

详细梳理聊天机器人的现状及技术,并讨论了未来可能的发展方向
电子说
描述
作者:邵浩
作为人工智能时代的入口级产品,近年来,聊天机器人受到了大量的关注,也得到了快速的发展。但随着 2018 年 Facebook 关闭其虚拟助手 M,亚马逊 Echo 也被爆出侵犯用户隐私的问题,再加上聊天机器人实际使用效果远低于大众预期,整个行业也逐步走向低迷。聊天机器人的困境到底在哪儿?在如今的技术条件和市场环境下,聊天机器人厂家如何进行突围?使用新技术,开辟新赛道,是否能解决问题?本文将详细梳理聊天机器人的现状及技术,指出其存在的问题,并讨论了未来可能的发展方向。本文作者为狗尾草人工智能研究院院长、日本国立九州大学工学博士邵浩。
困境
一、聊天机器人太傻了
我是一个聊天机器人的从业者,办公桌上和家里有各式各样的聊天机器人产品。和大多数用户的体验一样,对于一个刚刚到手的产品,最开始的感觉是新鲜兴奋,但当体验完功能之后,剩下的就是失望和无奈。然后,很可能就将其放在角落里再也不会打开,或者仅仅作为一个音箱,来播放音乐。
这就跟聊天机器人厂商的初衷背道而驰了。一边是厂商希望用户长久留存在产品上,一边是用户对产品的日均使用时间快速下降。那么为什么会出现这种情况?为什么大多数用户对于聊天机器人的满意度很低?
从人类的天性中,可以一窥端倪。天主教教义对人类的恶性分为七种。举例来说,人类是懒惰的,总是希望以最少的代价获取最大的利益。而由于技术的限制,和聊天机器人的对话经常会使得沟通成本增加。比如,语音识别率在实际场景中不可能达到 100%,也就造成了在嘈杂环境中唤醒聊天机器人,许多时候是一个很不舒服的体验。相比而言,人类的耳朵对于「鸡尾酒会效应」却游刃有余。又比如,想让聊天机器人完成一项功能(订机票、查天气或播放一首特定风格的音乐),有时候必须通过非常明确的语言,进行多次沟通。相比而言,古代皇帝想做一件事情的时候,甚至不需要用到语言,只需一个眼神,太监就马上能意会到皇帝的目的。这里提到的还只是纯交互部分的问题,如果再出现网络延迟、敏感词和敏感话题、甚至还有一些稀奇古怪的 bug,让聊天机器人答非所问,就会让人更加不满。
作为从业人员,我在使用这些产品的时候还是很宽容的,由于知道聊天机器人的软肋,就会尽可能的跟聊天机器人心平气和的对话。一次不行,我再试一次,这个指令不管用,我再换一种问法。但对于普通用户,可不会买账。我们看下如图 1 这个用户,冷不丁的半夜被聊天机器人的怪笑吓个半死。英文翻译过来的意思就是「躺在床上正要睡着了,突然某某某音箱中的虚拟助手向我发出很大声让人毛骨悚然的笑声... 今晚我要被杀了」。这个时候,如果是我的话,除了把它从楼上扔下去摔个粉碎之外,好像也没有什么平复心情的办法了。
图 1. 用户对聊天机器人的吐槽
再举一个例子,在分析用户使用数据的时候可以发现,排名靠前的功能主要有闲聊、问天气、播放音乐等。刚接触这个行业的时候,我曾认为,既然是被高频触发的功能,就证明这些是用户的「刚需」。只要对刚需功能做好优化,用户留存度和满意度自然会大幅提升。后来才慢慢体会到,有些时候,并不是用户真的最喜欢问天气和播放音乐,而是其他的功能体验感实在是差强人意,比较成熟的也就剩下天气和音乐了。这就牵扯到「七宗罪」中的又一个「罪」:贪婪。用户总是想得到更多,所以在刚拿到聊天机器人产品的时候,自然而然的会不断试探其边界,所以交互的内容也会天马行空,五花八门。但如果用户得到的都是负面反馈,随着期望的降低,问答范围也会缩小到一些成熟和稳定的功能上。就好像是新婚之夜,满怀期待掀开新娘的面纱,却发现等待着的是如花。
二、为什么要做聊天机器人
既然聊天机器人效果都做的不好,那为什么还有大量的公司一窝蜂涌入到这个市场?头部厂商不惜重金做补贴,甚至能做到人民币两位数的售价。尤其像儿童教育聊天机器人,虽然已成为血海市场,仍然还有很多公司前赴后继进入到这个赛道。
这还要从我们所处的时代说起。我是 80 后,很幸运经历了近 40 年技术爆发的 4 个时代,分别是 PC 时代、互联网时代、移动互联网时代和人工智能时代。而我们现在所处的人工智能时代,也正是 AI技术发展历史上的第三次浪潮。
