

OpenAl提出了一种适用于文本、图像和语音的稀疏Transformer
电子说
描述
OpenAl提出了一种适用于文本、图像和语音的稀疏Transformer,将先前基于注意力机制的算法处理序列的长度提高了三十倍。
对复杂高维度的数据分布进行估计一直是非监督学习领域的核心问题,特别是针对像文本、语音、图像等长程、相关性数据更使得这一领域充满了挑战。同时,对于复杂数据的建模也是非监督表示学习的关键所在。近年来,神经自回归模型在这一领域取得了一系列十分优秀进展,针对自然语言、原始音频和图像成功建模。这些方法将联合概率分布分解成了条件概率分布的乘积来解决。但由于数据中包含许多复杂、长程的依赖性并需要合适的表达模型架构来进行学习,使得对数据的条件概率分布建模依旧十分复杂。基于卷积神经网络的架构在这个方向取得了一系列进展,但需要一定的深度来保证足够的感受野。
为了解决这一问题,WaveNet引入了膨胀卷积(dilated conv)帮助网络在的对数数量层数下学习长程依赖性。于此同时Transformer由于可以利用一定的层数为任意的依赖性建模,在自然语言任务上显示出了强大的优势。由于每个自注意力层用于全局感受野使得网络可以将表示能力用于最有用的输入区域,对于生成多样性的数据具有更加灵活的特征。但这种方法在处理序列时需要面临随着序列长度平方增长的内存与算力。对于过长的序列,现有的计算机将无法处理和实现。为了解决这一问题,OpenAI的研究人员在最新的论文中为注意力矩阵引入了多种稀疏的分解方式,通过将完全注意力计算分解为多个更快的注意力操作,通过稀疏组合来进行稠密注意力操作,在不牺牲性能的情况下大幅降低了对于内存和算力的需求。
新提出了稀疏Transformer将先前Transforme的平方复杂度O(N^2)降低为O(NN^1/2),通过一些额外的改进使得自注意力机制可以直接用于长程的语音、文本和图像数据。原先的方法大多集中于一个特定的领域、并且很难为超过几千个元素长度的序列建模,而稀疏Transformer则可利用几百层的模型为上万个数据长度的序列建模,并在不同领域中实现了最优异的结果。
Deep Attention
在Transformer中,输入和输出的每一个元素都通过权重相连,利用注意力机制算法可以根据实际情况动态更新权重,使得Transformer具有更加灵活的特性。但在工程实践中,针对N维输出我们需要N*N的注意力矩阵来为每一层存储权重,这将消耗大量的内存,特别是针对音频和图像这种长序列的数据来说,内存分分钟就将被算法吃完。下表给出了针对不同数据所需要的内存大小和计算量。
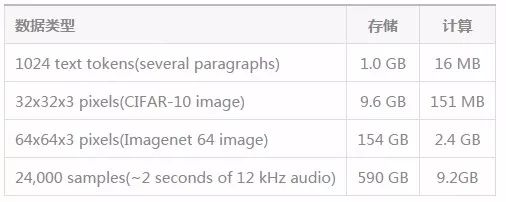
这一表格针对64层4heads的深度Transformer对于内存和计算的需求,而一般的显卡只有12-32G显存,显然对于长程的图像、语言数据是无能为力的。受到深度学习中减小内存的启发,研究人员们在注意力矩阵反向传播时引入了checkpoint的概念,这使得内存的消耗与网络层的数量解耦,让更深的网络训练成为可能。
稀疏注意力机制
解决了内存的问题并不意味着我们可以水到渠成地训练长程数据了。即使对于单个注意力矩阵来说对于长程数据的计算在实际中依然很难实现。为了处理这一问题,研究人员利用了稀疏注意力模式从输入数据中选出一小部分来计算输出,这一个输入子集相对于输入整体来说很小,使得最终对于每一个长程序列的计算结果变得可控。为了验证这种方法的有效性,研究人员对学习到的注意力模式进行了可视化,并在其中发现了很多具有可解释性的稀疏模式。下图中可以看到白色发光的像素被被注意力头所接受并用于预测下一个位置的输出。当输入集中于很小一个子集并加入较高的正则化时,这一层将会变得系数化。下图中可以看到不同的层学会了不同的稀疏注意力机制,左图是19层基于每一行来进行预测,而右图为20层基于每一列来进行预测,将完全注意力机制进行了有效的分解。
不同层的注意力具有不同的侧重。有的层只对特定的空间位置产生注意力只注重特定的位置,而有的层注意力则高度依赖于输入的数据,具有全局的动态注意力。
为了保留模型对于这些模式的学习能力,研究人员将注意力矩阵进行了二维分解,以便网络可以通过两步稀疏注意力实现对于所有位置的审视。
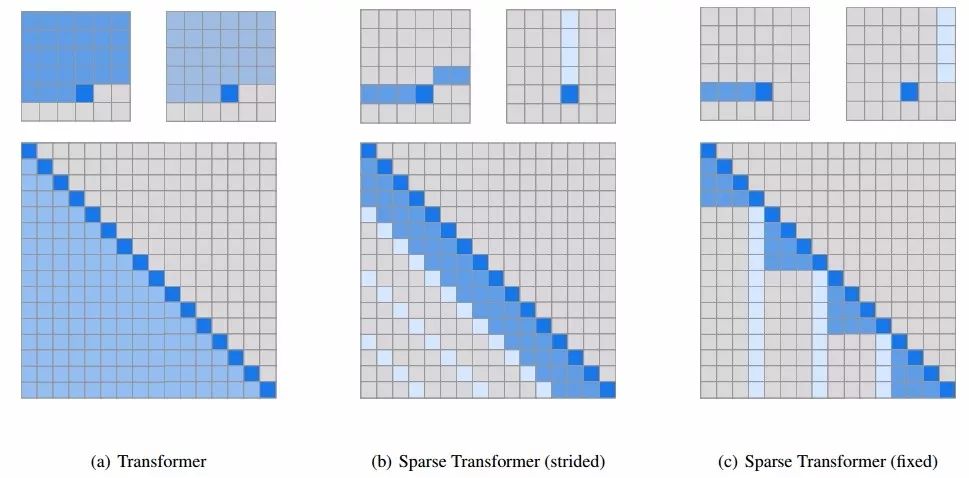
上图中间是第一种步进注意力的版本,可以粗略的理解为每一个位置需要注意它所在的行和列;另一种固定注意力的方式则尝试着从固定的列和元素中进行处理,这种方式对于非二维结构的数据有着很好的效果。
实验结果
在CIFAR-10,Enwik8和Imagenet64上研究人员比较了新提出方法的密度建模性能,可以看到这种方法对于各个数据集建模都有着优秀的能力。
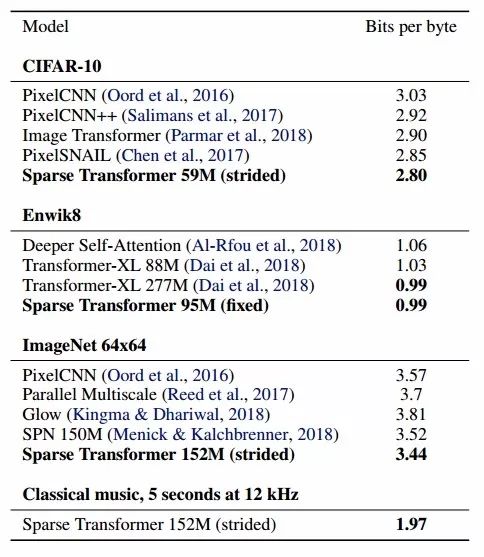
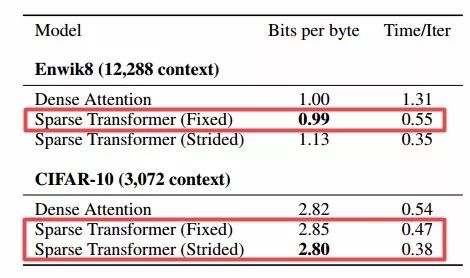
同时研究人员还发现稀疏注意力比完全注意力的损失更小、更快。
由于transformer对全局结构具有一定的理解,可以对缺失的图像进行补全。
同时利用极大似然估计从模型中进行采样生成了一系列图像:
稀疏Transformer对于原始的音频输入依然能进行有效的处理,实验中可以生成65000个元素的声音序列(近5s钟的音频)。只需要稍微改变模型的位置嵌入就可以适应不同形式的输入。
在未来研究人员还将继续针对长程序列研究高效的建模方式,并探索不同类型的稀疏性结合。虽然这种方法取得了很好的效果,但是对于高分辨的图像甚至视频依然无法有效处理。研究人员计划在未来引入高维数据建模方式和稀疏注意力共同解决这一挑战。
-
一种适用于动态场景的多层次地图构建算法2023-08-28 1636
-
一种适用于空间观测任务的实时多目标识别算法分享2021-12-21 1774
-
一种适用于嵌入式系统的模块动态加载技术2021-12-20 1413
-
分享一种不错的无线语音传输系统设计方案2021-05-31 1136
-
一种能同时适用于ISM两频段的功率分配器设计2019-07-02 2354
-
适用于稀疏多径信道的稀疏自适应常模盲均衡算法2018-01-29 978
-
基于岭回归的稀疏编码文本图像复原方法2017-11-28 968
-
一种Spark高光谱遥感图像稀疏表分类并行化方法2017-11-02 1416
-
一种适用于医学领域的频率可调滤波器2017-01-07 831
-
一种适用于多规格定子绕组制作的绝缘内圈2017-01-02 719
-
一种适用于锂电池的电流监测电路设计2014-09-09 3084
-
一种适用于可视电话的快速运动估计算法2010-03-01 741
-
一种有效的文本图像二值化方法2009-06-11 855
全部0条评论

快来发表一下你的评论吧 !
