

富士通宣布打破了ImageNet的训练速度记录——在74.7秒内达到75%的准确率
描述
近期,来自富士通(Fujitsu)的研究员们宣布他们打破了ImageNet的训练速度记录——在74.7秒内达到75%的准确率。这比去年11月由索尼(Sony)创下的前纪录快了47秒。
团队取得这样的纪录,得益于日本东京大学(University of Tokyo)的 AI Bridging Cloud Infrastructure(ABCI)系统上的2,048块NVIDIA Tesla V100 GPU,以及MXNet深度学习架构。
ABCI系统是日本最快的超级计算机,在世界超级计算机榜单中也名列前10。该系统由超过4,300块NVLink互联的NVIDIA V100 GPU提供算力。Sony此前保持的纪录也是借助此系统实现的。
富士通(Fujitsu)在一篇文章中介绍:“基于此技术,富士通实验室(Fujitsu Laboratories)深耕HPC发展,公司现已开发出了新的技术,能够在保证训练准确率的同时拓展每块GPU的计算量。”
为了对使用大批量mini-batch训练深度神经网络(DNN)时发生的验证准确性进行补偿,团队“使用了相关技术,在不影响准确率的同时,增大了小批量的体量。”
研究人员介绍说:“众所周知,具有数据并行性的分布式深度学习是加速集群训练的有效方法。通过这种方法,在集群上运行的所有步骤都具有相同的DNN模型和权重。”
研究人员们同时也借助了Tensor核心的混合精度。

该DNN架构经过优化,基于ImageNet在74.7秒的时间内完成 ResNet-50训练,而且验证准确率高达75.08%。
团队还能够使用高达81,920个的大批量mini-batch,同时保持75.08%的准确率(如上表中第3个数据点所示)。
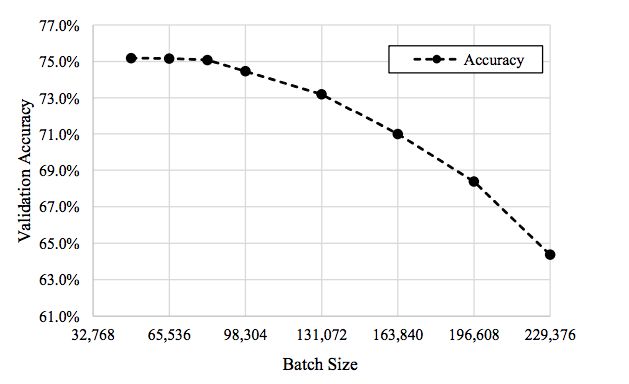
为实现这一里程碑式的成果,大量的NVIDIA技术被应用其中,其中就包括层级对应的适应率缩放(Layer-wise Adaptive Rate Scaling)。
该项工作目前已在ArXiv 和富士通博客上发表。
-
NIUSB6009 采集准确率的问题?2024-09-23 7650
-
怎样记录10秒内的数据2012-04-20 2819
-
锤子手机发布会罗永浩提到的富士通2014-05-21 3230
-
基于RBM实现手写数字识别高准确率2018-12-28 3001
-
富士通FRAM存储器在智能电表中有什么应用?2021-07-11 2305
-
富士通正式宣布与联想合作PC业务2016-10-29 810
-
交大教授训练机器通过面部识别罪犯 准确率达到86%以上2016-12-01 1361
-
联想合并富士通之后富士通将会专注于企业IT服务2016-12-15 836
-
人脸识别技术可以达到99.84%的准确率,实现了飞速的发展2018-09-07 10817
-
索尼发布新的方法,在ImageNet数据集上224秒内成功训练了ResNet-502018-11-16 10613
-
富士通实验室在74.7秒内完成了ImageNet上训练ResNet-50网络2019-04-08 5585
-
人工智能鉴定大师“包小鉴”准确率达到95%以上2019-08-16 7582
-
AI垃圾分类的准确率和召回率达到99%2020-06-16 4502
-
目前的二维码智能门禁识别准确率已高达到100%2020-09-16 2080
-
ai人工智能回答准确率高吗2024-10-17 12300
全部0条评论

快来发表一下你的评论吧 !
