

一种WS新方法,那它可以超越GN、BN吗?
电子说
描述
【导语】继 BN、GN 方法提出后,大家还在不断提出能加速神经网络训练与收敛的方法,而约翰霍普金斯大学几位研究者在论文《Weight Standardization》中提出一种 WS 新方法,那它可以超越 GN、BN 吗?且看本文对研究的初解读,希望能给大家一点新思考!
批归一化(Batch Normalization)是深度学习发展中的一项里程碑技术,它让各种网络都能够进行训练。然而,沿着批次维度的归一化也带来了新问题:当统计不准确导致批次的大小越来越小时,BN 的错误会急剧增加。在训练更大的网络,以及执行将特征迁移至包括探测、分割、视频在内的计算机视觉任务时,BN 的使用就受到了限制,因为它们受限于内存消耗而只能使用小批次。
一年前,FAIR 团队的吴育昕和何恺明提出了组归一化(Group Normalization,简称 GN)的方法,GN 将信号通道分成一个个组别,并在每个组别内计算归一化的均值和方差,以进行归一化处理。GN 的计算与批量大小无关,而且在批次大小大幅变化时,精度依然稳定。
而今天 AI科技大本营要与大家探讨的是近日上传到 arXiv 上的一篇论文《Weight Standardization》,由来自约翰霍普金斯大学的几位研究者发表。作者在文中提出了一种权重标准化(Weight Standardization, WS)的方法,它可以用于加速深度网络的训练,并称稳定优于其它的归一化方法,而这也引起了大家的好奇与讨论,这个 WS 的方法是否真的可以超越 GN 与 BN?

接下来,AI科技大本营通过对 WS 方法的介绍、主要贡献与实验结果的展示为大家介绍这个在归一化方法之上的权重标准化的工作。希望能引发关注此研究方向的小伙伴们一些思考与看法!
通常来说,在使用 Batch Normalization(以下将简称 BN)时,采用小批次很难训练一个网络,而对于不使用批次的优化方法来说,效果很难媲美采用大批次BN时的训练结果。当使用 Group Normalization(以下将简称 GN),且 batch size 大小为 1 时,仅需要多写两行代码加入权重标准化方法,就能比肩甚至超越大批次BN时的训练效果。在微批次(micro-batch)的训练中,WS 的方法能稳定优于其它的归一化方法。与其他关注于激活值的归一化方法不同,WS 关注于权重的平滑效果。该方法的实现就是标准化卷积层的权重值,论文通过实验展示了这样的操作能够减少损失值和梯度值的 Lipschitz 常数。并且在多个计算机视觉任务,如目标检测、图像分类、实例分割等,验证了该方法的有效性。
在许多的视觉任务中,大部分深度网络通常都会使用 BN 层去加速训练和帮助模型更好收敛。虽然 BN 层非常实用,但从研究者的角度看,依然有一些非常显眼的缺点。比如(1)我们非常缺乏对于 BN 层成功原因的理解;(2)BN 层仅在 batch size 足够大时才有明显的效果,因此不能用在微批次的训练中。虽然现在已经有专门针对微批次训练设计的归一化方法(GN),但图 1 所示,它很难在大批次训练时媲美 BN 的效果。

