

语义表征的无监督对比学习:一个新理论框架
电子说
描述
诸如图像、文本、视频等复杂数据类型的语义表征 (也称为语义嵌入) 已成为机器学习的核心问题,并在机器翻译、语言模型、GAN、域迁移等领域中出现。这些都会涉及学习表征函数,即每个数据点的表征信息都是“高级别” (保留语义信息,同时丢弃低级细节,如图像中单个像素的颜色等) 和“紧凑“ (低维)。衡量语义表征好坏的一个标准是,它能够通过少量标记数据,使用线性分类器 (或其他低复杂度分类器) 来解决它们,从而大大简化新分类任务的求解过程。
使用未标记数据进行无监督表示学习研究是当前该领域最感兴趣的一个研究话题。一种常用的方法是使用类似于 word2vec 算法进行词嵌入 (word embedding),这种方法适用于各种数据类型,如社交网络、图像、文本等数据。
那么,为什么这些方法能够适用于如此多样化环境中?这得益于一种新的理论框架 “A Theoretical Analysis of Contrastive Unsupervised Representation Learning” 的提出。作为该框架的联合提出者,Misha Khodak 提出了一种非常简单的假设,因为类似 word2vec 算法需要适用于一些完全不同的数据类型,而这些数据无法共享一个通用的贝叶斯生成模型。(有关这个空间的生成模型例子在早期关于 RAND-WALK 模型的文章中有过描述。)因此,这个框架也提出了一些新方法,用于设计训练时的目标函数变体。本篇文章将详细解释这些方法。
论文链接:https://arxiv.org/abs/1902.09229
语义表征学习
首先,是否存在良好且广泛适用的表征呢?在计算机视觉等领域,答案是肯定的,因为深度卷积神经网络 (CNN) 在大型含多类别标签数据集 (如 ImageNet) 上以高精度训练时,最终会学习得到非常强大而简洁的表征信息。网络的倒数第二层——输入到最终的 softmax 层,可以在其他新的视觉任务中用作图像的良好语义嵌入。(同样,训练后网络中的其他层也可以作为良好的嵌入)。实际上,使用这种通过在大型多类别数据集上进行预训练得到网络,将其作为其他任务的语义嵌入已经在计算机视觉领域研究中广泛使用,这允许一些新的分类任务只需要非常少的标记数据,使用低复杂度分类器 (如线性分类器) 来解决。因此,尝试通过未标记的数据来学习语义嵌入信息,这已经成为一条黄金准则。
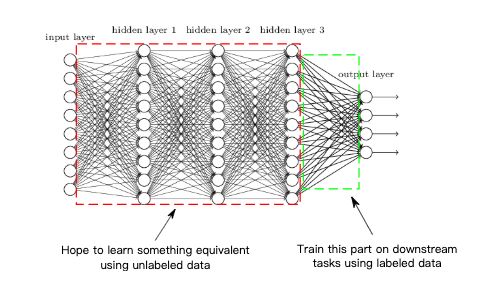
类似 word2vec 的方法:CURL
自 word2vec 方法取得成功以来,一些相似的方法也被用于学习诸如句子、段落、图像和生物序列等数据的嵌入信息。所有这些方法都是基于一个关键性的想法:即利用相似数据点对 x、x+,并学习嵌入函数 f 。嵌入函数是 f(x) 和 f(x+) 的內积表示,通常高于 f(x) 和 f(x-) 的內积和 (这里的 x- 是一个与 x 不相似的随机数据点)。在实践中,寻找相似数据点通常需要使用一些启发式方法,常用的方法是共现 (co-occurrences)。例如,在一个大型的文本语料库中,相似数据点可以通过连续的句子、视频剪辑中的相邻帧,同一图像中的不同补丁等找到。
这种方法的一个代表性例子是来自 Logeswaran 和 Lee 提出的 Quick Thoughts (QT),这是当前许多无监督文本嵌入任务中最先进的方法。对于一个大型文本语料库中,为了学习一个表征函数 f,QT 将损失函数最小化,其数学表达式如下:
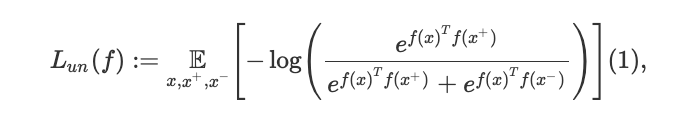
这里,(x,x+) 表示的是连续句子中语义相似的数据点,x- 代表一个随机的负样本。例如,对于图像而言, x 和 x+ 可能是视频中的相邻帧。对于文本而言,两个连续的句子是选择相似数据点的良好选择。例如,以下是维基百科中对 word2vec 进行解释的的两个连续句子案例:“High frequency words often provide little information”和“Words with frequency above a certain threshold may be subsampled to increase training speed”。显然,这两个句子的相似数据点,比起任意随机得到的句子对更多,学习者正好可以利用这一点。因此,从现在开始使用对比度无监督表示学习 (CURL) 来指代那些用于寻找相似数据对的方法,而本文的目标就是要分析这些方法。
需要一个新的框架
标准的机器学习框架都涉及最小化一些损失函数,且当在训练数据点和测试数据点上的平均损失大致相同时,则认为模型的学习是成功的 (或具有泛化能力)。然而,在对比学习(contrastive learning,CL )中,测试时使用的目标函数通常与训练的目标函数不同:泛化误差并不能作为解决这类问题的正确方法。
