

AI算法在FPGA芯片上的创新应用
电子说
描述
碾压与崛起
AI算法的崛起并非一帆风顺的,现在的主流的NN类的卷积神经网络已经是第二波浪潮了,早在上个世纪80年代,源于仿生学,后又发展于概率学的早期AI算法已经取得了重大的进展,到1986年Rumelhart等人提出多层网络的反向传播算法(BP算法,这是AI算法可进行数据训练并能收敛的基础)后,第一波AI算法以“连接主义”的旗帜高高举起。
不幸的是,旗帜没举多久就开始偃旗息鼓,让位于基于统计学的算法,直到2006年,Hinton提出了“深度信念网络”的概念,从此,AI算法从“连接主义”变成“深度神经网络”再次华丽登场。
第一波AI算法之所以会快速落寞,不在于算法不够精美,是因为当时的cpu不够强大,算力完全无法适配当时的算法需求.第二次AI算法的崛起也并非算法足够惊艳,恰恰是证明了算力的崛起。
而且这算力的提供者并不是CPU,这种基于调度和内存交换的方式难以支持如此强大的AI算力缺口。
与此同时,基于异构计算的ASIC/FPGA/GPU也在快速崛起,其计算性能完全碾压CPU,有效的补充AI算力的缺口。
其中GPU迅速发展,成为目前AI崛起之路的最大收益者,然而GPU最初的设计目的不是针对AI算法而是处理图形图像的,因为图像上每个像素点处理的过程和方式都十分相似,所以GPU的构成相对简单,有数量众多的计算单元和用于并行的流水线,正是这种单指令流多数据流的设计模式,特别适合处理大量的类型统一的数据。
这也是在用GPU处理AI算法时,batchsize不能太低的原因。而在其他方面,如面积/功耗/能耗比方面,GPU也便成了弱势,相比较而言,ASIC芯片从一开始便是为AI而生,能效比高,不会有冗余,功耗低,适合算法稳定且要求的应用。
其缺点也是硬件为算法而定制,导致其只能运行特定的算法,当然,能做出通用AI算法的ASIC芯片是业界的终极目标。
而同时,作为ASIC的共轭形式存在的FPGA越来越受重视,FPGA能效比高,可编程逻辑,计算效率高,FPGA 同时拥有控制流并行和数据并行,是天生适合异构计算的芯片,目前开发FPGA应用方面还有很多潜能可挖。
通用Or灵活
一个基本的认知是ASIC虽然高效,但只能走专业化定制化的部分,ASIC制作成本很高,而算法一直在持续更新,如何解决这个矛盾呢?
是否可以做一个通用的ASIC来解决算力提升和灵活性的问题?寒武纪的NPU和google的TPU给出了答案,两者的实现虽然不同,但思路是一致的。
即:既然NN算法可以拆分成不同的算子,设计的硬件建模应该全部支持这些算子从而解决通用性问题,并建立相应的指令集来解决不同算子的组合,来解决灵活性的问题。当然,核心模块还是围绕计算量最大的模块卷积进行的。那么,在实现方式上它们又有哪些共同点和不足呢?