图1:在Imagenet和Coco上,GN,BN,GN+WS三种方法的实验结果对比
现在关于 BN 有效的一种解释是它能缓解内部协变量转移(Internal Covariate Shift, ICS)的问题。但是有关研究[参考文献 1]也指出 BN 与 ICS 减少的问题无关,相反,BN 层使得相应优化问题的曲线更平衡。因此,根据[参考文献 1]的结论,旨在提出一种归一化技术可以进一步平滑该曲线。
与其他关注于激活值的归一化方法不同,WS 关注于权重的平滑效果。本文一共有三个贡献:
理论上,我们证明 WS 方法可以减少损失和梯度的 Lipsschitz 常数。因此,它能平滑损失曲线并提升训练效果。
图1 的实验结果显示,对于能够使用大批次的任务(如 Imagenet 分类),在使用 batch size为 1 的 GN+WS 时,其效果能够比肩甚至超过大批次下的 BN 效果。
图1 的实验结果显示,对于仅能使用微批次训练的任务(如Coco),GN+WS 可以大幅度的提升效果。
WS方法
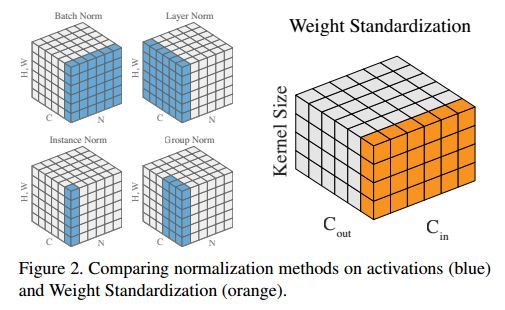
图2:归一化和WS方法的比较
给定一个没有偏置项的卷积层表达式如下图所示:
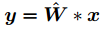
其中 W^ 卷积层的权重,* 是卷积运算。将图2 所示作为一个例子,WS方法不会直接在原始权重上进行优化,而是采用另一个函数 W^=WS(W)来表示原始权重 W^。然后使用 SGD 算法来更新 W。
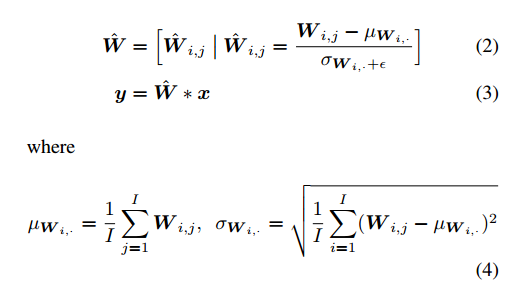
与 BN 类似,WS 方法在卷积层中分别控制输出权重的第一和第二阶段,许多权重初始化方法也是这样做的。不过不同的是,WS 是以可微的方式在反向传播过程中来标准化梯度。但是 WS 方法没有对 W^ 进行仿射转化,因为作者认为 BN 或者 GN 还会对卷积层进行再一次的归一化。
WS规范化梯度
下图是在网络前馈和反馈时,进行权重梯度标准化的计算表达式。

此时,在 feed-forwarding 过程中,计算方法变为:

banck-propagation 中计算方法为:

当然,论文的第二部分还通过公式推导了 WS 可以让损失曲线更加平滑,从而加速训练,提升效果的原因。而为了说明 WS 的有效性,作者在多个任务上进行了多个对比实验。
第一个实验:在Imagenet上的图像分类