早期在这方面所使用的方法包括核学习 (kernel learning) 和半监督学习 (semi-supervised learning),但在训练时通常至少需要一些带标签的数据,这些样本来自未来感兴趣的分类任务。使用简单的设置也可以构建带生成模型的贝叶斯方法,但这种方法已被证明难以解决诸如图像和文本等复杂数据问题。此外,上面所说的类似 word2vec 的简单方法似乎无法像贝叶斯优化器那样,以清楚直接的方式操作,且同时适用于一些不同的数据类型。
因此,本文通过提出一个新的框架来解决这个问题,该框架规范地定义了 “语义相似” 的概念,这是其他算法所没有的。此外,它还进一步说明为什么对比学习 能够提供良好的表征,以及在这种情况下一个良好表征的意义。
框架
显然,对比学习中使用隐式 / 启发式定义的相似性概念,以某种方式与下游任务 (downstream tasks) 相关联。例如,相似性带有强烈的隐含意义,即在许多下游任务中 “相似对” 往往被分配相同的标签 (虽然这本身没有硬性保证)。而本文提出了一种极简的框架来简单形式化这种相似性概念。为了方便说明,以下将数据点称为“图像”。
语义相似性
我们假设大自然有许多类图像,所有类集合 C 有一个度量标准 ρ。因此,当需要选择一个类时,我们将以概率 ρ(c) 选择类别 c。每个类别 c 在图像上都具有一个相关分布 Dc,即在需要提供类别 c 的示例 (如选择类别“狗”),则它将以概率 Dc (x) 选择图像 x。请注意,在这里类别之间可以有任意的重叠,也可以互相独立不重叠。为了公式化语义相似性的概念,在这里假设当需要提供相似图像时,使用度量 ρ 从集合 C 中选择一个类别 c+,然后选择两个来自 Dc + 的独立同分布样本 x,x+。随后再从度量 ρ 中选择另一个类别 c-,并从 Dc- 中随机挑选不相似样本 x-。
如下式,表征学习训练的目标函数使用早期的 QT 目标,但基于当前的框架继承了以下解释:
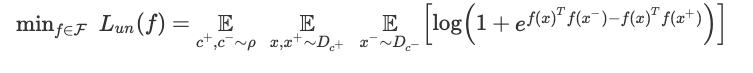
值得注意的是,函数类 F 是一个任意的深度网络结构。该架构将图像映射到嵌入空间 (神经网络没有最后一层),并通过梯度下降 / 反向传播法来学习 f。当然,目前还没有理论可以解释复杂的深度网络在什么时候算训练成功,因此,这里提出的框架会假设当梯度下降已经导致某些表征 f 达到很低的损失时认为达到了最优状态,并研究它在下游分类任务中的表现。
测试表征
用什么来定义一个好的表征呢?这里我们假设通过它,使用一个线性分类器解决二进制分类任务,来衡量表征的质量。(此外,本文还研究了下游任务中 k 类分类任务的情况)。那么如何选择这个二进制分类任务?我们根据度量 ρ 随机选取两个类别 c1、c2,并根据相关的概率分布 Dc1、Dc2 为每个类别选择数据点。然后使用该表征,通过逻辑回归来解决该二进制任务:即找到两个向量 w1、w2 来最小化以下损失。
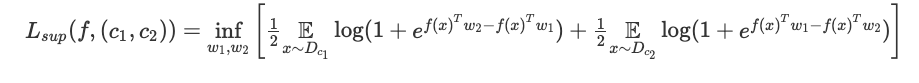
这里用二分类任务的平均损失来衡量表征的质量:
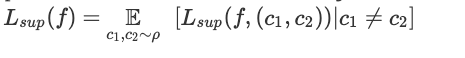
还值得注意的是,对于潜在类别中的未标记数据,将以相同类别在分类任务中出现。这允许我们可以公式化上面所提到的 “语义相似性” 的意义:即数据点更频繁地出现在一起的类别,构成了相关分类任务的类别。如果类别数很大的话,那么在无监督训练时使用的数据可能不会在测试阶段涉及。实际上,我们希望所学习的表征能够对那些潜在的、看不见的分类任务有用。
无监督学习的保证
该理论框架的理想结果是什么?假设我们固定一种类别的表征函数 F,并可以通过 ResNet 50 结构,选择结构层尺寸来计算它。
虽然可以使用 Rademacher complexity arguments 来控制学习近似最小化器时所需的未标记数据对的数量,但实际上,这种理想环境中的原理是不可能实现的。因为我们可以展示一个简单类别 F,它的对比目标无法产生可媲美最好类别所产生的表征。无需惊讶,这只是表明:想要实现这样一个理想结果,需要比上述结果做出更多的假设。
相反,本文所提出的框架证明,当对比学习结束时无监督损失恰好较小,则所得到的表征在下游的分类任务中能够表现良好。
这表明无监督损失函数可以被视为是使用线性分类方法解决下游任务时的一种性能替代,因此对其进行最小化是有意义的。此外,在未来的下游任务中,线性分类器学习只需要少数带标签的样本数据。因此,所提出的框架可以为对比学习提供保证,同时也能够突出它所提供的在标签样本复杂性方面的优势。