每一个时代都有其对应的入口级产品。在 80 到 90 年代,个人电脑是最主要的入口,其特点是「运算力改变生活」,个人电脑和 Windows 操作系统,成就了 IBM 和微软两个硬件和软件的巨头。我至今还记得当时用一台 486 电脑和 14 寸的球面显示器,玩仙剑奇侠传的场景。而在随后到来的互联网时代,核心特点是「连接颠覆一切」,人们可以通过网络随时随地进行信息搜索和信息交互,同时也造就了谷歌这样一个伟大的公司。第三个时代是移动互联网时代,移动技术带来了两大变革,一是数据利用效率的提升,导致服务发生了变化,人们可以随时随地享受例如叫车、点餐等即时服务,二是交互方式的改变,智能手机(主要是触屏手机)成为了入口级设备,这个时代中最具有代表性的公司就是苹果,iPhone 也成为了颠覆性的产品。
当人们跨越到人工智能时代,微软又提出对话即平台(Conversation As A Platform)的理念,并称之为一种交互方式的「回归」。之所以称之为「回归」,是因为从远古时代起,语言是人类最自然的交互方式。人们通过语言来打招呼、八卦、协同狩猎,也就拉近了群体中人与人之间的距离。以色列历史学家尤瓦尔•赫拉利的《人类简史》甚至把「八卦」提到了非常重要的位置,是人与动物、人与其他史前人类的关键区别。以前由于技术的限制,人们不得不通过键盘和鼠标与机器进行「对话」,而现在我们具备了「对话即平台」的条件,可以很好的实现这种最自然的交互方式,完成各种服务。因此,在人工智能时代,语音交互产品也自然而然成为了入口级产品,而聊天机器人就是一个最典型的体现。
因此,为了抢占这一「入口」,无论是技术巨头还是创业大军,都加入到了本就不宽的赛道中来,就如「千树万树梨花开」一样,出现了大量的聊天机器人产品。同时在 B 端和 G 端市场,为了显得自己的高大上,很多大企业和政府机构也都纷纷推出自己的智能问答系统。然而,好奇害死猫,「入口」害死人。现在的聊天机器人已经变成了血海市场,哀鸿遍野。技术的低门槛,产品的同质化,再加上头部厂商的补贴策略,大公司长期亏损,中小型公司的生存更为艰难。尤其是 18 年开始的「资本寒冬」,很多的聊天机器人公司要么关门,要么转型,这个我们暂时按下不表,后面还有更多讨论。
三、聊天机器人是什么
聊天机器人从字面上来讲,就是会聊天的机器人。但「会聊天」涵盖的范围太广了。人们总是希望给事物打上标签,给出定义。因此,对于聊天机器人而言,我们给出几类角度不同的分类。
首先,从用途和使用场景上看,聊天机器人可以简单分为功能类和娱乐类。所谓功能类,一般是为了解决某个特定的问题,比如说个人助理、音乐播放、儿童故事、网上购物等。而娱乐类,大多是为了陪伴用户闲聊。微软小娜(Cortana)和微软小冰,分别是功能类和娱乐类的典型代表。
其次,从生态系统上看,聊天机器人可以分为产品、框架和平台三类。我们在市场上所看到的,以及日常所使用的都称之为「产品」,包括纯软件形态和软硬件结合的品类,例如微软小冰,亚马逊 Echo、iPhone 上的 Siri,公子小白、小米音箱等。除此之外,为了加速实际产品的研发,很多公司专门对外提供聊天机器人框架(Framework),以 SDK 或者 SAAS 服务的形态,供需求方来构建特定场景和领域的聊天机器人。典型代表包括支持 Echo 的 Amazon Alexa,微软的 Luis with Bot 等。另外,一些纯软件形态的聊天机器人,需要承载其应用的「平台」(Platform),比如说微信、Facebook 等。这样就构成了整个聊天机器人的生态体系。
最后,从交互方式上看,聊天机器人可以分为主动交互型和被动交互型两种,其中,被动交互型又包括闲聊型、任务型和问答型三类。我们接触到的绝大多数产品属于被动交互,即由用户发起对话,机器理解对话并作出相应的回应。主动交互可以更好的体现机器人和用户之间的对等关系,即由机器人主动发起,通过共享或推荐用户感兴趣的热点信息,和人类进行互动,但目前更多的是作为对传统交互方式的一种补充,并未得到大规模广泛应用。从被动交互的三种类型来看,闲聊型主要是进行客观话题讨论,或者用户对聊天机器人进行一些情感表达,微软小冰就具有很强的闲聊属性。而任务型是为了满足一个特定的任务或者目标,比如说利用 Siri 可以设定闹钟、预定餐馆等。对于问答型聊天机器人,需要解决用户对于事实型(Factoid)问答(如 what、which、who、where 和 when)问题的回复,以及非事实型问答(如 how 和 why)的回复。
用户在和聊天机器人交互的过程中,会夹杂各式各样的意图。举一个简单的例子,以下是一段对话:
```
Q: 你知道阿楠的电话号码么?
