

XGBoost号称“比赛夺冠的必备大杀器”,横扫机器学习竞赛罕逢敌手
电子说
描述
XGBoost号称“比赛夺冠的必备大杀器”,横扫机器学习竞赛罕逢敌手,堪称机器学习算法中的新女王!
在涉及非结构化数据(图像、文本等)的预测问题中,人工神经网络显著优于所有其他算法或框架。但当涉及到中小型结构/表格数据时,基于决策树的算法现在被认为是最佳方法。而基于决策树算法中最惊艳的,非XGBoost莫属了。
打过Kaggle、天池、DataCastle、Kesci等国内外数据竞赛平台之后,一定对XGBoost的威力印象深刻。XGBoost号称“比赛夺冠的必备大杀器”,横扫机器学习竞赛罕逢敌手。最近甚至有一位大数据/机器学习主管被XGBoost在项目中的表现惊艳到,盛赞其为“机器学习算法中的新女王”!
XGBoost最初由陈天奇开发。陈天奇是华盛顿大学计算机系博士生,研究方向为大规模机器学习。他曾获得KDD CUP 2012 Track 1第一名,并开发了SVDFeature,XGBoost,cxxnet等著名机器学习工具,是Distributed (Deep) Machine Learning Common的发起人之一。
XGBoost实现了高效、跨平台、分布式gradient boosting (GBDT, GBRT or GBM) 算法的一个库,可以下载安装并应用于C++,Python,R,Julia,Java,Scala,Hadoop等。目前Github上超过15700星、6500个fork。
项目主页:
https://XGBoost.ai/
XGBoost是什么
XGBoost全称:eXtreme Gradient Boosting,是一种基于决策树的集成机器学习算法,使用梯度上升框架,适用于分类和回归问题。优点是速度快、效果好、能处理大规模数据、支持多种语言、支持自定义损失函数等,不足之处是因为仅仅推出了不足5年时间,需要进一步的实践检验。
XGBoost选用了CART树,数学公式表达XGBoost模型如下:
K是树的数量,F表示所有可能的CART树,f表示一棵具体的CART树。这个模型由K棵CART树组成。
模型的目标函数,如下所示:
XGBoost具有以下几个特点:
灵活性:支持回归、分类、排名和用户定义函数
跨平台:适用于Windows、Linux、macOS,以及多个云平台
多语言:支持C++, Python, R, Java, Scala, Julia等
效果好:赢得许多数据科学和机器学习挑战。用于多家公司的生产
云端分布式:支持多台计算机上的分布式训练,包括AWS、GCE、Azure和Yarn集群。可以与Flink、Spark和其他云数据流系统集成
下图显示了基于树的算法的发展历程:
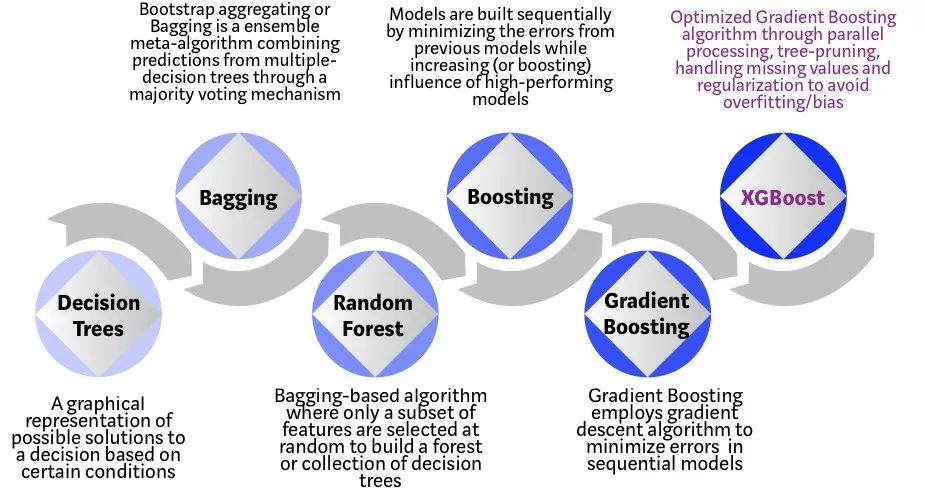
决策树:由一个决策图和可能的结果(包括资源成本和风险)组成, 用来创建到达目标的规划。
Bagging:是一种集合元算法,通过多数投票机制将来自多决策树的预测结合起来,也就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法
随机森林:基于Bagging算法。随机选择一个包含多种特性的子集来构建一个森林,或者决策树的集合
Boosting:通过最小化先前模型的误差,同时增加高性能模型的影响,顺序构建模型
梯度上升:对于似然函数,要求最大值,叫做梯度上升
XGBoost:极端梯度上升,XGBoost是一个优化的分布式梯度上升库,旨在实现高效,灵活和跨平台
为什么XGBoost能横扫机器学习竞赛平台?
