

设计了一个强强联合型模型来预测股票价格,为什么这么形容?
电子说
描述
【导语】用深度学习预测股票价格不是一个新话题,随着技术的不断发展,大家一直在不断尝试新技术。这次教程中,作者设计了一个强强联合型模型来预测股票价格,为什么这么形容?作者设计了一个 GAN 模型,其生成网络为 LSTM 模型用来预测时间序列数据、CNN 模型作判别网络,用 BERT 模型作为情绪分析模型。带有高斯过程的贝叶斯优化和深度强化学习方法来获得 GAN 的超参数。为什么创建这样的组合?都将在下面的内容中为大家进行一一解答。
这篇教程的篇幅很长,为了让大家能对重要技术内容一目了然,作者在开始加入了层级清晰的目录,主要从【背景】、【数据特征】、【GAN 模型架构】、【超参数优化】等几大方面进行全面讲解。





下面营长对其中涉及的技术细节进行了编译:
背景
在今天的任务中,预测的是高盛公司(本文中会简称为 GS)的股票变化趋势,使用 2010 年 1 月 1 日至 2018 年 12 月 31 日的日收盘价作为训练(七年)和测试(两年)数据。
成功训练一个 GAN 最棘手的部分是获得正确的超参数。为此,作者使用 Bayesian optimisation(带有高斯过程的贝叶斯优化)和用于决定何时以及如何改变 GAN 的超参数的深层强化学习(DRL),在创建强化学习过程中,将使用一些最新技术,如 RAINBOW 和 PPO。
此外,在模型中还使用许多不同类型的输入数据。随着股票的历史交易数据和技术指标,设计了一些技术方法,如使用 NLP 中的 BERT 来创建情绪分析模型(作为基本面分析的来源),以及用傅立叶变换(Fourier transforms)提取总体趋势方向、识别其他高级特征的栈式自动编码器( Stacked autoencoder);采用特征投资组合寻找相关资产;采用 ARIMA 方法进行股票函数近似。实际上,这些技术都是为了尽可能多的获取关于股票的信息、模式、依赖关系等等。
开发环境和框架选择 MXNet 和其高级 API(Gluon)创建所有的神经网络,并在多个 GPU 上进行训练。
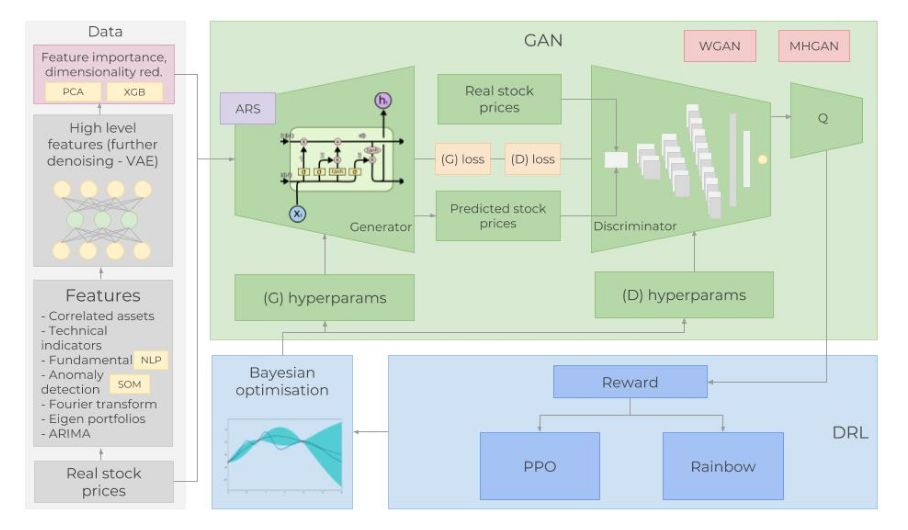
图:完整体系结构概览
通过上面的技术背景介绍,相信大家已经感觉到想准确预测股市是一项非常复杂的任务,影响股票变化的事件、条件或因素等实在是太多了。所以,想更好的了解这些先决条件,还需要先做几个重要的假设:(1)市场不是 100% 的随机;(2)历史重复;(3)市场遵循人们的理性行为;(4)市场是“完美的”。
数据
首先,要了解什么因素会影响 GS 的股票价格波动,需要包含尽可能多的信息(从不同的方面和角度)。将使用 1585 天的日数据来训练各种算法(70% 的数据),并预测另外 680 天的结果(测试数据)。然后,将预测结果与测试数据进行比较。每种类型的数据(亦称为特征)将在后面的部分中详细解释。
简而言之,将使用的特征有:
a.相关资产:涉及商品、外汇、指数、固定收益证券等各类资产数据;影响高盛公司股票价格趋势的外部因素又有很多,并且很复杂,包括竞争对手、客户、全球经济、地缘政治形势、财政和货币政策等等,这些因素还会相互产生影响。选择合适的相关资产是非常重要的:
(1)首先是和 GS 相似的公司,如将摩根大通(JPMorgan Chase)和摩根士丹利(Morgan Stanley)等加入数据集。
(2)作为一家投资银行,高盛依赖于全球经济,需要关注全球经济指数和 libor 利率。
(3)每日波动指数(VIX)。
(4)综合指数,如 NASDAQ 和 NYSE(美国)、FTSE 100(英国)、日经指数 225(日本)、恒生指数和 BSE Sensex(APAC)指数。
(5)货币,全球贸易多次反映在货币流动中,使用一篮子货币(如美元-日元、英镑-美元等)作为特征。
总的来说,在数据集中还有 72 个其他资产(每个资产的每日价格)。
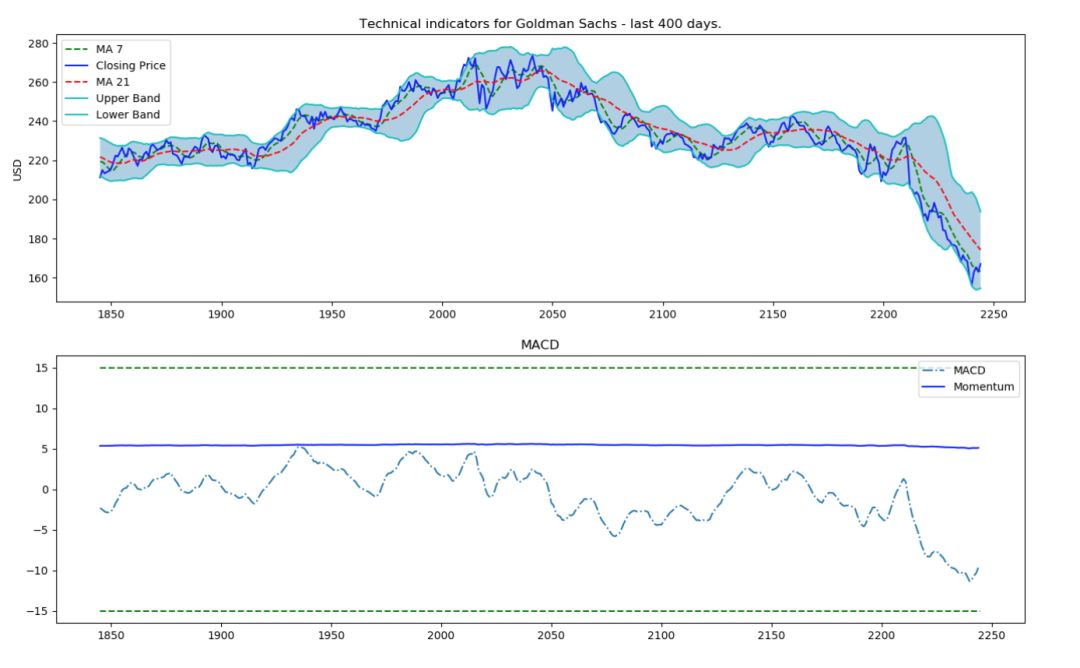
b.技术指标:许多投资人都会关注技术指标,在这里,把最受欢迎的指标作为独立特征,包括 7 天和 21 天波动平均值、指数波动平均、Momentum、MACD 等 12项技术指标。
