

微软美国研究院和清华联合推出了一款开源的多领域端到端对话系统平台—ConvLab
电子说
描述
近年来对话系统迅速发展,同时也出现了一系列丰富的数据集。但对于刚刚进入这一领域团队来说,迅速搭建起对于特定任务的可用的对话系统依然充满挑战。这主要是由于这一领域内缺乏结构完善、易于使用的开源系统,让研究人员可以便捷的搭建和测评对话机器人。
众所周知,基础性的开源系统为AI研究的突破打下了坚实的基础,在这一领域的Moses、HTK和CoreNLP等项目都被广泛用于机器翻译、语音识别和自然语言处理,推动了各层次研究的飞速发展。
为了促进这一领域的发展,微软美国研究院和清华联合推出了一款开源的多领域端到端对话系统平台—ConvLab,使得研究人员可以便捷地搭建对话系统、自动训练对话模型、构建并评测对话机器人的各方面表现。
ConvLab
为了便于用于构建不同类型任务导向的机器人、将更多的自动化引入构建、训练和测评过程中,ConvLab包含了丰富的模型工具和运行引擎、以及端到端的测评平台。简单来讲台中包含了基于模块和端到端两种架构类型的对话系统:基于模块的架构系统包含了自然语言理解(NLU)、对话系统追踪(DST)、对话策略(POL)和自然语言生成(NLG)等模块;完全端到端神经架构减少了手工编程的工作量,并减小了误差在工作流程中的传播。
与先前工具集集中于系统策略或者受限于固定的预训练模型不同,ConvLab基于全标注的数据集覆盖了所有可训练的统计模型,解决了先前对于系统性能度量的困难。
很多时候用户需要在多子域之间无缝衔接实现高层用户目标,多层级的对话系统对数据收集、标注以及模型的开发都提出了复杂的要求。有研究人员提出了MultiWOZ数据集(包含了旅行相关的多邻域对话内容),但目前却缺乏对应的开源平台来处理多域多意图对话。为了加速多领域对话的研究ConvLab研究了MultiWOZ任务的特征,并提供了一系列完整的参考模型(包含了独立的模块和端到端模型)、这些模型在为用户对话额外标注的MultiWOZ数据集上进行了训练。ConvLab目前还作为DSTC18多领域端到端对话追踪的标准平台,得到了更广泛的应用和实际的检验。为了更好的支持端到端评价、ConvLab提供了两个互补模块、分别集成了亚马逊Amazon Mechanical Turk平台用于人类测评、同时也集成了虚拟用户用于自动测评。针对用户仿真,平台同时提供了基于规则和基于数据驱动的模拟器。ConvLab在开发模拟用户的过程中也研发出了一系列先进的用户模拟技术。
架构设计
整个系统基于模块化的设计保障了灵活性和适应性。为了支持多领域对话系统的搭建,平台使用了主体-环境-对话实体的组合设计(Agents-Environments-Bodies,AEB),除了单环境和单主体的配置外,系统还包含了一系列先进的研究实验、包括多任务学习、多主体学习和角色扮演、无需复杂的代码即可导入到实例中使用。

此外,为了系统性地对比不同的主体和环境,并实现自动超参数搜索,平台充分利用了SLM Lab和Ray^2 作为实验组件。他们提供了多层级的控制,从会话、尝试和试验上为每一层次生成评测报告。
其中会话用于初始化主体和环境、并以预设的轮次运行。随后利用随机种子来启动多个会话进行尝试、并最终在会话上分析并求平均。最后利用实验来确定不同超参数的表现。
对话主体和环境的配置
在系统中每个层代表了构建对话系统的不同方式,在下图中可以看到最上层代表了传统方式构建对话系统的架构路线图,包括了NLU,DST,POL,NLG。研究人员近年来通过引入词级对话状态追踪、对话策略和端到端模型等典型组件,探索了构建对话系统不同可能的组合实现形式。在ConvLab平台上,研究人员可以聚焦于下图中的任意组件,并以端到端的简单方式进行测试。
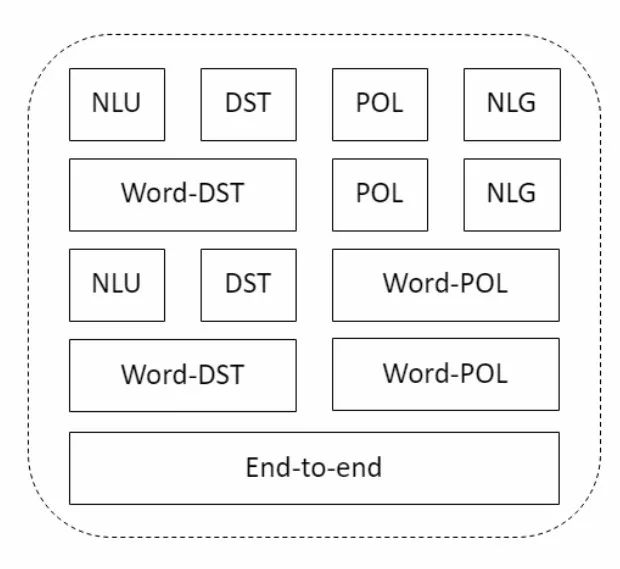
对于环境构建来说,可以由很可能的组件来进行构建。在研究对话策略优化的强化学习算法中,典型的方法是利用用户模拟器在对话行为层级上进行操作。对话主体会尽可能利用端到端的方式尝试减小对标注数据的需求,对于人类评测来说平台提供了基于Amazon Mechanical Turk来作为最后一层进行环境构建。

参考模型和跨域数据实验
在ConvLab中还涵盖了针对多重任务的模型供研究人员进行参考评测,包括了自然语言理解领域的Semantic Tuple Classi-fier (STC)、 OneNet以及作为拓展的Multi-intent LU (MILU);对话状态追踪引入了DSTCs基准模型、词级对话状态追踪领域集成了MDBT模型将域识别与置信状态追踪进行结合;在系统策略方面平台支持DQN,REINFORCE\PPO以及自模仿等;自然语言生成领域则使用了SC-LSTM方法。在词级策略上使用了Budzianowski等人提出的基准;在用户策略上ConvLab提供了基于agenda的方法和基于数据驱动(例如HUS等)的方法,模型在对话行为级别进行并可与NLU等模块协同构架出完整的用户模拟器;最后再端到端模型上则包含了Mem2Seq,Sequicity,并使得Sequicity实现了对于多域的支持。目前ConvLab主要支持MultiWOZ和Movie两个不同复杂度的数据域。其中MultiWOZ的主要任务是帮助旅客,其中引入了包含景点介绍和酒店预订等不同方面的内容。MultiWOZ中主要包含了7个子领域的问题:景点、医院、酒店、警察、餐厅、出租车、火车等方面的内容。其中包含了10438个标注对话。对于单领域和多领域的对话轮次平均为8.93和15.93轮。ConvLab对于用户对话行为进行了额外的标注、并为对话系统元件和用户模拟器提供了预训练基准模型、以及基于此数据训练的端到端的自然对话模型。Movie则来自于微软对话挑战赛,主要集中于电影票预订场景,包含了2890个标注对话,评论为7.5轮,同时还提供了针对主体和用户模拟器的一系列完整的参考模型。研究人员表示在未来还会加入Taxi和Restaurant等领域的任务不断丰富平台支持的领域。
-
中马研究院正式挂牌成立2016-01-07 3812
-
第一款完整的端到端LTE家庭基站设计2010-03-18 1327
-
Qualcomm宣布推出首款端到端802.11ax Wi2017-02-15 650
-
Skype提供端到端加密“私人对话”功能 让你对话更安全2018-01-12 5721
-
捷通华声与清华海峡研究院联合成立人工智能研究中心2018-06-11 4768
-
高通推出了业界首款端到端蓝牙智能耳机参考设计方案2018-10-23 1226
-
微软研究院研发出了新款原型VR控制器CapstanCrunch2019-11-22 745
-
一种基于端到端基于语音的对话代理2020-09-09 2097
-
中兴完成端到端的毫米波系统性能测试,助力运营商实现5G商用2020-09-16 2336
-
中国移动与清华大学在北京城里联合研究院2020-11-16 2490
-
智行者联合清华完成国内首套全栈式端到端自动驾驶系统的开放道路测试2024-04-22 1392
-
导远科技与清华大学无锡应用技术研究院达成合作2025-06-12 876
-
福州移动与华为联合推出国内首个端到端智能化体验经营系统2025-10-24 377
-
芯原与谷歌联合推出开源Coral NPU IP2025-11-13 408
全部0条评论

快来发表一下你的评论吧 !