下图是XGBoost与其它gradient boosting和bagged decision trees实现的效果比较,可以看出它比R, Python,Spark,H2O的基准配置都快。
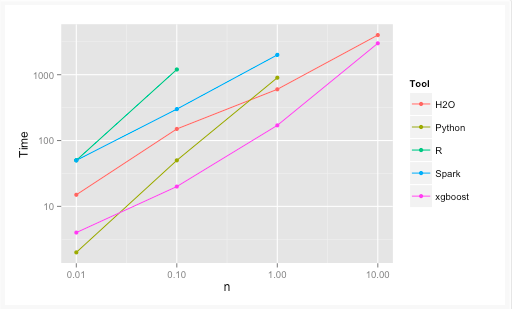
XGBoost和Gradient Boosting Machines(GBMs)都是集合树方法,使用梯度下降架构来提升弱学习者(通常是CART)。而XGBoost通过系统优化和算法增强改进了基础GBM框架,在系统优化和机器学习原理方面都进行了深入的拓展。
系统优化:
并行计算:
由于用于构建base learners的循环的可互换性,XGBoost可以使用并行计算实现来处理顺序树构建过程。
外部循环枚举树的叶节点,第二个内部循环来计算特征,这个对算力要求更高一些。这种循环嵌套限制了并行化,因为只要内部循环没有完成,外部循环就无法启动。
因此,为了改善运行时,就可以让两个循环在内部交换循环的顺序。此开关通过抵消计算中的所有并行化开销来提高算法性能。
Tree Pruning:
GBM框架内树分裂的停止标准本质上是贪婪的,取决于分裂点的负损失标准。XGBoost首先使用'max_depth'参数而不是标准,然后开始向后修剪树。这种“深度优先”方法显著的提高了计算性能。
硬件优化:
该算法旨在有效利用硬件资源。这是通过在每个线程中分配内部缓冲区来存储梯度统计信息来实现缓存感知来实现的。诸如“核外”计算等进一步增强功能可优化可用磁盘空间,同时处理不适合内存的大数据帧。
算法增强:
正则化:
它通过LASSO(L1)和Ridge(L2)正则化来惩罚更复杂的模型,以防止过拟合。
稀疏意识:
XGBoost根据训练损失自动“学习”最佳缺失值并更有效地处理数据中不同类型的稀疏模式。
加权分位数草图:
XGBoost采用分布式加权分位数草图算法,有效地找到加权数据集中的最优分裂点。
交叉验证:
该算法每次迭代时都带有内置的交叉验证方法,无需显式编程此搜索,并可以指定单次运行所需的增强迭代的确切数量。
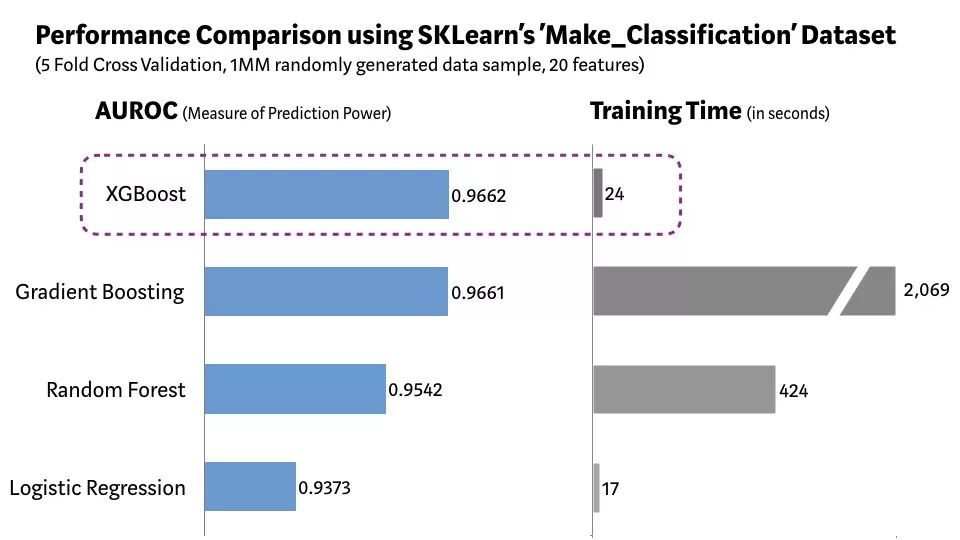
为了测试XGBoost到底有多快,可以通过Scikit-learn的'Make_Classification'数据包,创建一个包含20个特征(2个信息和2个冗余)的100万个数据点的随机样本。
下图为逻辑回归,随机森林,标准梯度提升和XGBoost效率对比:
-
xgboost超参数调优技巧 xgboost在图像分类中的应用2025-01-31 2728
-
xgboost在图像分类中的应用2025-01-19 1928
-
在几个AWS实例上运行的XGBoost和LightGBM的性能比较2022-10-24 2450
-
如何设计一台可供8名选手参加比赛的智力竞赛抢答器?2021-09-29 1131
-
如何通过XGBoost解释机器学习2020-10-12 2479
-
竞赛机器人制作技术(电路设计、编程方法、算法解析)2019-12-25 5540
-
竞赛机器人制作技术PDF电子书免费下载2019-12-18 1738
-
科大讯刷新记录并飞夺冠比赛2019-07-12 3565
-
面试中出现有关Xgboost总结2019-03-20 4797
-
通过学习PPT地址和xgboost导读和实战地址来对xgboost原理和应用分析2018-01-02 7178
-
“迎春杯”足球比赛精彩落幕 园区派出所队夺冠2016-03-10 2268
-
嵌入式比赛要用什么必备知识2013-03-14 2634
全部0条评论

快来发表一下你的评论吧 !