def get_technical_indicators(dataset): # Create 7 and 21 days Moving Average dataset['ma7'] = dataset['price'].rolling(window=7).mean() dataset['ma21'] = dataset['price'].rolling(window=21).mean() # Create MACD dataset['26ema'] = pd.ewma(dataset['price'], span=26) dataset['12ema'] = pd.ewma(dataset['price'], span=12) dataset['MACD'] = (dataset['12ema']-dataset['26ema']) # Create Bollinger Bands dataset['20sd'] = pd.stats.moments.rolling_std(dataset['price'],20) dataset['upper_band'] = dataset['ma21'] + (dataset['20sd']*2) dataset['lower_band'] = dataset['ma21'] - (dataset['20sd']*2) # Create Exponential moving average dataset['ema'] = dataset['price'].ewm(com=0.5).mean() # Create Momentum dataset['momentum'] = dataset['price']-1 return datasetdataset_TI_df = get_technical_indicators(dataset_ex_df[['GS']])dataset_TI_df.head()
c.基本面分析:无论股票涨跌,这都是一个非常重要的数据。分析时会用到两个特征:公司业绩报告和新闻将引导的一些趋势,因此通过分析新闻来准确预测市场的情绪也是一项非常重要的工作,所以这次的方法中,将使用 BERT 来构建情绪分析模型,提取股票新闻中的情绪倾向。最后采用 sigmoid 归一化,结果介于 0 到 1 之间,(0 表示负面情绪,1 表示正面情绪),每一天都会创建一个平均每日分数作为一个特征添加。
使用的是 MXNet 中 Gluon NLP 库中所提供的经过预训练的 BERT 模型,大家可以尝试一下。此前我们也为大家介绍过简单易上手的 Gluon,详情可参考营长亲自上手的教程。
d.傅里叶变换:利用每日收盘价,创建傅立叶变换,以获得几个长期和短期趋势。使用这些变换消除大量的噪声,获得真实股票波动的近似值。有了趋势近似,可以帮助 LSTM 网络更准确地选择其预测趋势。
data_FT = dataset_ex_df[['Date', 'GS']]close_fft = np.fft.fft(np.asarray(data_FT['GS'].tolist()))fft_df = pd.DataFrame({'fft':close_fft})fft_df['absolute'] = fft_df['fft'].apply(lambda x: np.abs(x))fft_df['angle'] = fft_df['fft'].apply(lambda x: np.angle(x))plt.figure(figsize=(14, 7), dpi=100)fft_list = np.asarray(fft_df['fft'].tolist())for num_ in [3, 6, 9, 100]: fft_list_m10= np.copy(fft_list); fft_list_m10[num_:-num_]=0 plt.plot(np.fft.ifft(fft_list_m10), label='Fourier transform with {} components'.format(num_))plt.plot(data_FT['GS'], label='Real')plt.xlabel('Days')plt.ylabel('USD')plt.title('Figure 3: Goldman Sachs (close) stock prices & Fourier transforms')plt.legend()plt.show()
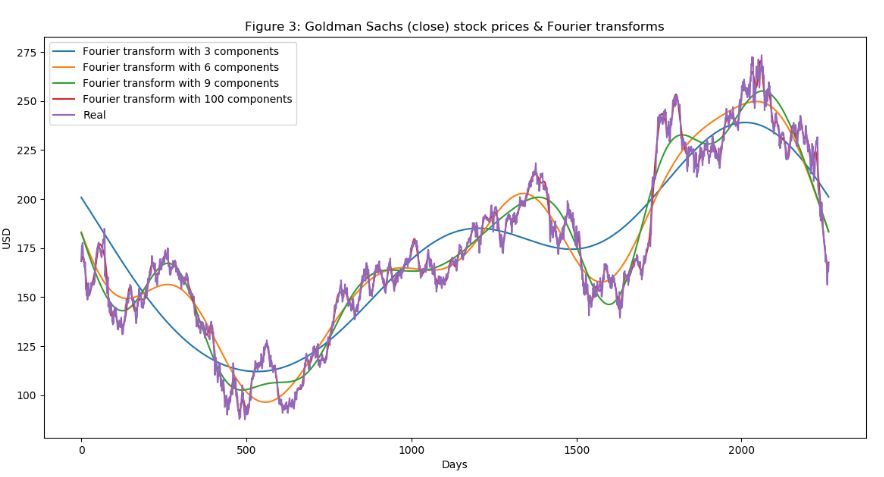
图:高盛股票的傅里叶变换