寒武纪dadiannao:
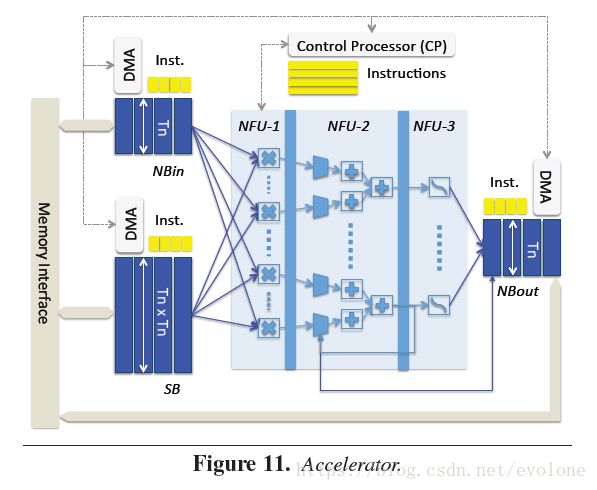
图1 (dadiannao)
上图的硬件建模就是在模仿神经网络部分的数据流向,NFU(Neural Functional Units)分三部分顺序展开,NFU-1是乘法单元,NFU-2是加法数树,处理filter内部或通道累加的问题,NFU-3是激活单元。
从模型上不难看出,这里的核心处理卷积的单元是在数据流方向上的一维展开进行计算的。
一维度展开会带来两个问题,一个是多扇出(fan-out)的问题,如果想更大限度的利用内部数据带宽优势以及多用乘法器模块,一个data需要同时广播给多个计算单元,这会导致多扇出的问题,要保证多个模块同时到达,则频率就不能提的太高。
另外一个问题就是为了保证乘法器都能充分工作,需对filter的相关参数进行限制.以DianNao为例,一个PE中的16个mul是同时计算的,那么卷积层中的kernel、channel、windows的长和宽都会对计算的效率造成影响,如channel最好是16或16的倍数,否则就会造成计算资源的浪费.
相比较而言,Google的TPU采用脉动矩阵的方式,巧妙的避开了对filter敏感的问题,TPU的脉动矩阵是面向数据流方向的二维结构,在处理卷积乘加这块有很强的优势。
理论上可以支持任何形式的windows、kernel和channel这种设计使得TPU有更强的灵活性和高效性。
TPU:
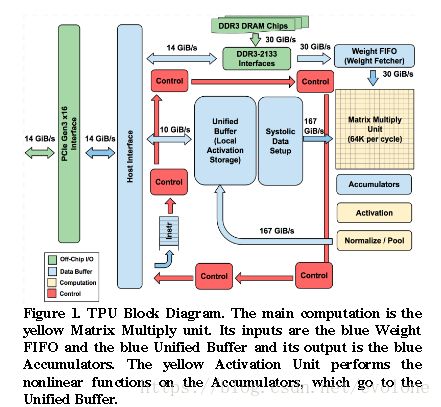
图2 (TPU)
然而,有得必有失。脉动矩阵中处理卷积时优势明显,但在处理非卷积类算子方面则未必高效。
比如在fastRcnn中的要用到排序算法proposal层,又如在多网融合的过程中会经常被使用 interp层(双线性插值)。
其中,排序算法在基因里是反asic的(区块链中的零币就是以排序为主的算法,主要用于反asic的功能)。类似这种非卷积算法因子则会导致脉动矩阵的功能大大降低,正是因为硬件的固定设置所限制。
ASIC 在走一个统一的路子,DADIANNAO和TPU都在用统一的模式来解决一切问题,然而现实是很骨感的,有两个基本点是ASIC中无法完美解决的,一个就是AI算法在不同的探索和更改期。
目前尚未突破其中的黑盒特性,而支持AI算法优化的强有力的基础理论迟迟没有发现,这个时期就好比科学历史上人们只知道电的存在而没有电磁原理支撑是一个道理,说明AI算法的研究应处于发展初期。
另外一点就是针对各个垂直领域,如无人机/自动驾驶/智能安防/无人零售的各种特殊的情况,每一个领域都对功耗/能耗比/性能/系统等等方面有不同的诉求,这些需求都有极强的定制性。如此,想要一颗ASIC芯片通吃天下的事情似乎是个无法求出的解。
找规律,找突破
如果ASIC无法解决算法通用性问题,那么更具有灵活配置性的芯片FPGA便越来越受到重视,FPGA的低延时,高可配置性的特点使其天然的在灵活性方面比ASIC略胜一筹。
