

最新的研究中,研究者仅需要音频信息就生成了人脸
电子说
描述
之前我们为大家介绍过一项非常酸爽的研究“Talking Face Generation”:给定音频或视频后(输入),可以让任意一个人的面部特征与输入的音视频信息保持一致,也就是说出输入的这段话。当时营长就想到了“杨超越的声音+高晓松的脸”这样的神仙搭配。不过,近期一项新研究再度抓到了营长的眼睛!在最新的研究中,研究者仅需要音频信息就生成了人脸... ...如此鬼畜的操作,此乃头一次见啊!接下来营长就为大家介绍一下这项工作!
音频和图像是人类最常用的两种信号传输模式,图像传达的信息非常直观,而语音包含的信息其实比我们想象的要更丰富,包括说话人的身份,性别和情绪状态等等。从这两个信号中提取的特征通常是高度相关的,可以让人仅聆听声音就可以想象他的视觉外观。WAV2PIX 的工作就是仅利用语音输入,来生成说话者的人脸图像。其实这就是一个跨模态的视觉生成任务。
谈到这项研究的贡献,主要有三点:
提出了一个能够直接从原始的语音信号生成人脸的条件GAN:WAV2PIX;
提供了一个在语音和人脸两方面综合质量很高的一个数据集:Youtubers;
实验证明论文的方法可以生成真实多样的人脸。
论文收集了大V用户(Youtubers)上传到 Youtube 的演讲视频,这些视频通常具有高质量的说话环境、表达方式、人脸特征等。Youtubers 数据集主要由两部分组成:一个是自动生成的数据集和一个手动处理后的高质量的子集。
主要的预处理工作:
音频最初下载的是高级音频编码(AAC)格式,44100 Hz,立体声。因此转换为 WAV 格式,并重新采样到 16 kHz,每个样例占 16 位并转换为单声道。
采用基于 Haar 特征的人脸检测器来检测正脸。仅采纳置信度高的帧
保存检测出来的那帧图像及前后两秒的语音帧,以及一个标签(identity)。
方法介绍
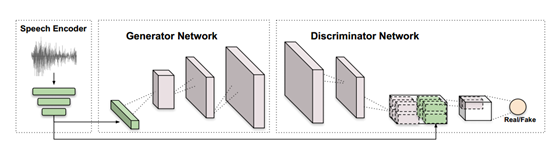
研究主要由三个模块构成:一个是语音编码器,一个是图片生成网络,一个是图片判别网络。
语音编码器(Speech Encoder):已有的方法大多数是手工提取音频特征,并不是针对生成网络的任务进行优化的,而 SEGAN 提出了一种在波形上用于语音处理的方法。因此作者在已有的工作 SEGAN 上进行修改。修改为具有 6 层一维网络,并且每层的 kernel 大小是 15x15,步长为 4,然后每层卷积网络后面使用 LeakyReLU 激活函数,网络的输入通道是 1。输入 16kHZ 下1 秒的语音片段,上述的卷积网络可以得到一个 4x1024 的张量,然后采用三个全连接网络将特征数量从 4x1024 降到 128。作为生成器网络的输入。
图片生成器(Image Generator Network):输入是语音编码器的 128 向量。采用二维转置卷积、插值、dropout 等方式将输入转为 64x64x3 或者 128x128x3 的张量。在 G 的损失函数中添加了一个辅助损失用于保持说话人的标签(Identity)。
图片判别器(Image Discriminator Network):判别器由几层步长为 2,kernel 大小是 4x4 的卷积网络组成,并使用谱归一化和 LeakyReLU 激活函数。当张量为 4x4 时,作者拼接了语音的输入,并采用最后一层网络来计算 D 网络的分数。
实验过程
训练:将手动处理后的数据集作为训练集,采用数据增强等手动。值得注意的是,在处理时将每张图像复制了 5 次,并将其与 4 秒音频里面随机采样的 5 个不同的1秒音频块进行匹配。因此总共有 24K 左右的图像-音频对用于模型训练。其它超参数采用参考的文献设置。
评估:下图给出了可视化的结果,虽然生成的图像都比较模糊,但基本可以观察到人的面部特征,并且有不同的面部表情。
作者进一步微调了一个预训练的 VGG-FACE Descriptor 网络,用于量化测试结果,在作者提供的数据集上,可以达到 76.81% 的语音识别准确率和 50.08% 的生成图像准确率。
为了评估模型生成图像的真实程度,作者定义了一个 68 个人脸关键点的精度检测分数。如下图所示,测试结果精度可以达到 90.25%。表明在大多数情况下生成的图像保留了基本的面部特征。
感兴趣的小伙伴们可以下载阅读研究一下~

-
音频信息识别与检索技术2011-03-05 1862
-
音频分类与音频分段的研究2011-03-08 2555
-
matlab毕业论文-快速人脸特征定位2012-03-07 38282
-
人脸识别技术最新发展与研究2013-09-25 3771
-
基于CPLD的数字功率放大器的研究与实现2015-07-01 3327
-
人脸识别的研究范围和优势2017-06-29 4273
-
人脸识别在安防系统的应用研究2018-11-07 3673
-
基于小波变换的音频信息隐藏技术研究2010-12-27 1290
-
单对象人脸识别技术研究2010-02-06 938
-
原来美国的研究者最关心的是这些2016-11-19 481
-
机器学习研究者必知的八个神经网络架构2018-02-26 1536
-
一种基于实用AGC算法的音频信号处理方法与FPGA实现的分析研究2018-09-30 3653
-
丹麦研究者改进中红外成像 助力医学诊断2019-06-03 4455
-
70年人工智能研究,解读研究者最大的惨痛教训经验2020-08-14 743
全部0条评论

快来发表一下你的评论吧 !