链接:https://arxiv.org/abs/1902.09229
理论分析的扩展
这个理论框架不仅能够推理 (1) 成功的变体,还能够设计理论上新的无监督目标函数。
先验(priori),可以想象是 (1) 中关于对数和指数的一些信息论解释;同时,将函数形式与用于下游分类任务的逻辑回归联系起来。类似地,如果通过 hinge loss 进行分类的话,那么在 (2) 中将使用 hinge-like loss 作为不同的无监督损失。例如,Wang 和 Gupta 论文中的目标函数被用于从视频中学习图像表征。此外,通常在实践中,k> 1 个负样本与每个正样本 (x,x+) 形成对比,而无监督的目标函数看起来像 k 类交叉熵损失形式。对于这种设置,事实上监督损失是与 (2) 中类似的 k + 1 类的分类损失。
最后,在相似数据可用时,该框架提供了用于设计新的无监督目标的方法 (如段落中的句子)。将 (1) 中的 f(x+) 和 f(x-) 分别替换为正、负样本表征的平均值,那么将得到一个新的目标函数,它在实践中具有更强的保证和更好的性能。最后,本文将通过实验来验证该变体的有效性,具体结果如下。
实验
接下来,我们将通过一些对照实验来验证所提出的理论。由于缺乏对多类别文本的规范说明,实验中使用一个新的含 3029 个类别的标签数据集,这些类别是来自维基百科网站上 3029 篇文章,每个数据点对应这些文章中 200 条句子中的一条。所学习的表征信息将在随机的二进制分类任务上进行测试,该分类任务涉及两篇文章,其中数据点对应的类别是其所属的两篇文章中的一篇 (同样,以这种方式定义 10 分类任务)。在训练表征时,将保持测试任务的数据点。句子表征 F 是基于门控递归单元 (GRU) 的简单多层结构。
基于上述的黄金标准,在这里通过有监督地训练 3029 类分类器并在最终的 softmax 层输出之前层所学习的表征得到最终的结果。
而根据所提出的理论,无监督方法用于生成相似的数据点对:这些相似的数据点只是从同一篇文章中采样得到的句子对。随后通过最小化上述的无监督损失目标来学习表征。
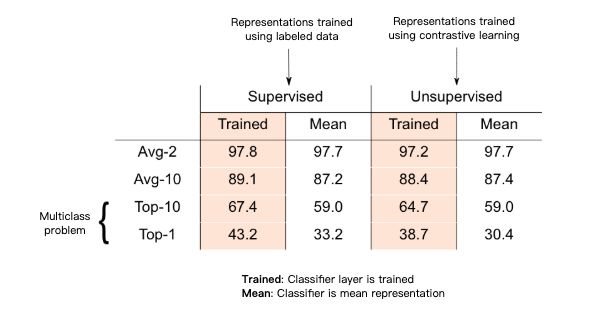
在上表中突出显示的部分表明,无监督表征与在 k 分类监督任务上 (k = 2,10) 所习得的表征相当。
此外,即使在所提出的理论中没有涉及,该表征也能够在完整的多分类问题上表现出色:即每个类别的无监督表征均值 (质心) 是能够在 k 分类监督任务中表现良好。而所得到的无监督表征和监督表征都是正确的。
此外,其他的实验进一步研究负样本数量和较大块相似数据点的影响,包括 CIFAR-100 图像数据集上的实验等。
结论
尽管对比学习是一种众所周知的直观算法,但是否真正有效却一直还未在实践中得到证实。本文所提出的理论框架,为使用此类算法学习表征提供了保证。在阐述这些算法的同时,该框架还能进一步提出并分析它的变体,并提供相应的解释证明,以便形成并探索更强保证的新假设。此外,基于该框架,还能进行一些扩展,包括对潜在类别强加一个度量结构,元学习 (meta-learning) 与迁移学习 (transfer learning) 之间建立联系等。
-
使用MATLAB进行无监督学习2025-05-16 1198
-
基于半监督学习框架的识别算法2018-01-21 1016
-
无监督学习的理论解释与实践教程2018-07-24 11942
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 875
-
如何用Python进行无监督学习2019-01-21 5011
-
无监督机器学习如何保护金融2020-05-01 1206
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6366
-
最基础的半监督学习2020-11-02 3179
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1179
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5458
-
对比学习的关键技术和基本应用分析2022-03-09 5847
-
结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE2022-05-05 1871
-
用于弱监督大规模点云语义分割的混合对比正则化框架2022-09-05 2009
-
深度学习框架和深度学习算法教程2023-08-17 1777
-
深度学习中的无监督学习方法综述2024-07-09 2541
全部0条评论

快来发表一下你的评论吧 !