A: 知道
Q: 那你能告诉我他的号码么?
A: 可以
```
我们可以看到,这其实是一段无意义的废话。用户的意图是想要阿楠的电话号码(任务型对话),而聊天机器人的回复完全属于闲聊型对话。
四、理想和现实
从七十年前的原子弹,到五十年前的粒子对撞机,再到二十年前的基因编辑技术,技术的在近百年来有了突飞猛进的发展。而在人工智能如此火热的今天,为什么聊天机器人就做不好?这就需要先简单聊一下人工智能技术的现状。
文因互联的鲍捷老师曾给出一个人工智能三次热潮的曲线图(图 2),人工智能至今经历了三次大的热潮。而这一轮人工智能热潮,是伴随着大数据和深度学习的兴起。深度学习技术最早期的研究起始于上世纪六十年代的感知器,而直到最近的十年,随着软件和硬件的成熟,深度学习才取得了爆发式的进步,在多个领域例如图像识别,语音识别等都突破了人类最好的成绩。火热的人工智能带来了很多机会,也带来了很多问题。资本的大量涌入,使得市场上涌现了一大批 AI 初创公司,同时媒体的大肆宣扬,也使得大众的胃口和期望被吊得越来越高。普通的技术成果已无法吸引读者的关注,很多媒体就开始用夸张的标题和内容来吸引眼球,比如说「人类要被机器人取代」「重磅!机器开始威胁人类」等等。更不用说像 Sophia 这种伪 AI 的出现,使得人们觉得 Sophia 就是人工智能应该有的样子。而且,就好比 AlphaGo 并不能给人类端茶倒水一样,在一个特定领域的优秀表现,并不能代表 AI 技术无所不能。又例如,谷歌在 2018 年开发者大会上演示了一个预约理发店的聊天机器人,人们在大呼惊艳的同时,自然而然的觉得人工智能技术应该可以上天入地,做到任何事情,甚至取代人类。
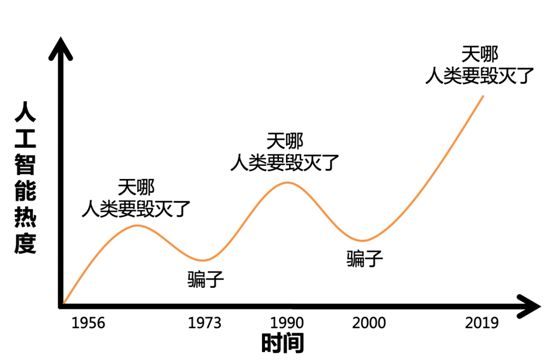
图 2. 人工智能三次热潮
这是技术从业者的悲剧。罗马从来都不是一天能够建成的,技术的突破也必然会经历一定时间的积累。很多时候,本来应该稳步推进的技术,却在落地之时,面临投资者和用户被吊得足够高的胃口,不得不去做一些虚假宣传。比如说:「我的产品可以完美解决鸡尾酒会效应」「订咖啡、购物、订票,我们的产品都可以帮你做到」等等。然后,就没有然后了。
因此,人工智能除了经典的三大主义(符号主义、连接主义、行为主义)之外,现在又多了第四个分类,叫做媒体主义。
回到深度学习技术的发展上来,AlphaGo 都能打败人类最顶尖的棋手,拥有 15 亿参数的 GPT-2 模型已经可以做到文本续写,为什么深度学习却没有真正解决聊天机器人的自然交互?且不说训练成本的问题,目前技术能够做到比较好的基本上都是单轮交互(也就是一问一答),在多轮交互上,除了在某些特定场景可以表现较好(如 Google 开发者大会上的理发店预约场景),在开放式聊天中往往会惨不忍睹(这一点我们下一节会详细讨论)。而单轮交互,在技术上最简单的解决方案,是写一大堆的句子,并使用基本的检索方法和规则来选取已经写好的答案来进行回复,甚至可以完全不用深度学习方法。所以才会出现仅通过堆语料就能创造出一个表现尚佳的聊天机器人。
作为从业者,从技术的角度上来讲,聊天机器人的表现其实已经非常不错了。甚至在某一些特定场景下足以以假乱真了。我们经常会被一些广告营销电话骚扰,以前还都是真人在和我们沟通,而现在出现了大量的聊天机器人,他们不知疲倦,可以 24 小时*7 天不间断工作,通过电话语音,甚至很多情况下我们都无法判断对方是不是机器人。这是因为,在特定场景下,对话可以跳转的状态一般都是有限的,可能产生的话题分支,比起围棋的可能性要少很多,因此,即便是穷举所有的可能性,也不是不可做到的事情。如果提前设置好对话策略,加上语音合成技术,完全可以以假乱真。
