧 !