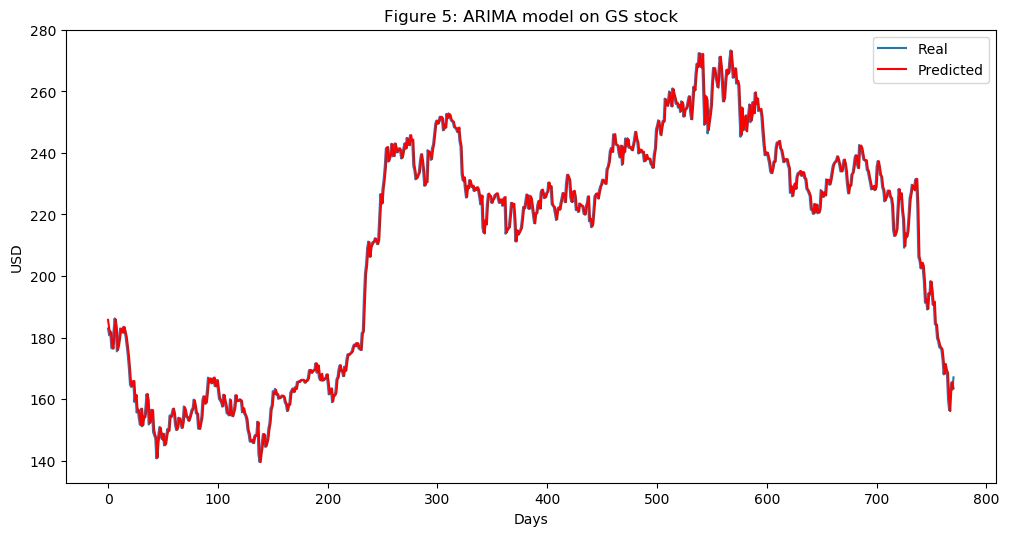
e.ARIMA:这是预测时间序列数据未来值的最流行技术之一。
from pandas import read_csvfrom pandas import datetimefrom statsmodels.tsa.arima_model import ARIMAfrom sklearn.metrics import mean_squared_errorX = series.valuessize = int(len(X) * 0.66)train, test = X[0:size], X[size:len(X)]history = [x for x in train]predictions = list()for t in range(len(test)): model = ARIMA(history, order=(5,1,0)) model_fit = model.fit(disp=0) output = model_fit.forecast() yhat = output[0] predictions.append(yhat) obs = test[t] history.append(obs)error = mean_squared_error(test, predictions)print('Test MSE: %.3f' % error)Test MSE: 10.151# Plot the predicted (from ARIMA) and real pricesplt.figure(figsize=(12, 6), dpi=100)plt.plot(test, label='Real')plt.plot(predictions, color='red', label='Predicted')plt.xlabel('Days')plt.ylabel('USD')plt.title('Figure 5: ARIMA model on GS stock')plt.legend()plt.show
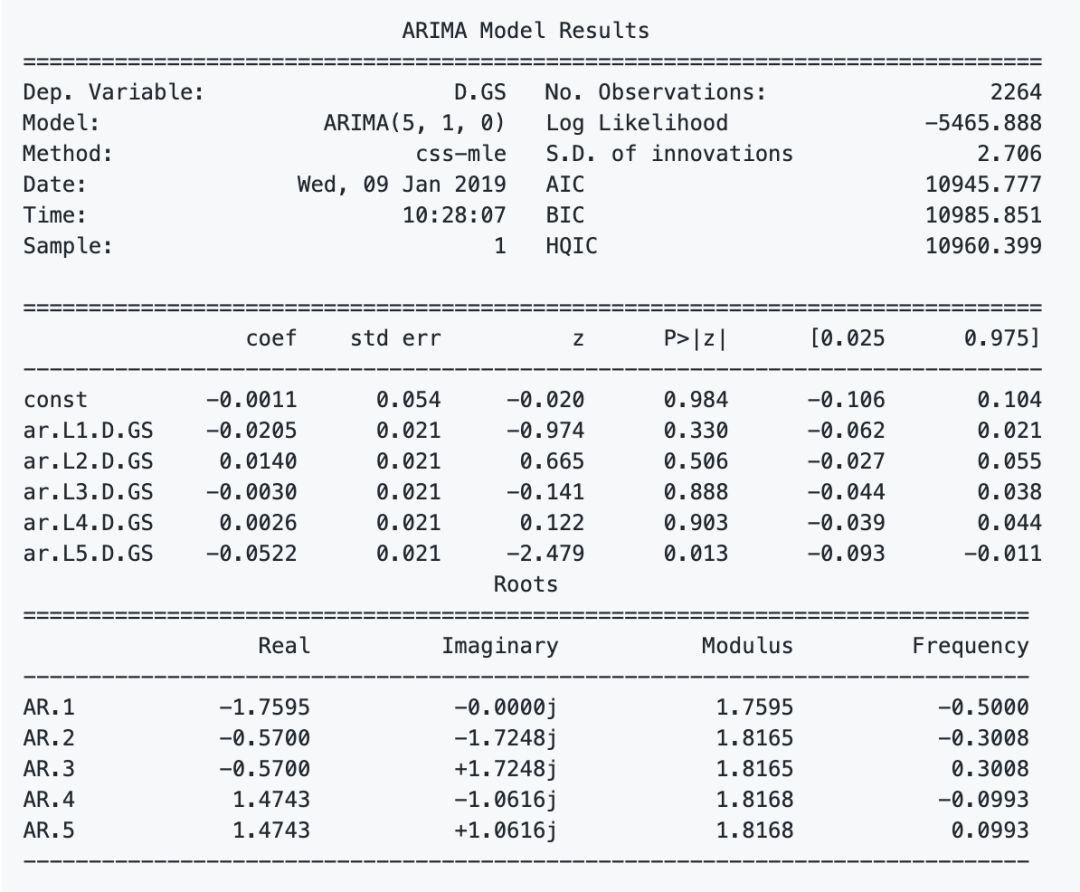
f.Stacked autoencoders (栈式自动编码器):上面提到的一些特征是研究人员经过几十年的研究发现的,但是还是会忽视一些隐藏的关联特征,由此,Stacked autoencoders 就可以解决这个问题,通过学习每个隐藏层,发现更多新特征(可能有些是我们无法发现,理解的)。这次没有把 RELU 作为激活函数,而是使用了 GELU,也可以用于 BERT 模型中。至于为什么选择 GELU,大家可以在原文中看到作者给出的和 RELU 对比的实例。
g.深度无监督学习:用于期权定价中的异常检测,将再使用一个特征:每天都会增加高盛股票90天看涨期权的价格。期权定价本身结合了很多数据。期权合约的价格取决于股票的未来价值(分析师也试图预测价格,以便为看涨期权得出最准确的价格)。使用深度无监督学习(自组织映射),尝试发现出现异常的每日价格。异常(如价格的剧烈变化)可能表明出现了一个事件,这有助于LSTM了解整体股票模式。
from utils import *import timeimport numpy as npfrom mxnet import nd, autograd, gluonfrom mxnet.gluon import nn, rnnimport mxnet as mximport datetimeimport seaborn as snsimport matplotlib.pyplot as plt%matplotlib inlinefrom sklearn.decomposition import PCAimport mathfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.metrics import mean_squared_errorfrom sklearn.preprocessing import StandardScalerimport xgboost as xgbfrom sklearn.metrics import accuracy_scoreimport warningswarnings.filterwarnings("ignore")context = mx.cpu(); model_ctx=mx.cpu()mx.random.seed(1719)Note: The purpose of this section (3. The Data) is to show the data preprocessing and to give rationale for using different sources of data, hence I will only use a subset of the full data (that is used for training).def parser(x): return datetime.datetime.strptime(x,'%Y-%m-%d')dataset_ex_df = pd.read_csv('data/panel_data_close.csv', header=0, parse_dates=[0], date_parser=parser)dataset_ex_df[['Date', 'GS']].
接下来,有了这么多特征,还需要执行几个重要步骤:
h.对数据的“质量”进行统计检查:确保数据质量对模型来说非常重要,因此要执行以下几个简单的检验,如异方差、多重共线性、Serial correlation 等。
i.确定特征重要性:采用 XGBoost 算法。这么多的特征,必须考虑是否所有这些都真正地指示了 GS 股票波动方向。例如,数据集中包括其变化可能意味着经济变化的 LIBOR,而这又可能暗示 GS 股票将会发生波动,因此需要对此预测进行测试,在众多的测试方法中,本教程中选择了 XGBoost,其在分类和回归问题上都提供了很好的结果。
def get_feature_importance_data(data_income): data = data_income.copy() y = data['price'] X = data.iloc[:, 1:] train_samples = int(X.shape[0] * 0.65) X_train = X.iloc[:train_samples] X_test = X.iloc[train_samples:] y_train = y.iloc[:train_samples] y_test = y.iloc[train_samples:] return (X_train, y_train), (X_test, y_test)# Get training and test data(X_train_FI, y_train_FI), (X_test_FI, y_test_FI) = get_feature_importance_data(dataset_TI_df)regressor = xgb.XGBRegressor(gamma=0.0,n_estimators=150,base_score=0.7,colsample_bytree=1,learning_rate=0.05)xgbModel = regressor.fit(X_train_FI,y_train_FI, \ eval_set = [(X_train_FI, y_train_FI), (X_test_FI, y_test_FI)], \ verbose=False)eval_result = regressor.evals_result()training_rounds = range(len(eval_result['validation_0']['rmse']))
最后一步,使用主成分分析(PCA)创建特征组合,以减少自动编码器生成特征的维数。在自动编码器中创建了 112 个特征,不过高维特征对我们的价值更大,所以在这 112 个特征的基础上通过 PCA 创建高维的特征组合,减少数据维度。不过,这也是我们提出的实验性方法。
plt.figure(figsize=(15, 5))plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=.5, hspace=None)ranges_ = (-10, 3, .25)plt.subplot(1, 2, 1)plt.plot([i for i in np.arange(*ranges_)], [relu(i) for i in np.arange(*ranges_)], label='ReLU', marker='.')plt.plot([i for i in np.arange(*ranges_)], [gelu(i) for i in np.arange(*ranges_)], label='GELU')plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')plt.title('Figure 7: GELU as an activation function for autoencoders')plt.ylabel('f(x) for GELU and ReLU')plt.xlabel('x')plt.legend()plt.subplot(1, 2, 2)plt.plot([i for i in np.arange(*ranges_)], [lrelu(i) for i in np.arange(*ranges_)], label='Leaky ReLU')plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')plt.ylabel('f(x) for Leaky ReLU')plt.xlabel('x')plt.title('Figure 8: LeakyReLU')plt.legend()plt.sho
让我们看一下过去 9 年的股价变化。虚线表示训练数据和测试数据之间的分割线。
plt.figure(figsize=(14, 5), dpi=100)plt.plot(dataset_ex_df['Date'], dataset_ex_df['GS'], label='Goldman Sachs stock')plt.vlines(datetime.date(2016,4, 20), 0, 270, linestyles='--', colors='gray', label='Train/Test data cut-off')plt.xlabel('Date')plt.ylabel('USD')plt.title('Figure 2: Goldman Sachs stock price')plt.legend()plt.show()
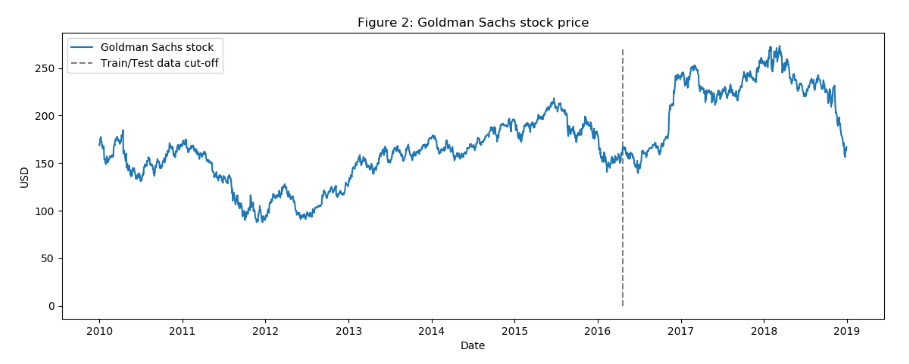
图:过去9年高盛股价的波动
num_training_days = int(dataset_ex_df.shape[0]*.7)print('Number of training days: {}. Number of test days: {}.'.format(num_training_days, \ dataset_ex_df.shape[0]-num_training_days))Number of training days: 1585. Number of test days: 680.
生成对抗性网络(GAN)
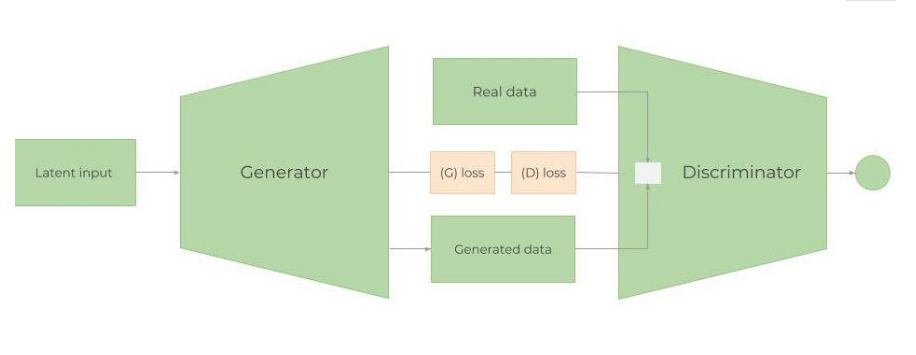
图:GAN 架构
1、为什么采用GAN进行股市预测?
GAN 最多被应用在创作逼真的图像、画作和视频剪辑等。对预测时间序列数据的应用并不多。但这两者的思想都是类似的。我们希望预测未来的股票价格,GS 的股票波动和行为应该大致相同(除非开始以完全不同的方式运作,或者经济急剧变化)。因此,希望“生成”的数据与已经拥有的历史交易数据分布相似,当然不是完全相同。在这个例子中将使用 LSTM 作为时间序列生成模型,CNN 作为判别模型。
2、Metropolis-Hastings GAN 和 Wasserstein GAN
(1)Metropolis-Hastings GAN:与传统的 GAN 相比,Uber 团队最近提出一种新改进的 GAN 模型——Metropolis-Hastings GAN (MHGAN),它有点类似于谷歌和加州大学伯克利分校提出的Discriminator Rejection Sampling。通常情况下,在训练完GAN之后就不再使用 D 了。然而,MHGAN 和 DRS 试图使用 D 来选择由 G 生成的接近真实的样本。
(2)Wasserstein GAN:训练 GAN 是相当困难的。模型可能永远不会收敛,模式崩溃也很容易发生。,通过 Wasserstein GAN 尝试解决这个问题。KL 距离和 JS 距离是两种常用的分布,而 WGAN 使用的是 Wasserstein distanc。
3、生成模型:单层RNN
(1)LSTM 还是 GRU?
关于 RNN、LSTM 等模型的基础介绍这里不多做赘述,主要聚焦在 RNN 在时间序列数据上的应用,因为它们可以跟踪所有以前的数据点,并且可以捕获经过时间发展的模式。可以通过裁剪解 RNN 梯度消失或梯度爆炸问题。
在精度方面,LSTM 和 GRU 的结果相差不多,但是 GRU 使用的训练参数要比 LSTM 少,计算强度也要小。
(2)LSTM 体系结构
LSTM架构非常简单:一个LSTM层,包含112个输入单元(数据集中有112个特征)和500个隐藏单元;一个以每日股价为输出的 Dense 层;采用 Xavier 初始化,使用 L1 损失函数
在下面的代码中,采用adam作为优化器,学习率为 0.01。
gan_num_features = dataset_total_df.shape[1]sequence_length = 17class RNNModel(gluon.Block): def __init__(self, num_embed, num_hidden, num_layers, bidirectional=False, \ sequence_length=sequence_length, **kwargs): super(RNNModel, self).__init__(**kwargs) self.num_hidden = num_hidden with self.name_scope(): self.rnn = rnn.LSTM(num_hidden, num_layers, input_size=num_embed, \ bidirectional=bidirectional, layout='TNC') self.decoder = nn.Dense(1, in_units=num_hidden) def forward(self, inputs, hidden): output, hidden = self.rnn(inputs, hidden) decoded = self.decoder(output.reshape((-1, self.num_hidden))) return decoded, hidden def begin_state(self, *args, **kwargs): return self.rnn.begin_state(*args, **kwargs)lstm_model = RNNModel(num_embed=gan_num_features, num_hidden=500, num_layers=1)lstm_model.collect_params().initialize(mx.init.Xavier(), ctx=mx.cpu())trainer = gluon.Trainer(lstm_model.collect_params(), 'adam', {'learning_rate': .01})loss = glu
(3)学习率调度器
学习率是非常重要的参数之一,每个优化器设置学习率,如 SGD、Adam 或 RMSProp 在训练神经网络时至关重要,因为它既控制着网络的收敛速度,又控制着网络的最终性能,接下来就要确定每个阶段的学习率。
class TriangularSchedule(): def __init__(self, min_lr, max_lr, cycle_length, inc_fraction=0.5): self.min_lr = min_lr self.max_lr = max_lr self.cycle_length = cycle_length self.inc_fraction = inc_fraction def __call__(self, iteration): if iteration <= self.cycle_length*self.inc_fraction: unit_cycle = iteration * 1 / (self.cycle_length * self.inc_fraction) elif iteration <= self.cycle_length: unit_cycle = (self.cycle_length - iteration) * 1 / (self.cycle_length * (1 - self.inc_fraction)) else: unit_cycle = 0 adjusted_cycle = (unit_cycle * (self.max_lr - self.min_lr)) + self.min_lr return adjusted_cycleclass CyclicalSchedule(): def __init__(self, schedule_class, cycle_length, cycle_length_decay=1, cycle_magnitude_decay=1, **kwargs): self.schedule_class = schedule_class self.length = cycle_length self.length_decay = cycle_length_decay self.magnitude_decay = cycle_magnitude_decay self.kwargs = kwargs def __call__(self, iteration): cycle_idx = 0 cycle_length = self.length idx = self.length while idx <= iteration: cycle_length = math.ceil(cycle_length * self.length_decay) cycle_idx += 1 idx += cycle_length cycle_offset = iteration - idx + cycle_length schedule = self.schedule_class(cycle_length=cycle_length,**self.kwargs) return schedule(cycle_offset) *self.magnitude_decay**cycle_idx
(4)防止过拟合与偏差-方差权衡
防止过拟合,注意总损失也是要在训练模型中非常重要的一个问题。不仅在生成器中的 LSTM 模型,判别器中的 CNN 模型、自动编码器中都使用了几种防止过拟合的技术:
a.确保数据质量
b.正则化,或权重惩罚:最常用的两种正则化技术是L1 和 L2 正则法。L1对离散值更有鲁棒性,当数据稀疏时使用,可得到特征重要性。因此,在股票价格预测这个应用案例中将使用 L1 正则法。
c.Dropout。Dropout层随机删除隐藏层中的节点。
d.Dense-sparse-dense training
e.提前停止.
(5)权衡偏差-方差
建立复杂神经网络时,另一个重要的考虑因素是偏差-方差权衡。训练网络的误差基本上是偏差、方差和不可约误差 σ(噪声和随机性引起的误差)的函数。
最简单的权衡公式是:误差=偏差^2+方差+σ.
a.偏差(Bias):偏差衡量一个经过训练的(训练数据集)算法对未见数据的概括能力。高偏差(欠拟合)意味着模型在隐藏数据上不能很好地工作。
b.方差(Variance):方差衡量模型对数据集变化的敏感性。高方差意味着过拟合。
4、 一维 CNN 判别模型
(1)为何采用CNN作为判别模型?
CNN 网络在提取隐藏特征等工作上具有优势,那如何应用于这个任务中?大家不妨尝试一下,数据点行程小趋势,小趋势行程大趋势,趋势反之形成模式,而 CNN 在此用检测特征的能力来提取 GS 股价趋势中的模式信息。
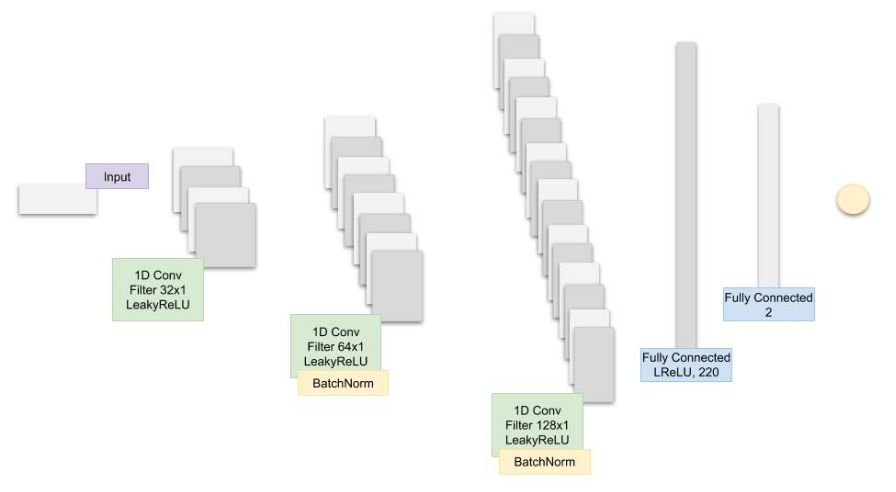
图:本文提出的 CNN 模型的体系结构。
超参数优化
(1)跟踪和优化的超参数是:
batch_size:LSTM 和 CNN 的 Batch 大小
cnn_lr:CNN 的学习率
strides:CNN 的跨步卷积数
lrelu_alpha:GAN 中 LeakyReLU 的 Alpha 值
batchnorm_momentum:CNN Batch 正则化的 momentum
padding:CNN 中的 Padding
kernel_size:1 CNN 的内核大小
dropout:LSTM 中的 Dropout 层
filters:过滤器的初始数目
epoch = 200
(2)超参数优化
经过 200 次 GAN 训练后,将记录 MAE(LSTM、GG 中的误差函数)并作为奖励值传递给强化学习(RL)模型,以决定是否用同一组超参数来改变保持训练的超参数,如果RL决定更新超参数,它将调用 Bayes 优化库。
(3)超参数优化中的强化学习
为什么在超参数优化中使用强化学习?股票市场一直在变化。即使能够训练 GAN 和 LSTM 来创造非常精确的结果,结果也只能在一定的时间内有效。也就是说,我们需要不断优化整个过程。为了优化这一过程,可以添加或删除特征,或改进深度学习模型。改进模型的最重要的方法之一就是通过超参数。一旦找到了一组特定的超参数,就需要决定何时修改它们,以及何时使用已经知道的集合(探索或利用)。此外,股票市场代表了一个依赖于数百万参数的连续空间。
(4)强化学习理论
使用无模型的 RL 算法,原因很明显,我们不知道整个环境,因此没有关于环境如何工作的定义模型(如果存在,就不需要预测股票价格的变化)。使用两个细分的无模型RL:策略优化(Policy Optimization)和 Q-Learning。构建 RL 算法的一个关键方面是精确设置奖励。它必须捕捉环境的所有方面以及代理与环境的交互。
a.Q-Learning:一种基于Q-Learning的非策略深度强化学习算法,它将7种算法结合在一起:DQN、Double Q Learning(双QL)、Prioritized replay、决斗网络(Dueling networks)、多步学习、分布式RL、噪声网络(Noisy Nets)。在Q-Learning中,学习价值从某一状态采取行动。Q 值采取行动后的预期回报。