那么FPGA能否满足统一性呢?其实,在业界对FPGA的探索一直没有停止,
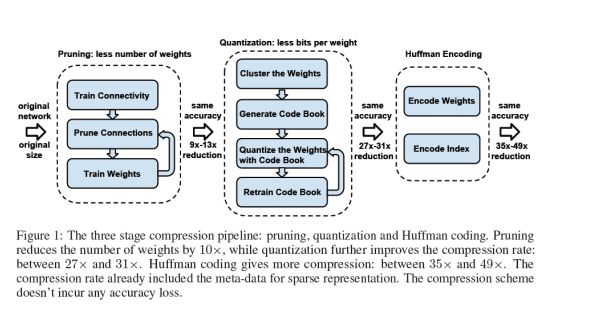
图3(三级压缩流水线)
国内FPGA的头部公司深鉴科技一直研究深度压缩技术,并在FPGA上实现了基于深度压缩技术的方案:深度压缩技术,其采用剪枝+量化+霍夫曼编码,形成三级大流水,如图3所示,实现高度压缩权重占用的存储空间。
其基本的思路就是,先对网络本身做pruning来减少权重的个数,同时通过训练来弥补由于减少权重而带来的精度损失,然后经过量化部分来减少权重的位宽,最后用霍夫曼编码来压缩权重。
总之目的只有一个,制作稀疏矩阵,然后利用稀疏矩阵的特性生成weight查找表,从而达到数据压缩的目的。数据压缩后再用FPGA实现会大大的降低开发难度和门槛。
而国内另外一个头部公司商汤科技的设计思想就是:通过大量减少卷积计算的乘法操作,降低运算复杂度,来提高运算速度,并在FPGA中顺利实现。
不管是降低乘法操作,还是做网络裁剪,其思路都是在修改算法的方式来适配FPGA的实现。
即先将FPGA的设计以固定的方式配置好,然后去修改算法来适配这种固定好的硬件设计。
这种方式的缺点也是显而易见的,且不说固定的设计方式会遇到ASIC同样的问题,单就修改网络的部分可能会导致原有网络的精度丢失的问题。
更为严重的是,这种设计方式会导致无法挖掘FPGA的全部潜力。
FPGA本身就是一个可编程系统,能够适配各种算法,为什么大家都在想办法修改算法问题,而没有想办法去修改FPGA的内部实现优化,从而完美的使其适配不同神经网络算法呢?答案很简单,用FPGA开发高难度的算法是一件很困难的事。
换一个语言,换一个世界
工欲善其事,必先利其器,现在主流的开发语言verilog HDL 是上个世纪80年代研究出来的,这在计算机界就好比是原始社会阶段,而且这么多年来一直没有更新过,对比高级语言的B->C->C++->java->python的不断升级,它就好比一个古老的青铜宝剑,虽价值连城,但并不适用,而让这个古老的语言来开发现在最先进的AI算法,这便是一个现代版的愚翁移山的故事。
接着探寻问题的本质,verilog的缺陷:
A)无规则化,或规范化,或许这是一个社会工程的问题,因为用的人少,所以没有形成统一的规范,编程方式过分自由,基本上是一千个人里有一千个哈姆雷特。
B)遇到复杂的逻辑,只能用状态机。
C)同步信号建模时,对控制信号的掌控偏弱。
D)没有图形化界面,仿真工具都是看波形。
而改进的方案正是解决这些问题,FPGA的开发就像是在玩乐高游戏,其实现过程就是在搭积木,其中的原语部分就是积木的原始器件,只是颗粒度有点小而已。
有没有一种方式将原始器件进行封装,加强控制逻辑,同时将控制逻辑和数据流逻辑分开,用软件的思想来封装硬件,包含继承,多态,递归,然后以图形化的形式展现出来,自带仿真系统,所见即所得,利用核心库器件,真正做到用搭积木的方式来开发FPGA,这样便能大大降低其开发门槛。
