

Google又放大招,高效实时实现视频目标检测
电子说
描述
图像目标检测是图像处理领域的基础。自从2012年CNN的崛起,深度学习在Detection的持续发力,为这个领域带来了变革式的发展:一个是基于RPN的two-stage,RCNN/Fast RCNN/Faster RCNN、RetinaNet、Mask RCNN等,致力于检测精度的提高。一类是基于SSD和YOLOv1/v2/3的one-stage,致力于提高检测速度。
视频目标检测要解决的问题是对于视频中每一帧目标的正确识别和定位。相对于图像目标检测,视频是高度冗余的,包含了大量时间局部性(temporal locality,即在不同的时间是相似的)和空间局部性(spatial locality,即在不同场景中看起来是相似的),既Temporal Context(时间上下文)的信息。充分利用好时序上下文关系,可以解决视频中连续帧之间的大量冗余的情况,提高检测速度;还可以提高检测质量,解决视频相对于图像存在的运动模糊、视频失焦、部分遮挡以及形变等问题。
视频目标检测和视频跟踪不同。两个领域解决相同点在于都需要对每帧图像中的目标精准定位,不同点在于视频目标检测不考虑目标的识别问题,而跟踪需要对初始帧的目标精确定位和识别。
图1 高德地图车载AR导航可识别前方车辆并提醒
视频目标检测应用广泛,如自动驾驶,无人值守监控,安防等领域。如图1所示,高德地图车载AR导航利用视频目标检测,能够对过往车辆、行人、车道线、红绿灯位置以及颜色、限速牌等周边环境,进行智能的图像识别,从而为驾驶员提供跟车距离预警、压线预警、红绿灯监测与提醒、前车启动提醒、提前变道提醒等一系列驾驶安全辅助。
视频目标检测算法一般包括单帧目标检测、多帧图像处理、光流算法、自适应关键帧选择。Google提出基于Slownetwork 和Fast network分别提取不同特征,基于ConvLSTM特征融合后生成检测框,实现实时性的state-of-art。

论文地址:https://arxiv.org/abs/1903.10172
1 Motivation
物体在快速运动时,当人眼所看到的影像消失后,人眼仍能继续保留其影像,约0.1-0.4秒左右的图像,这种现象被称为视觉暂留现象。人类在观看视频时,利用视觉暂留机制和记忆能力,可以快速处理视频流。借助于存储功能,CNN同样可以实现减少视频目标检测的计算量。