b.策略优化:这里采用近端策略优化(Proximal Policy Optimization, PPO),在决策优化中,学习从某一状态采取的行动。(如果使用诸如Actor/Critic之类的方法,也会了解处于给定状态的价值。
(5)贝叶斯优化
使用贝叶斯优化,不采用网格搜索,因为可能需要很长时间才能找到超参数的最佳组合。
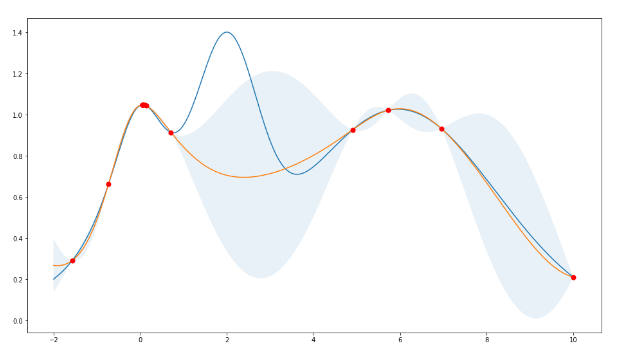
图:贝叶斯超参数优化的高斯过程
5、结果
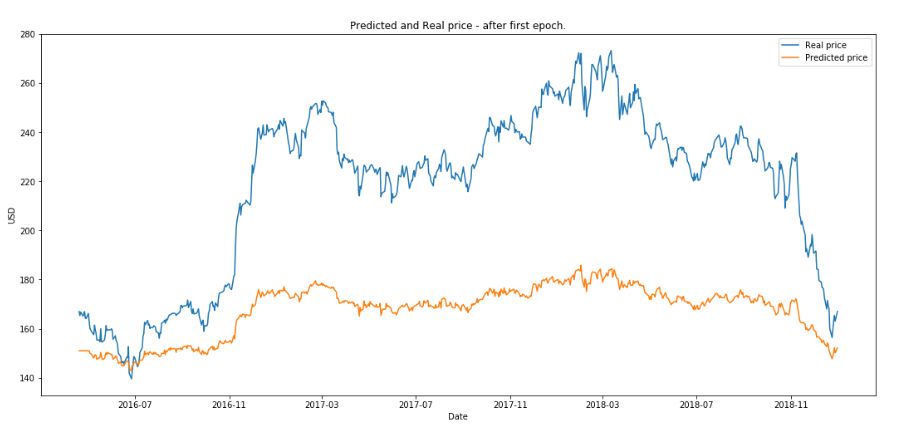
最后,使用测试数据作为不同阶段的输入,LSTM 的输出与实际股价进行比较:
(1)绘制第一次训练之后的结果
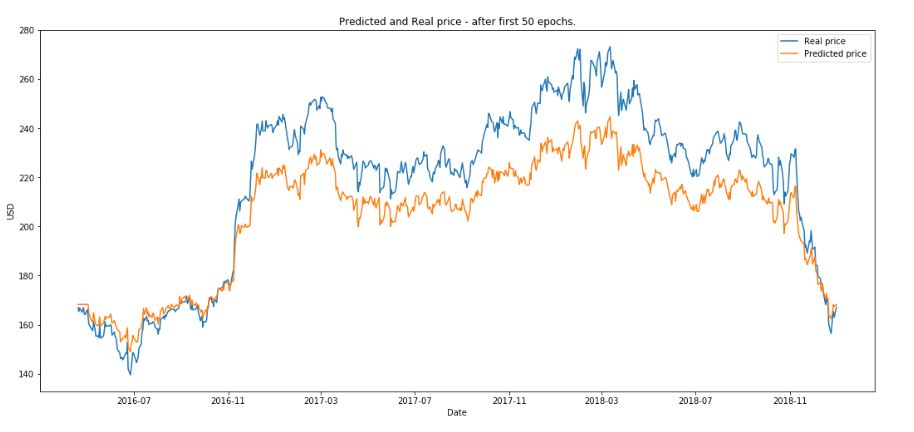
(2)绘制 50 次训练后的结果。
(3)绘制 200 次训练后的结果。
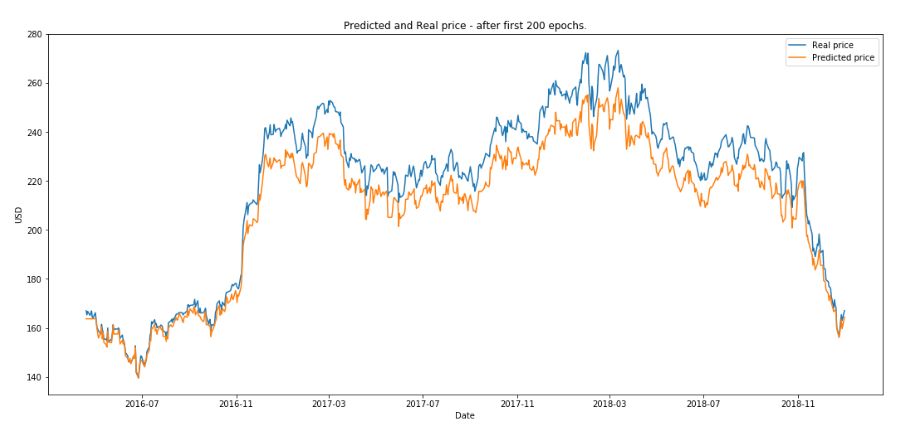
RL 运行了 10 eposide ,本文定义一个 eposide 是 GAN 完整训练 200 次后,下图是得到的最终的结果。
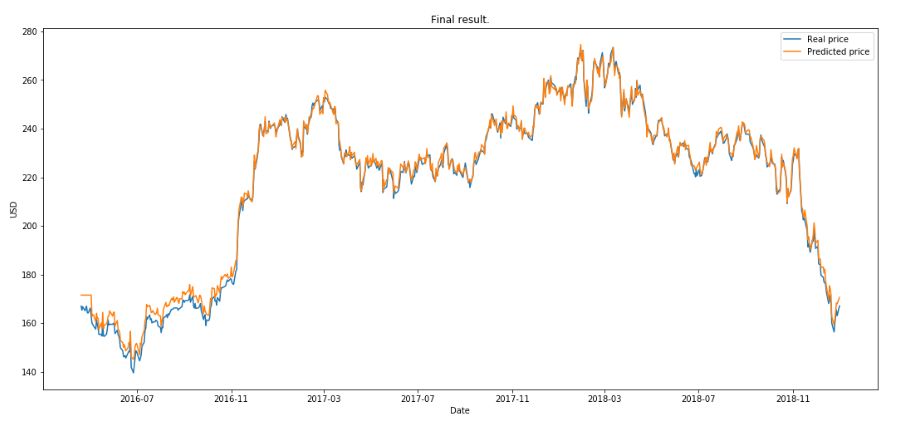
总结
可见,作者在把各路强模型联合打造的结果还是非常优秀的。不过作者还尝试创建一个 RL 环境,用于测试决定何时以及如何进行交易的交易算法。GAN 的输出将是此环境中的一个参数,虽然这些都不能完全做到预测的作用,但是在实际任务中不断尝试新技术还是很有意义的,期待作者后续工作可以带来更好的结果。
-
【内测活动同步开启】这么小?这么强?新一代大模型MCP开发板来啦!2025-09-25 1042
-
基于网络共识的股票价格行为数据挖掘(英文2010-04-24 2763
-
炒股福利:树莓派股票查询库(Python)2016-01-06 11947
-
模型预测控制+逻辑控制2021-08-17 1896
-
使用keras搭建神经网络实现基于深度学习算法的股票价格预测2022-02-08 1883
-
基于混沌时间序列分析的股票价格预测2009-02-18 1989
-
基于CART和相似股的股票价格走势预测算法研究2017-11-28 799
-
基于支持向量回归的交易模型的稳健性策略2017-12-05 780
-
利用人工智能,成功预测了2020年2月18日当前的市场崩溃2020-03-01 2588
-
基于LSTM和遗传算法的股票价格涨跌预测模型2021-06-17 4014
-
LSTM GRU Bidirectional-LSTM股票预测2021-12-05 682
全部0条评论

快来发表一下你的评论吧 !
