

linux组调度浅析
嵌入式技术
描述
cgroup与组调度
linux内核实现了control group功能(cgroup,since linux 2.6.24),可以支持将进程分组,然后按组来划分各种资源。比如:group-1拥有30%的CPU和50%的磁盘IO、group-2拥有10%的CPU和20%的磁盘IO、等等。具体参阅cgroup相关文章。
cgroup支持很多种资源的划分,CPU资源就是其中之一,这就引出了组调度。
linux内核中,传统的调度程序是基于进程来调度的。假设用户A和B共用一台机器,这台机器主要用来编译程序。我们可能希望A和B能公平的分享CPU资源,但是如果用户A使用make -j8(8个线程并行make)、而用户B直接使用make的话(假设他们的make程序都使用了默认的优先级),A用户的make程序将产生8倍于B用户的进程数,从而占用(大致)8倍于B用户的CPU。因为调度程序是基于进程的,A用户的进程越多,被调度的机率就越大,就越具有对CPU的竞争力。
如何保证A、B用户公平分享CPU呢?组调度就能做到这一点。把属于用户A和B的进程各分为一组,调度程序将先从两个组中选择一个组,再从选中的组中选择一个进程来执行。如果两个组被选中的机率相当,那么用户A和B将各占有约50%的CPU。
相关数据结构 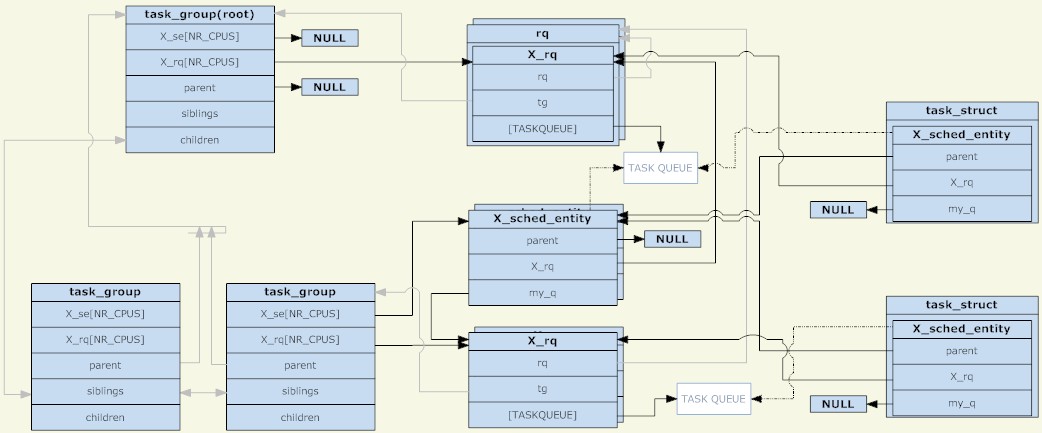
在linux内核中,使用task_group结构来管理组调度的组。所有存在的task_group组成一个树型结构(与cgroup的目录结构相对应)。
一个task_group可以包含具有任意调度类别的进程(具体来说是实时进程和普通进程两种类别),于是task_group需要为每一种调度策略提供一组调度结构。这里所说的一组调度结构主要包括两个部分,调度实体和运行队列(两者都是每CPU一份的)。调度实体会被添加到运行队列中,对于一个task_group,它的调度实体会被添加到其父task_group的运行队列。
为什么要有调度实体这样的东西呢?因为被调度的对象有task_group和task两种,所以需要一个抽象的结构来代表它们。如果调度实体代表task_group,则它的my_q字段指向这个调度组对应的运行队列;否则my_q字段为NULL,调度实体代表task。在调度实体中与my_q相对的是X_rq(具体是针对普通进程的cfs_rq和针对实时进程的rt_rq),前者指向这个组自己的运行队列,里面会放入它的子节点;后者指向这个组的父节点的运行队列,也就是这个调度实体应该被放入的运行队列。
于是,调度实体和运行队列又组成了另一个树型结构,它的每一个非叶子节点都跟task_group的树型结构是相对应的,而叶子节点都对应到具体的task。就像非TASK_RUNNING状态的进程不会被放入运行队列一样,如果一个组中不存在TASK_RUNNING状态的进程,则这个组(对应的调度实体)也不会被放入它的上一级运行队列。明确一点,只要调度组创建了,其对应的task_group就肯定存在于由task_group组成的树型结构中;而其对应的调度实体是否存在于由运行队列和调度实体组成的树型结构中,要取决于这个组中是否存在TASK_RUNNING状态的进程。
作为根节点的task_group是没有调度实体的,调度程序总是从它的运行队列出发,来选择下一个调度实体(根节点必定是第一个被选中的,没有其他候选者,所以根节点不需要调度实体)。根节点task_group所对应的运行队列被包装在一个rq结构中,里面除了包含具体的运行队列以外,还有一些全局统计信息等字段。
调度发生的时候,调度程序从根task_group的运行队列中选择一个调度实体。如果这个调度实体代表一个task_group,则调度程序需要从这个组对应的运行队列继续选择一个调度实体。如此递归下去,直到选中一个进程。除非根task_group的运行队列为空,否则递归下去一定能找到一个进程。因为如果一个task_group对应的运行队列为空,它对应的调度实体就不会被添加到其父节点对应的运行队列中。
最后,对于一个task_group来说,它的调度实体和运行队列都是每CPU一份的,一个(task_group对应的)调度实体只会被加入到相同CPU所对应的运行队列。而对于task来说,它的调度实体则只有一份(没有按CPU划分),调度程序的负载均衡功能可能会将(task对应的)调度实体从不同CPU所对应的运行队列移来移去。
组的调度策略
组调度的主要数据结构已经理清了,这里还有一个很重要的问题。我们知道task拥有其对应的优先级(静态优先级 or 动态优先级),调度程序根据优先级来选择运行队列中的进程。那么,既然task_group和task一样,都被抽象成调度实体,接受同样的调度,task_group的优先级又该如何定义呢?这个问题需要具体到调度类别来解答(不同的调度类别,其优先级定义方式不一样),具体来说就是rt(实时调度)和cfs(完全公平调度)两种类别。
实时进程的组调度
从《linux进程调度浅析》一文可以看到,实时进程是对CPU有着实时性要求的进程,它的优先级是跟具体任务相关的,完全由用户来定义的。调度器总是会选择优先级最高的实时进程来运行。
发展到组调度,组的优先级就被定义为“组内最高优先级的进程所拥有的优先级”。比如组内有三个优先级分别为10、20、30的进程,则组的优先级就是10(数值越小优先级越大)。
组的优先级如此定义,引出了一个有趣的现象。当task入队或者出队时,要把它的所有祖先节点都先出队,然后再重新由底向上依次入队。因为组节点的优先级是依赖于它的子节点的,task的入队和出队将影响它的每一个祖先节点。
于是,当调度程序从根节点的task_group出发选择调度实体时,总是能沿着正确的路径,找到所有TASK_RUNNING状态的实时进程中优先级最高的那一个。这个实现似乎理所当然,但是仔细想想,这样一来,将实时进程分组还有什么意义呢?无论分组与否,调度程序要做的事情都是“在所有TASK_RUNNING状态的实时进程中选择优先级最高的那一个”。这里似乎还缺了些什么……
现在需要先介绍一下linux系统中的两个proc文件:/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us。这两个文件规定了,在以sched_rt_period_us为一个周期的时间内,所有实时进程的运行时间之和不超过sched_rt_runtime_us。这两个文件的默认值是1s和0.95s,表示每秒种为一个周期,在这个周期中,所有实时进程运行的总时间不超过0.95秒,剩下的至少0.05秒会留给普通进程。也就是说,实时进程占有不超过95%的CPU。而在这两个文件出现之前,实时进程的运行时间是没有限制的,如果一直有处于TASK_RUNNING状态的实时进程,则普通进程会一直不能得到运行。相当于sched_rt_runtime_us等于sched_rt_period_us。
为什么要有sched_rt_runtime_us和sched_rt_period_us两个变量呢?直接使用一个表示CPU占有百分比的变量不可以么?我想这应该是由于很多实时进程实际上都是周期性地在干某件事情,比如某语音程序每20ms发送一个语音包、某视频程序每40ms刷新一帧、等等。周期是很重要的,仅仅使用一个宏观的CPU占有比无法准确描述实时进程需求。
而实时进程的分组就把sched_rt_runtime_us和sched_rt_period_us的概念扩展了,每个task_group都有自己的sched_rt_runtime_us和sched_rt_period_us,保证自己组内的进程在以sched_rt_period_us为周期的时间内,最多只能运行sched_rt_runtime_us这么多时间。CPU占有比为sched_rt_runtime_us/sched_rt_period_us。
对于根节点的task_group,它的sched_rt_runtime_us和sched_rt_period_us就等于上面两个proc文件中的值。而对于一个task_group节点来说,假设它下面有n个调度子组和m个TASK_RUNNING状态的进程,它的CPU占有比为A、这n个子组的CPU占有比为B,则B必须小于等于A,而A-B剩下的CPU时间将分给那m个TASK_RUNNING状态的进程。(这里讨论的是CPU占有比,因为每个调度组可能有着不同的周期值。)
为了实现sched_rt_runtime_us和sched_rt_period_us的逻辑,内核在更新进程的运行时间的时候(比如由周期性的时钟中断触发的时间更新)会给当前进程的调度实体及其所有祖先节点都增加相应的runtime。如果一个调度实体达到了sched_rt_runtime_us所限定的时间,则将其从对应的运行队列中剔除,并将对应的rt_rq置throttled状态。在这个状态下,这个rt_rq对应的调度实体不会再次进入运行队列。而每个rt_rq都会维护一个周期性的定时器,定时周期为sched_rt_period_us。每次定时器触发,其对应的回调函数就会将rt_rq的runtime减去一个sched_rt_period_us单位的值(但要保持runtime不小于0),然后将rt_rq从throttled状态中恢复回来。
还有一个问题,前面说到,默认情况下,系统中每秒钟内实时进程的运行时间不超过0.95秒。如果实时进程实际对CPU的需求不足0.95秒(大于等于0秒、小于0.95秒),则剩下的时间都会分配给普通进程。而如果实时进程的对CPU的需求大于0.95秒,它也只能够运行0.95秒,剩下的0.05秒会分给其他普通进程。但是,如果这0.05秒内没有任何普通进程需要使用CPU(一直没有TASK_RUNNING状态的普通进程)呢?这种情况下既然普通进程对CPU没有需求,实时进程是否可以运行超过0.95秒呢?不能。在剩下的0.05秒中内核宁可让CPU一直闲着,也不让实时进程使用。可见sched_rt_runtime_us和sched_rt_period_us是很有强制性的。
最后还有多CPU的问题,前面也提到,对于每一个task_group,它的调度实体和运行队列是每CPU维护一份的。而sched_rt_runtime_us和sched_rt_period_us是作用在调度实体上的,所以如果系统中有N个CPU,实时进程实际占有CPU的上限是N*sched_rt_runtime_us/sched_rt_period_us。也就是说,尽管默认情况下限制了每秒钟之内,实时进程只能运行0.95秒。但是对于某个实时进程来说,如果CPU有两个核,也还是能满足它100%占有CPU的需求的(比如执行死循环)。然后,按道理说,这个实时进程占有的100%的CPU应该是由两部分组成的(每个CPU占有一部分,但都不超过95%)。但是实际上,为了避免进程在CPU间的迁移导致上下文切换、缓存失效等一系列问题,一个CPU上的调度实体可以向另一个CPU上对应的调度实体借用时间。其结果就是,宏观上既满足了sched_rt_runtime_us的限制,又避免了进程的迁移。