视频帧具有较高的时序冗余。如图2所示,模型[1]提出使用两个特征提取子网络:Slow network 和Fast network。Slow network负责提取视频帧的精确特征,速度较慢,Fast network负责快速提取视频帧的特征提取,准确率较差,两者交替处理视频帧图像。Fast network和Slow network特征经过ConvLSTM层融合并保存特征。检测器在当前帧特征和上下文特征融合基础上生成检测框。论文提取基于强化学习策略的特征提取调度机制和需要保存特征的更新机制。
论文提出的算法模型在Pixel 3达到72.3 FPS,在VID 2015数据集state-of-art性能。
论文创新点:
1、提出基于存储引导的交替模型框架,使用两个特征提取网络分别提取不同帧特征,减少计算冗余。
2、提出基于Q-learning学习自适应交替策略,取得速度和准确率的平衡。
3、在手机设备实现迄今为止已知视频目标检测的最高速度。
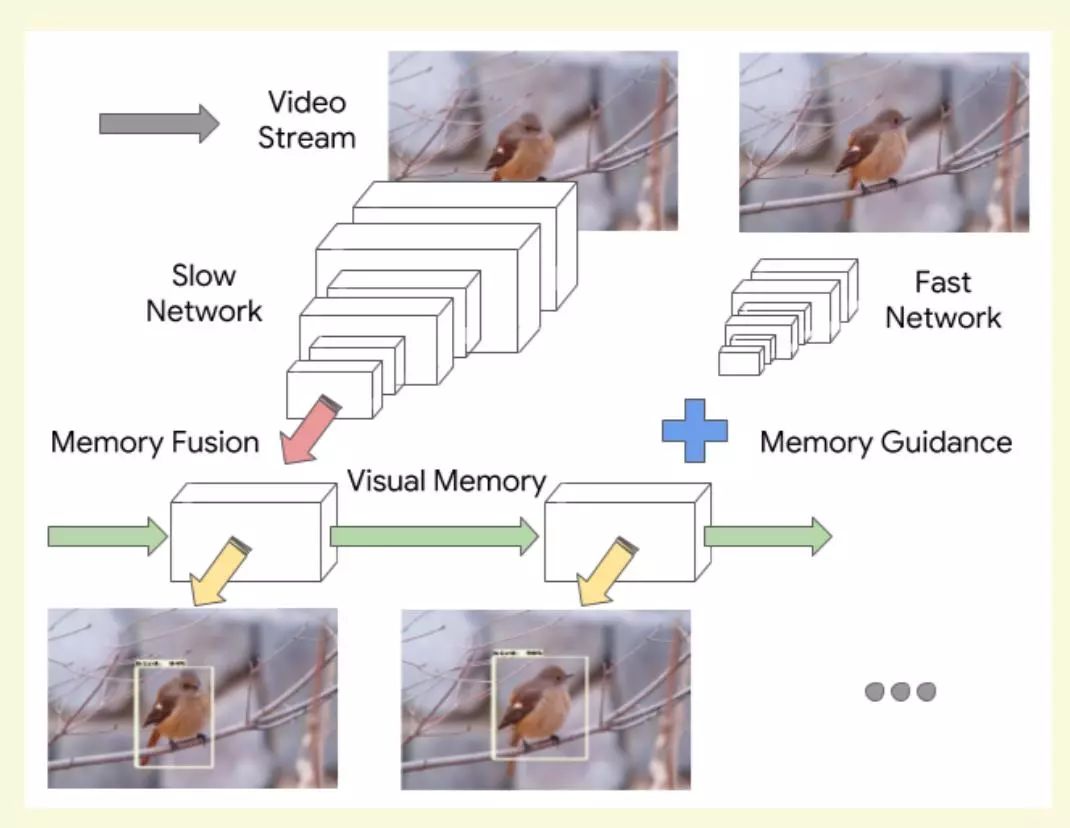
图2 存储引导的交错模型
2 网络架构
2.1交错模型
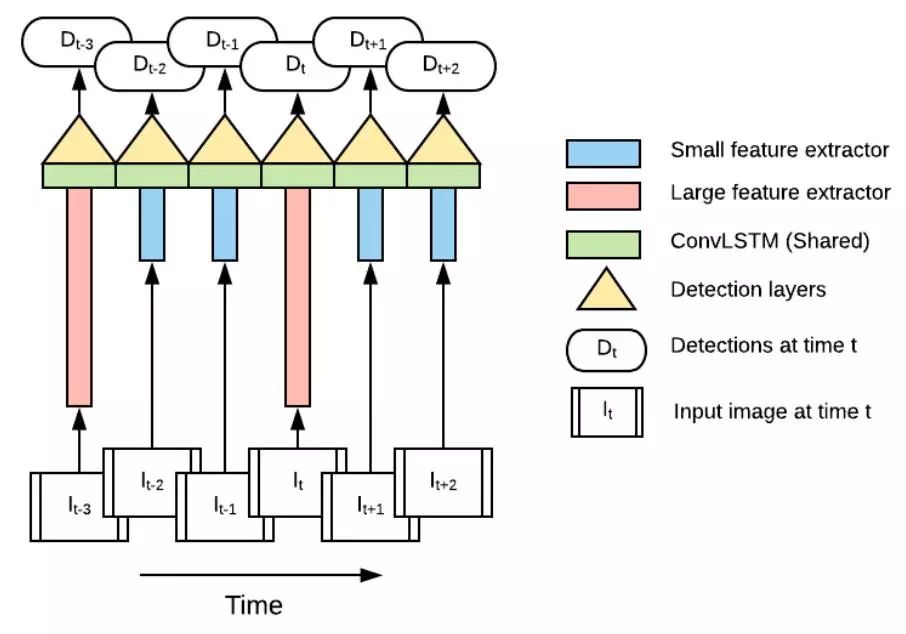
图3 交错模型
如图3所示论文提出的交错模型(τ = 2),Slow network(Large featureextractor)和Fastnetwork(Small feature extractor)均由MobileNetV2构成(两个模型的depth multiplier不同,前者为1.4,后者为0.35),anchors比率限制为{1.0,0.5,2.0}。
2.2存储模型
LSTM可以高效处理时序信息,但是卷积运算量较大,并且需要处理所有视频帧特征。论文提出改进的ConvLSTM模型加速视频帧序列的特征处理。
ConvLSTM是一种将CNN与LSTM在模型底层结合,专门为时空序列设计的深度学习模块。ConvLSTM核心本质还是和LSTM一样,将上一层的输出作下一层的输入。不同的地方在于加上卷积操作之后,为不仅能够得到时序关系,还能够像卷积层一样提取特征,提取空间特征。这样就能够得到时空特征。并且将状态与状态之间的切换也换成了卷积计算。
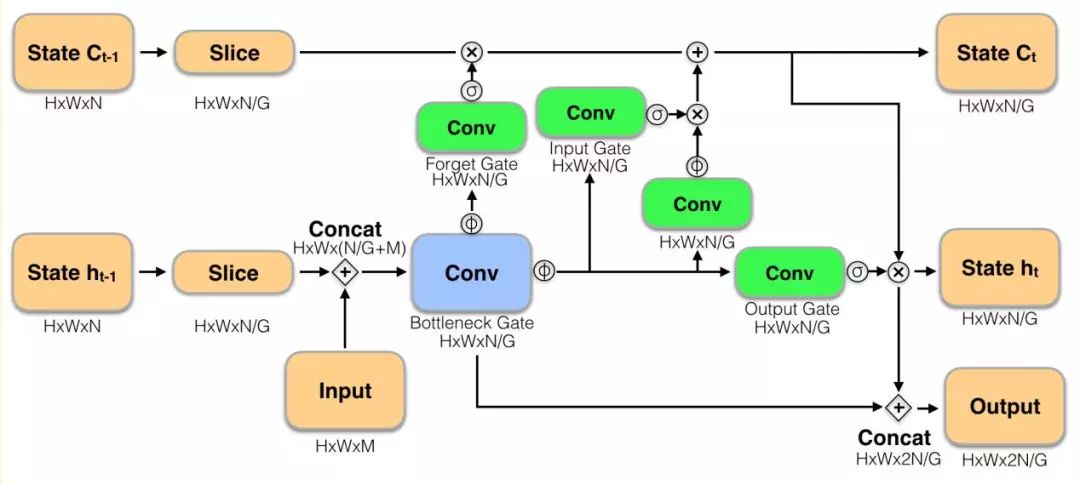
图4 存储模型LSTM单元
如所示,论文的ConvLSTM有一下改进:
1、增加Bottleneck Gate和output跳跃连接。
2、LSTM单元分组卷积。特征图HxWxN分为G组,每个LSTM仅处理HxWxN/G的特征,加速ConvLSTM计算。论文中G = 4。
3、LSTM有一固有弱点,sigmoid激活输入和忘记门很少完全饱和,导致缓慢的状态衰减,长期依赖逐渐丧失,更新中无法保留完整的前期状态。导致Fast network运行中,Slownetwork特征缓慢消失。论文使用简单的跳跃连接,既第一个Fast network输出特征重复使用。
2.3推断优化
论文提出基于异步模式和量化模型,提高系统的计算效率。
1、异步模式。交错模型的短板来自于Slow network。论文采用Fastnetwork提取每帧图像特征,τ = 2帧采用Slow network计算特征和更新存储特征。Slownetwork和Fast network异步进行,提高计算效率。
2、在有限资源的硬件设备上布置性能良好的网络,就需要对网络模型进行压缩和加速,其中量化模型是一种高效手段。基于[2]算法,论文的ConvLSTM单元在数学运算(addition,multiplication, sigmoid and ReLU6)后插入量化计算,确保拼接操作的输入范围相同,消除重新缩放的需求。
3 实验
模型在Imagenet DET 和COCO训练,在Imagenet VID 2015测试结果如图5所示。
从测试结果看,系统只有Slow network模块时准确率最高, 只有Fast network模块时准确率最低,但是速度没有交错模型快,比较诧异。另外基于强化学习的adaptive对精度和速度几乎没有影响,而异步模式和模型量化提高系统的实时性。
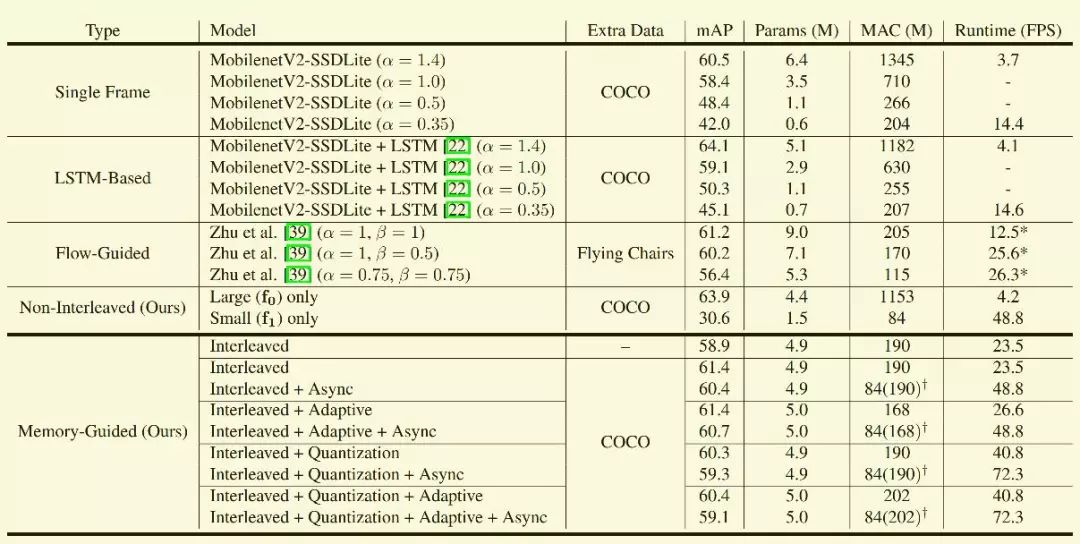
图5 Imagenet VID 2015测试结果
4 优缺点分析
视频处理策略
1、基于强化学习的交错模型调度是伪命题。论文的Slow network提取强特征,Fastnetwork提取弱特征,交错模型的τ越大,模型性能越差。理论上τ=2时模型的准确率越高。综合考虑准确率和实时性,论文中τ=9。
2、视频具有很强的上下文相关性。视频理解领域的目标检测、分割、识别,跟踪,等领域,都需要提取前后帧的运动信息,而传统采用光流方式,无法保证实时性。本文提出的分组ConvLSTM,可加速计算,量化模型保持准确率,具有借鉴意义。