上面表格展示了基于 ResNet50 和 ResNet101 网络结构的图像分类错误率。除了带 BN 层的网络使用大的 batch size,其它的归一化方法均设置 batch size 为 1。可以看出使用 WS 方法能够在 batch size 为 1 的情况下,略好于大批次 BN 的网络结果。在论文中,作者还做了更多与现有归一化方法对比的实验,来证明WS的效果。
第二个实验:在Coco上的目标检测和分割
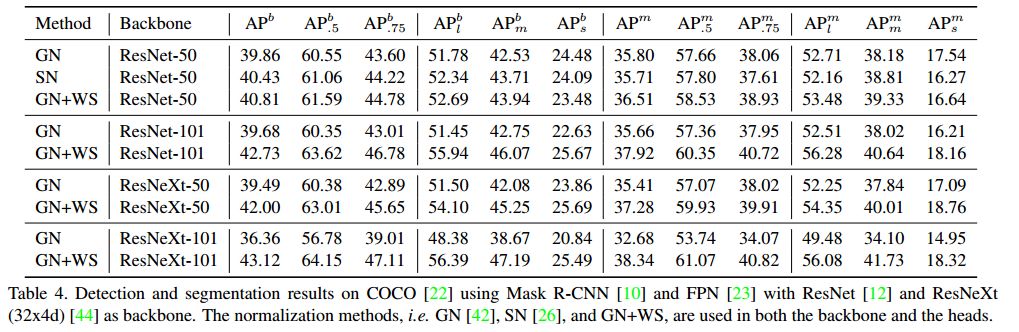
上述表格给出了检测框回归和实例分割的结果。在用的是 Mask R-CNN 框架,RXnet 的 backbone,与图像分类有相似的结果。值得注意的是,当网络变得更复杂时,仅使用 GN 很难提升性能,而加上 WS 后,就可以训练出更好的结果。这说明 WS 的归一化技术可以帮助更轻松的训练深层次网络,而不用担心内存和 batch size 的问题。
第三个实验:在 Something-Something 上的视频动作识别
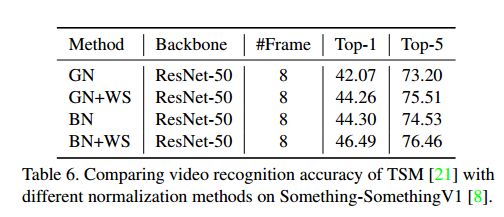
在这项任务中,采用 TSM 作为框架,ResNet50 作为 backbone,从表格中可以发现,不管是 BN 是 GN,加上了 WS 方法后,效果均有了提升。
第四个实验:在 PASCAL VOC 上的语义分割
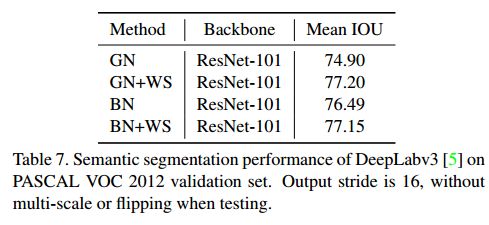
在 PASCAL VOC2012 数据集上的实验,采用 DeepLabv3 作为基准模型,Resnet101 为 backbone。实验结果证明,WS 方法针对密集图像预测任务,也能有稳定提升性能的表现。
第五个实验:在ModelNet40上的点云分类
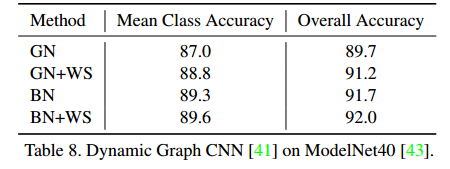
采用 DGCNN 作为基准模型,实验结果也显示了 WS 方法能够有效的提升模型性能。
以上五个实验,每个实验的设置参数在论文中均有详细的介绍。从实验方面证明了 WS 方法可以显著的提高性能。尤其是在某些情况下, GN 和 BN 可能无法达到很好的效果,通过结合 WS 的方法可以取得加速模型的训练与收敛;此外,WS 的归一化技术还可以帮助更轻松的训练深层次网络,而不用担心内存和 batch size 的问题。
关于研究介绍到这里后,对权重标准化这个方法,你是怎么看的?是否可以超越 GN、BN 呢?欢迎大家发表自己的看法!
-
一种无透镜成像的新方法2024-07-19 1592
-
一种产生激光脉冲新方法2023-12-07 1488
-
一种产生激光脉冲的新方法2023-11-20 2371
-
一种改善微波模块增益指标温度特性的新方法2023-10-25 477
-
一种复制和粘贴URL的新方法2020-12-21 5068
-
一种新方法,它可以让用户查看细菌是否会对抗生素有响应2020-07-08 2692
-
一种精确测量储能成本的新方法:LCUS2020-04-06 2146
-
一种在金上生成硫醇封端的SAM的新方法2019-10-30 1223
-
目前微通道面临的限制,突破硅技术的一种新方法2018-12-18 5340
-
PC机与单片机串行通信的一种新方法2017-09-04 1057
-
一种设计同步时序逻辑电路的新方法2017-02-07 1152
-
一种级数混合运算产生SPWM波新方法2017-01-07 777
-
一种标定陀螺仪的新方法2016-08-17 4288
-
一种求解非线性约束优化全局最优的新方法2009-08-11 907
全部0条评论

快来发表一下你的评论吧 !