普通进程的组调度
文章一开头提到了希望A、B两个用户在进程数不相同的情况下也能平分CPU的需求,但是上面关于实时进程的组调度策略好像与此不太相干,其实这就是普通进程的组调度所要干的事。
相比实时进程,普通进程的组调度就没有这么多讲究。组被看作是跟进程几乎完全相同的实体,它拥有自己的静态优先级、调度程序也动态地调整它的优先级。对于一个组来说,组内进程的优先级并不影响组的优先级,只有这个组被调度程序选中时,这些进程的优先级才被考虑。
为了设置组的优先级,每个task_group都有一个shares参数(跟前面提到的sched_rt_runtime_us和sched_rt_period_us两个参数并列)。shares并不是优先级,而是调度实体的权重(这是CFS调度器的玩法),这个权重和优先级是有一一对应的关系的。普通进程的优先级也会被转换成其对应调度实体的权重,所以可以说shares就代表了优先级。
shares的默认值跟普通进程默认优先级对应的权重是一样的。所以在默认情况下,组和进程是平分CPU的。
示例
(环境:ubuntu 10.04,kernel 2.6.32,Intel Core2 双核)
挂载一个只划分CPU资源的cgroup,并创建grp_a和grp_b两个子组:
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
分别开三个shell,第一个加入grp_a,后两个加入grp_b:
kouu@kouu-one:~/test/rtproc$ cat ttt.sh
echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。)
kouu@kouu-one:~/test1$ echo $$
6740
kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a
kouu@kouu-one:~/test2$ echo $$
9410
kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b
kouu@kouu-one:~/test3$ echo $$
9425
kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks
6740
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks
9410
9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c
......
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out
19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out
19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out
......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh
# echo 300000 > grp_a/cpu.rt_runtime_us
# exit
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_*
1000000
300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c
......
Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
......
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out
......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
- 相关推荐
- 热点推荐
-
深入探讨Linux的进程调度器2024-08-13 1936
-
带大家看看Linux内核如何调度进程的2021-07-26 2805
-
Linux的进程、线程以及调度2020-05-15 1435
-
英创信息技术Linux系统调度简介2020-02-05 1994
-
Linux进程调度时机概念分析2020-01-23 3635
-
Linux系统调度是实现特性的关键部分2019-07-05 1990
-
如何更改 Linux 的 I/O 调度器2019-05-15 1276
-
Linux 组调度浅析2019-04-02 797
-
Linux内核的DL调度器的细节和怎么样使用DL调度器?2018-07-16 6561
-
Linux系统调度简介2017-01-18 3583
-
Linux 2.6进程调度2009-06-13 571
-
linux处理机调度与死锁2009-04-28 684
-
Linux与VxWorks任务调度机制分析2009-03-28 959
全部0条评论

快来发表一下你的评论吧 !