以上仅为个人阅读论文后的理解、总结和思考。观点难免偏差,望读者以怀疑批判态度阅读,欢迎交流指正。
参考文献
[1] MasonLiu, Menglong Zhu, Marie White, Yinxiao Li, Dmitry Kalenichenko.Looking Fastand Slow: Memory-Guided Mobile Video Object Detection.arXivpreprint arXiv:1903.10172,2019.
[2] B.Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard,H. Adam, and D.Kalenichenko. Quantization and training of neural networks for efficientinteger-arithmetic-only inference. In CVPR, 2018.
-
基于FPGA的实时移动目标的追踪2018-08-10 3900
-
PowerPC小目标检测算法怎么实现?2019-08-09 2709
-
基于FPGA的视频实时边缘检测系统该怎么设计?2019-09-24 2242
-
如何实现机房环境动力远程实时监控呢2022-02-16 1007
-
如何使用Tengine Explore版在firefly-RK3399上实现实时目标检测?2022-03-04 1334
-
基于紫光同创FPGA的多路视频采集与AI轻量化加速的实时目标检测系统2023-11-02 1321
-
视频图像边缘实时检测系统的DSP实现2009-07-08 538
-
视频监控中的运动目标检测2016-12-17 1012
-
基于置信传播的视频运动目标检测2017-01-07 782
-
视频序列运动目标检测2017-12-01 1245
-
一种实时运动目标检测与跟踪算法2017-12-12 941
-
如何使用深度学习进行视频行人目标检测2018-11-19 1886
-
华为又放大招:发布正式商用的AI芯片——Ascend 910(昇腾910)2019-09-02 4985
-
Google相册现在允许您捏放大视频2021-02-22 2029
-
远程医疗支持系统 | 移远通信又放大招2023-01-13 2767
全部0条评论

快来发表一下你的评论吧 !
