

谷歌大脑在构建源代码生成模型上实现了新突破!
电子说
描述
预测源代码,听着就是一件非常炫酷的事情。最近,谷歌大脑的研究人员就对此高难度任务发起了挑战,在构建源代码生成模型上实现了新突破!
编程神技来了!
根据已经编辑好的代码预测源代码的AI,对程序员来说是一个非常宝贵的工具。
最近,谷歌大脑团队就对这项难度颇高的任务发起了挑战。

论文地址:
https://arxiv.org/pdf/1904.02818.pdf
改代码是程序员经常要做的事,需求一变,甚至可能要重头再来。然而,编辑模式(edit pattern)是无法仅仅根据要插入/删除的内容或者写好内容后的代码状态来被理解。
它需要根据变化与其所处状态的关系来理解,准确地对代码序列进行建模需要学习旧代码的表示方法,这就允许模型可以概括一种模式且对未来要编写的代码内容进行预测。
举个例子:

有两个历史记录A和B,这两段代码序列在经过2次编辑后,得到了相同状态,即“状态2”。但是在这个过程当中,历史记录A是在向foo函数添加参数,而历史记录B是在从foo函数中删除参数。
这项工作,就是希望根据“状态0”和“编辑 1&2 ”,可以预测接下来“编辑3”的操作内容。
为了达到这个目的,他们首先开发了两种表示方法来捕获意图信息,这些信息将随着代码序列的长度“优雅地”扩展:
显式表示方法:在序列中“实例化”代码内容;
隐式表示方法:用于实例化后续要编写的代码。
然后它们构建了一个机器学习模型,这个模型可以捕获原始代码和预测代码之间的上下文关系。
构建源代码生成模型新突破
近年来,构建源代码的生成模型成为十分受重视的核心任务。
然而,以前的生成模型总是根据生成代码的静态快照(static snapshot)来构建的。而在这项工作中,研究人员将源代码视为一个动态对象(dynamic object),并处理软件开发人员对源代码文件进行编辑的建模问题。
对编辑序列建模的主要挑战是如何开发良好的表示,既能捕获有关意图的所需信息,又能优雅地对序列的长度进行扩展。
正如上述,这项工作主要考虑编辑的两种表示方法,一是显式表示方法,二是隐式表示方法。
在显式表示方法中,将分层循环指针网络模型视为强大但计算成本较高的基线。在隐式表示方法中,考虑一个vanilla序列到序列模型,以及一个基于注意力的双头模型。这些模型展示了由不同问题公式产生的权衡,并为未来的编辑序列模型提供设计决策。
在精心设计的合成数据和对Python源代码进行细粒度编辑的大型数据集上,研究人员评估了模型的可伸缩性和准确性,以及模型观察以往编辑序列并预测未来编辑内容的能力。
实验表明,双头注意力模型特别适合实现对真实数据的高精度、校准良好的置信度和良好的可扩展性。
总之,这项工作形式化了从编辑序列中学习和预测编辑序列的问题,提供了对模型空间的初步探索,并演示了从开发人员对源代码进行的编辑中学习的实际问题的适用性。
问题定义:如何表示编辑序列数据
隐式和显式数据表示
第一个问题是如何表示编辑序列数据。我们定义了两种具有不同权衡的数据格式。
显式格式 (图 2 (a)) 将编辑序列表示为 2D 网格中 tokens 序列的序列。内部序列对文件中的 tokens 建立索引,外部序列对时间建立索引。任务是消耗前 t 行并预测在时间 t 进行的编辑的位置和内容。
隐式格式 (图 2 (b)) 将初始状态表示为 tokens 序列,将编辑表示为 (position, content) 对的序列。

