

如何使用Python机器学习解决验证码的资料说明
描述
写爬虫有一个绕不过去的问题就是验证码,现在验证码分类大概有4种:
图像类
滑动类
点击类
语音类
今天先来看看图像类,这类验证码大多是数字、字母的组合,国内也有使用汉字的。在这个基础上增加噪点、干扰线、变形、重叠、不同字体颜色等方法来增加识别难度。相应的,验证码识别大体可以分为下面几个步骤:
灰度处理
增加对比度(可选)
二值化
降噪
倾斜校正分割字符
建立训练库
识别
由于是实验性质的,文中用到的验证码均为程序生成而不是批量下载真实的网站验证码,这样做的好处就是可以有大量的知道明确结果的数据集。当需要真实环境下需要获取数据时,可以使用结合各个大码平台来建立数据集进行训练。
生成验证码这里我使用Claptcha这个库,当然Captcha这个库也是个不错的选择。
为了生成最简单的纯数字、无干扰的验证码,首先需要将claptcha.py的285行_drawLine做一些修改,我直接让这个函数返回None,然后开始生成验证码:

这里需要注意ubuntu的字体路径,也可以在网上下载其他字体使用。生成验证码如下:
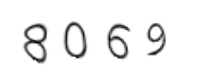
可以看出,验证码有形变。对于这类最简单的验证码,可以直接使用谷歌开源的tesserocr来识别。
首先安装:

然后开始识别:

可以看出,对于这种简单的验证码,基本什么都不做识别率就已经很高了。有兴趣的小伙伴可以用更多的数据来测试,这里我就不展开了。
接下来,在验证码背景添加噪点来看看:

生成验证码如下:
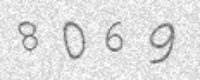
识别:
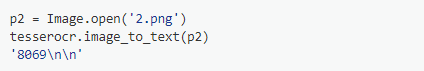
效果还可以。接下来生成一个字母数字组合的:

生成验证码如下:
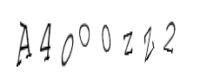
第3个为小写字母o,第4个为大写字母O,第5个为数字0,第6个为小写字母z,第7个为大写字母Z,最后一个是数字2。人眼已经跪了有木有!但现在一般验证码对大小写是不做严格区分的,看自动识别什么样吧:

人眼都跪的计算机当然也废了。但是,对于一些干扰小、形变不严重的,使用tesserocr还是十分简单方便的。然后将修改的claptcha.py的285行_drawLine还原,看添加干扰线的情况。
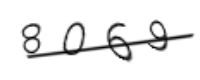

加了条干扰线就完全识别不出来了,那么有没有什么办法去除干扰线呢?
虽然图片看上去是黑白的,但还需要进行灰度处理,否则使用load()函数得到的是某个像素点的RGB元组而不是单一值了。处理如下:

处理后的图片如下:
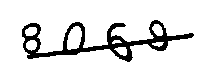
可以看出处理后图片锐化了很多,接下来尝试去除干扰线,常见的4邻域、8邻域算法。所谓的X邻域算法,可以参考手机九宫格输入法,按键5为要判断的像素点,4邻域就是判断上下左右,8邻域就是判断周围8个像素点。如果这4或8个点中255的个数大于某个阈值则判断这个点为噪音,阈值可以根据实际情况修改。

处理后的图片如下:
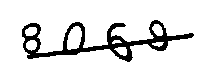
好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:
再进行识别得到了结果:

-
自动化测试如何绕过Cloudflare验证码?Python + Selenium 脚本实战指南!2025-08-15 1593
-
Java 中验证码的使用2023-09-25 2410
-
验证码到底在验证啥?聊一聊验证码是怎么为难我们人类的2023-08-12 4523
-
打码平台是如何高效的破解市面上各家验证码平台的各种形式验证码的?2022-11-01 3097
-
一文解析验证码与打码平台的攻防对抗2022-09-28 5287
-
爬虫实现目标网站验证码登陆2021-12-11 3052
-
验证码层出不穷?试试这个自动跳过验证码的工具2020-11-15 7117
-
以一个真实网站的验证码为例,实现了基于一下KNN的验证码识别2018-12-24 8751
-
如何利用机器学习破解验证码的源代码教程2018-04-30 6468
-
SQLyog_12.4.1_带验证码2018-04-12 1703
-
简单地描述了如何用机器学习绕过E-ZPass New York网站的验证码2018-01-22 7125
-
多样变换的手写验证码自动识别算法2017-12-20 954
-
无法验证邮箱,总是提示验证码错误,验证码明明是正确的。2017-05-12 10639
-
C#教程之中文验证码2016-04-20 663
全部0条评论

快来发表一下你的评论吧 !