有一种很好用的开发工具ptero,是雪湖信息科技公司自主研发的开发FPGA的工具链,可以颠覆对FPGA开发的认知,上文的种种特性都已经在该工具中实现,相当于用全新的语言来开发FPGA,且完全是界面化的形式进行开发,所见即所得,极大的降低了开发门槛并提高了开发效率。
举个例子,在实现AI算法的过程中,对数据流的严格控制是关键,如下图所示,图中的例子是一个卷积核是3×3的数据组装功能实现,一个数据产生器来模拟数据来源,补零模块来进行padding补零操作,地址译码器来处理数据组装需要的不断变化的bram地址,三行缓存模块完成数据的组装。
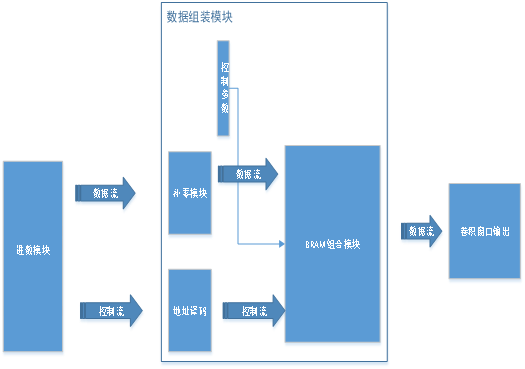
图4 卷积里面的数据组装模块
图4便是对上述流程的一个展示,从图形化里面我们很容易理解设计思路,由于里面的用到的模块都是在核心模块封装好。
所以,对开发人员来说,只需要将所有的精力都来放到逻辑这块即可。
同时,可以随时验证逻辑的正确性,所有的输出结果都可以打印输出。这种所见即所得的开发模式极大的提高了硬件逻辑的开发效率。
那么,在FPGA实现的过程中,是否可以做出通用化的过程呢?答案是肯定的,如图4中的红色字体所示,控制参数部分就是自动更新的参数,通过自动化工具生成的控制参数能有效的控制不同算子模块的实现,而无需改动硬件电路。
有了这样方便又强大的工具,又有了底层封装的模块,才能在上层建筑有更大的发挥空间,就能更好的发挥FPGA的潜能,使其适配更多的算法结构,而不是只关注于修改算法来削足适履。
换一种维度思考
解决了开发FPGA效率的问题,我们可以把主要精力在提升FPGA的性能上下功夫,利用FPGA的分布式的存储的思路来设计模型,将FPGA的性能提升到最高。
假设网络结构中有三层卷积依次执行,如下图所示:

图5(卷积合并示例)
在这样的网络结构下,第一层是1×1的卷积核,第二层是3×3的depwise卷积运算,第三层又是一个1×1的卷积核,每层的conv模块的kernel和channel都不是很大,类似这样的网络不同的算子组合在AI算法中很常见,若按传统的思路,只能每层conv都单独计算。
但每一层的计算都不能将FPGA的资源用满(dsp&bram),这会导致资源的浪费,最重要的是没有发挥FPGA的最大的性能,从而导致处理的帧率降低。
为了更好的利用FPGA 资源,挖掘FPGA的潜能,我们可以根据每层的资源分布做个统计,发现将上述三层的资源合并成一个全流水的方式(即一次IO读写,三层连续计算)才能将FPGA的潜能发挥到最大。
这种设计方案是根据算法的规律进行调整FPGA的组装结构,从而发挥出并行计算的最大性能。
如此定制化的方式是发挥了FPGA的最大性能,那么又会产生一个问题:AI算法那么多,有没有那种即能发挥FPGA的最大性能,又能有通用性的方法?
要回答这个问题,我们得先探究FPGA的本质,FPGA本质上是个分布式的资源分布系统,那么对核心资源(主要是dsp和bram)是否可以进行动态分配?