图 2:将 “BACA” 转换为 “BABBCACC” 的编辑序列的显式表示 (a) 和隐式表示 (b)。
问题描述
显式问题的目标是学习一个模型,该模型使给定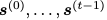 的
的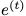 的可能性最大化;隐式问题是学习一个模型,该模型使给定所有 t 的
的可能性最大化;隐式问题是学习一个模型,该模型使给定所有 t 的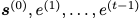 的
的 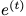
基线模型
基线显式模型 (Baseline Explicit Model)
基线显式模型是一个两级长短时记忆 (LSTM) 神经网络,类似于 Serban 等人 (2016) 的分层 RNN 模型。
基线隐式模型 (Baseline Implicit Model)
sequence-to-sequence 框架的自然应用是使用编码器的初始状态 s (0),并在解码器中生成 (p (t) i, c (t)) 对的序列。编码器是一个标准的 LSTM。解码器不太标准,因为每个动作都是成对的。为了将对作为输入处理,我们将 p (t) i 的嵌入与 c (t) 的嵌入连接起来。为了产生成对的输出,我们先预测位置,然后给出给定位置的内容。
隐式注意力模型
我们开发了一个模型,它对隐式表示进行操作,但是能够更好地捕获编辑内容与编辑上下文之间关系的序列。
该模型深受 Vaswani 等人 (2017) 的启发。在训练时,编辑的完整序列在单个前向传递中被预测。
有一个编码器计算初始状态和所有编辑的隐藏表示,然后有两个 decoder heads:第一个解码每个编辑的位置,第二个解码给定位置的每个编辑的内容。
图 3 (b, c) 对模型的整体结构进行了概述。
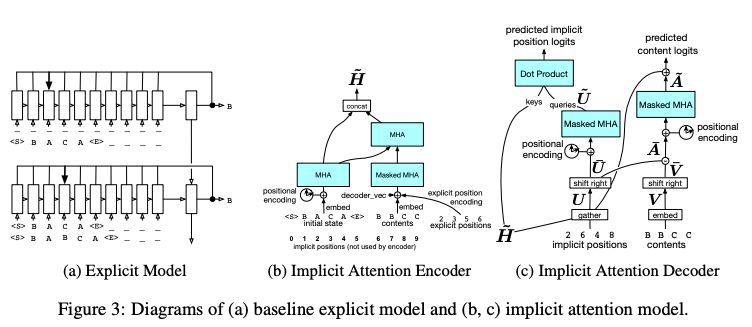
图 3:(a) 基线显式模型;(b, c) 隐式注意力模型
实验和结果:模型可以解决几乎所有任务
实验的目的是了解上述模型的能力和局限性,并在实际数据上进行评估。
实验有两个主要因素,一是模型如何准确地学习识别编辑序列中的模式,二是模型如何扩展到大数据。
在第一组实验中,我们在一个简单的环境中研究了这些问题;在第二组实验中,我们根据真实数据进行了评估。
本节中,我们评估了三种方法:显式模型缩写为 E,隐式 RNN 模型缩写为 IR,隐式注意力模型缩写为 IA。
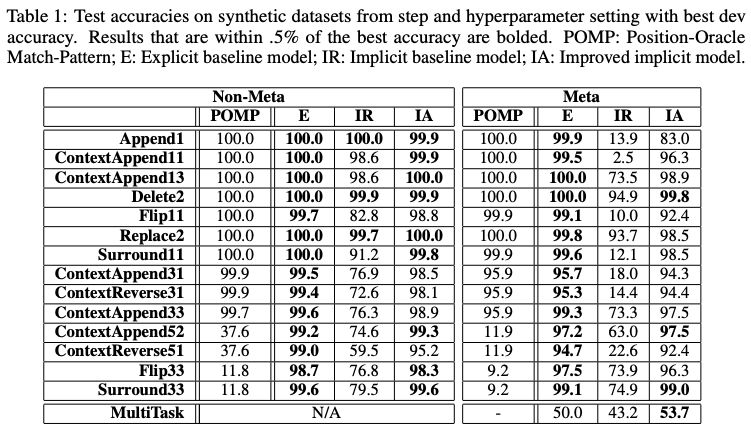
表 1:在合成数据集上的准确性
表 1 报告了产生最佳开发性能的超参数设置和步骤的测试性能。结果表明,显式模型和改进的隐式模型可以解决几乎所有的任务,甚至包括那些涉及元字符和相对较长的替换序列的任务。
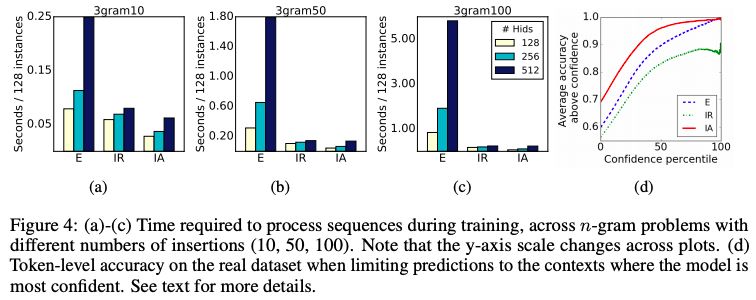