如果解决了这个问题,那么就能完美解决上述问题。
我们可以通过给相应模块不同的参数来适配不同的算法因子以及不同的算法组合,而修改这些参数并不需要修改FPGA程序。
而对这种方式的探索,雪湖信息科技已经做了很多工作,并有相当多的积累,并有可以商用的成熟案例,如下图,是我们生成参数的一角。
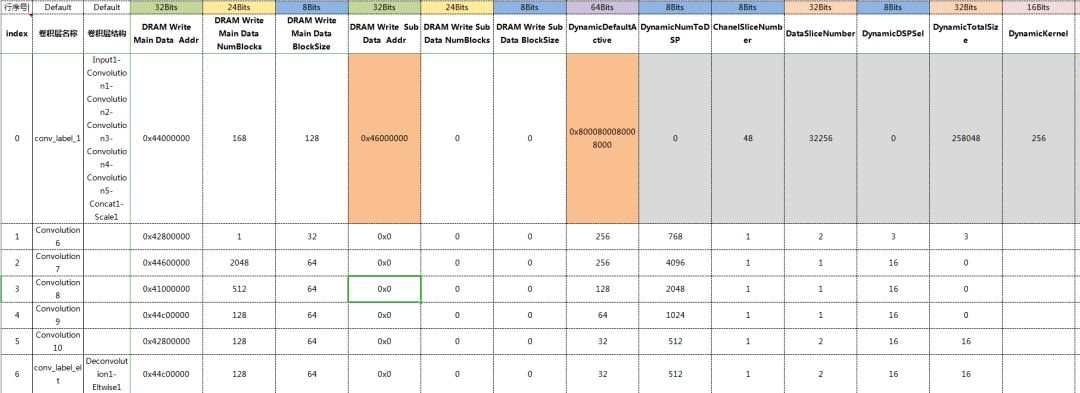
图6 (控制参数列表)
这样的设计思路是根据不同的参数控制,针对不同的filter大小、不同的算子、不同的算子组合、不同的conv层的组合,来进行不同的控制。
这种设计兼顾了FPGA的灵活性和通用性,可以说着兼顾通用性的情况下最大限度的提高了FPGA资源的使用率,也不会出现设计硬伤,可以适配任何新的算子,对interp等非卷积类支持很充分。
而针对proposal层的处理,可以在采用将网络一分为二,预留比较小的资源进行排序处理,而其他资源可以处理新的数据,两者并行处理,只有控制逻辑和周期计算处理好,两者不会产生阻塞和延时。
另一种维度的统一
反过来想,能否在保持FPGA灵活性的情况下,做成统一平台,这种探索是可行的,这种探索雪湖信息科技一直在坚持。
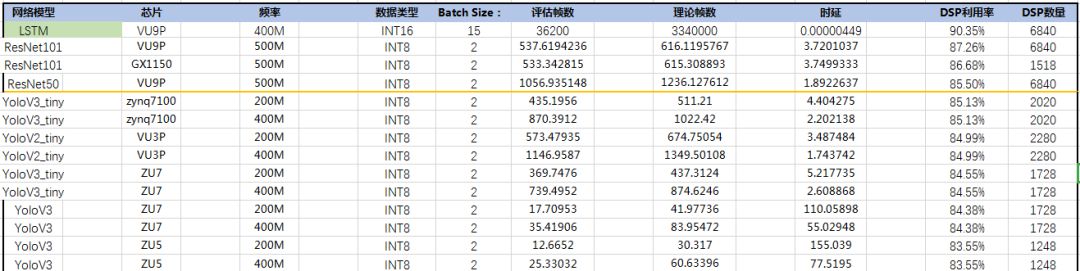
图7(各个网络/芯片平台的评估数据表)
控制参数在处理平台的灵活性,而模块化的开发则是开发平台的基石ptero在开发卷积过程中不断的积累现有的卷积模块/非卷积模块,在不断的打磨过程中将平台的核心库不断的更新/优化,这些高效的模块才是能兼顾通用和灵活的关键所在。
当这种模块经过实践证明可行之后,雪湖开发出了自动化工具平台,该工具平台包括自动解析网络结构、生成控制参数、生成计算参数、推荐相应的模块、分配合理的FPGA资源等等内容。
同时会包含自动测试部分,有了自动化工具的支持,对平台的通用性和便捷性提到了一个新的高度。
如下图,便是自动化测试工具测试示例:
已经实现的卷积算法计算量在5.3 Gflops左右(算法的细节涉及机密不便展开),用znq7020里进行实现,dsp利用率在88.88%左右,下图为自动测试工具生成结果图:
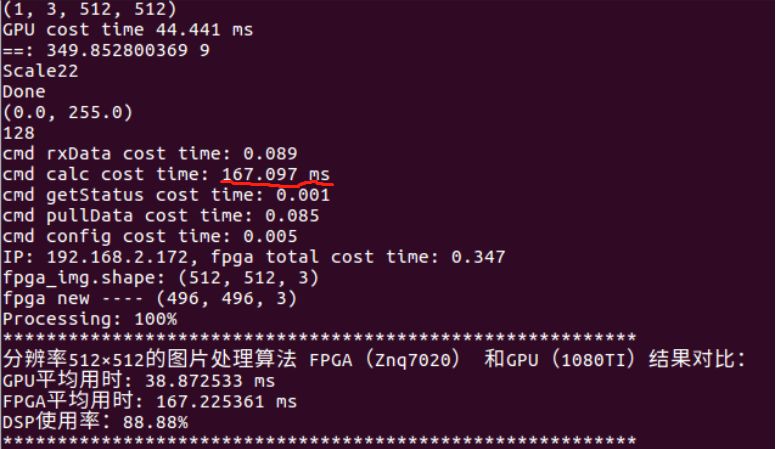
图8(自动测试工具生成结果图)
自动化工具是自适应FPGA开发平台的浓缩表现,可以根据不同的算法推荐不同的方案,通过生成的不同的控制参数来合理的分配FPGA资源使用。随着该平台的不断更新和升级,最终完成一键式端到端的FPGA实现方案。
通过这种方式,最终解决FPGA开发中通用性和灵活性的问题,这是雪湖不遗余力去追求的目标。
通过这种方式,不同的用户可以根据自己的需求进行不同的配置,得到高性价比的FPGA开发方案。
同时,更重要的是该方案不需要修改网络结构,不需要对用户的数据进行重新训练,从而保护用户的核心资产。
而同时,由于FPGA的高度可配置性,当用户的算法进行更新时,可以快速的修改和部署,这也是保护用户投资的有效手段。
总之,从复杂到简单,由繁琐到简洁,是事物发展的普遍规律。
而将FPGA开发的由难到易,以工具建平台,以平台来培养人才,在灵活易用的FPGA芯片上,解决应用开发难题,能够加快AI算法的快速落地。
-
平衡创新与伦理:AI时代的隐私保护和算法公平2024-07-16 1238
-
FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......2025-03-03 7711
-
【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》2025-07-28 55058
-
AI 芯片浪潮下,职场晋升新契机?2025-08-19 672
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战2025-09-12 3908
-
求助-在FPGA上实现retinex算法2013-05-08 2077
-
电子元器件+AI创新发展论坛2017-11-15 3326
-
AI芯片谈算法不谈智能,谈实现不谈芯片!2018-08-24 3438
-
手把手教你设计人工智能芯片及系统--(全阶设计教程+AI芯片FPGA实现+开发板)2019-07-19 8951
-
29页PPT,详细介绍Ouroboros的语音AI芯片2019-10-16 3198
-
【免费直播】AI芯片专家陈小柏博士,带你解析AI算法及其芯片操作系统。2019-11-07 3776
-
AI芯片热潮和架构创新有什么作用2020-04-23 2402
-
AI芯片热潮和架构创新是什么2020-04-24 2130
-
在FPGA上实现CRC算法的程序2016-06-07 1130
-
在 FPGA 上实施 AI/ML 的选项2022-12-28 1760
全部0条评论

快来发表一下你的评论吧 !