图 4:(a)-(c) 在训练期间处理序列所需的时间,跨越不同插入数 (10,50,100) 的 n-gram 问题。(d) 当将预测限制在模型最有信心的上下文中时,实际数据集的 token 级精度。
如图 4 (d) 所示,显式模型始终比隐式模型成本更高,并且随着数据大小的增加,这种差距也会增大。长度为 100 的插入序列比实际数据集中的序列小十倍,但在运行时已经存在一个数量级的差异。注意力模型通常占隐式 RNN 模型的 50% ~ 75% 的时间。
结论和未来研究
在这项工作中,我们提出了从过去的编辑中学习,以预测未来编辑的问题,开发了具有很强泛化能力的编辑序列模型,并证明了该方案对大规模源代码编辑数据的适用性。
我们做了一个不切实际的假设,即快照之间的编辑是按从左到右的顺序执行的。另一种值得探索的方案是,将其视为从弱监督中学习。可以想象这样一个公式,其中快照之间的编辑顺序是一个潜在变量,必须在学习过程中推断出来。
该研究有多种可能的应用。在开发人员工具的背景中,我们特别感兴趣的是调整过去的编辑以做出其他类型的预测。例如,我们还可以设置光标位置的条件,并研究如何使用编辑历史来改进忽略编辑历史的传统自动完成系统。另一个例子是,根据开发人员最近的编辑,预测他们接下来会发出哪些代码搜索查询。一般来说,我们希望预测开发人员接下来要做的事情。我们认为,编辑历史包含了重要的有用信息,在这项工作中提出的公式和模型是学习使用这些信息的良好起点。
-
基于扩散模型的图像生成过程2023-07-17 4132
-
在Raspberry Pi上从源代码构建OpenVINO™ ARM插件失败了,怎么解决?2025-03-06 253
-
PSPICE 生成的模型和datasheet对应不上2012-04-23 4691
-
怎么根据源代码文件中的注释生成源代码文档2019-04-10 2660
-
请问怎么在树莓派上从源代码构建Golang?2019-05-16 2895
-
基于模型设计的HDL代码自动生成技术综述2021-06-08 4187
-
Simulink 自动代码生成原理分享2022-05-31 8875
-
在Raspberry Pi上从源代码构建OpenVINO 2021.3收到错误怎么解决?2023-08-15 1031
-
UDP穿透NAT的原理与实现(附源代码)2010-02-09 639
-
谷歌大脑的“世界模型”简述与启发2019-01-30 3906
-
编程神技来了!谷歌新研究根据已经编辑好的代码预测源代码的 AI2019-04-18 2760
-
在STM32上移植的mx wifi源代码2022-09-26 735
-
MBD的Simulink使用技巧:详解代码生成中的模型与代码(2)2023-07-13 7993
-
从HumanEval到CoderEval: 你的代码生成模型真的work吗?2023-11-25 2709
-
KOALA人工智能图像生成模型问世2024-03-05 1317
全部0条评论

快来发表一下你的评论吧 !