我们都知道,图灵测试由英国数学家阿兰•图灵于 1950 年发明,是指测试者在与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后,如果有超过 30% 的测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。2014 年 6 月,一个伪装成乌克兰 13 岁男孩的机器人尤金•古特曼,顺利的通过了图灵测试。其实,通过这个测试也用了一些小技巧,比如说「13 岁男孩」,可以装作自己的思考能力不够成熟,同时,来自「乌克兰」可以有效掩盖其英文水平的不足。但严格意义上来说,通过图灵测试并不能代表机器已经具有自然对话的能力。曾看到过一篇关于图灵生平的文章,提到图灵在 1952 年被判犯有同性恋行为,并被迫接受化学阉割,两年后图灵自杀身亡。而图灵测试,其实就是反映了在上世纪 50 年代的英国,每一位同性恋男性必须通过的日常测试:你是否能伪装成一个异性恋者?根据图灵的看法,未来的计算机就像当时的同性恋者,计算机有没有意识并不重要,重要的是人类会怎么想。
即便是图灵测试,也可以看做是一个特定的「闭域」,在这个闭域中,聊天的状态是预先可以设计的,有很多的策略可以让对话在这个特定的闭域顺畅的进行下去。而很多聊天机器人厂商给自己挖的坑,是要做「开域」(也就是通用域)的聊天。在现有的技术条件下,这就相当于给自己的产品判了死刑。因为做通用域聊天,就等同于想要模拟人类真实的对话,这在目前是不可能完成的任务。具体缘由我们在下一节详细阐述。
五、人是如何聊天的
在人类的聊天中,一句话所包含的文字,所反应的内容仅仅是冰山一角。比如说「今天天气不错」,在早晨拥挤的电梯中和同事说,在秋游的过程中和驴友说,走在大街上的男女朋友之间说,在倾盆大雨中对同伴说,很可能代表完全不同的意思。在人类对话中需要考虑到的因素包括:说话者和听者的静态世界观、动态情绪、两者的关系,以及上下文和所处环境等,如图 3。
图 3. 人类聊天中的要素
静态世界观:人类在成长过程中会建立起自己的世界观,一般跟跟经历和记忆有关。比如说一个素食主义者可能会非常厌恶谈及红烧肉的话题,又比如提及粉笔划玻璃,会让一部分人很不舒服,但对另一部分人却没任何影响。同时,对话的过程中也会触发一些相关联想,比如提到情人节,会想到玫瑰花和巧克力,提到下雨天就会想到雨伞等。鲁迅在《而已集•小杂感》也曾写道「一见到短袖子,立刻想到白臂膊,立刻想到全裸体,(略),中国人的想像惟在这一层能够如此飞跃」。
动态情绪:表现在交互过程中的表情、动作、语气等。因为人类的交互过程通常需要接收多方面信息源,在不同语气、不同表情,所表达的含义有可能完全不同。比如说「我恨你」,在恋人间轻柔的对话中很可能代表「我真的很喜欢你」。
说话者和听者的关系:对话双方是敌人、家人、朋友还是恋人,话语中所表达的意思就会有所区别。就比如刚刚的例子「今天天气不错」,在分手多年的恋人见面时说,很可能就代表「你现在过得好么」。
上下文:相同的词语和句子,在不同的上下文中也会有不同的含义。「我洗头去了」用于微信和 QQ 聊天中,很可能就代表「我不想聊了,再见」的意思。
所处环境:在不同场景下,相同话语会触发不同的反馈。如果在厕所和人打招呼用「吃过了么」就会显得非常尴尬了。
而且,以上这些都不是独立因素,整合起来,才能真正反映一句话或者一个词所蕴含的意思。这就是人类语言的奇妙之处。同时,人类在交互过程中,并不是等对方说完一句话才进行信息处理,而是随着说出的每一个字,不断的进行脑补,在对方说完之前就很可能了解到其所有的信息。再进一步,人类有很强的纠错功能,在进行多轮交互的时候,能够根据对方的反馈,修正自己的理解,达到双方的信息同步。在回过头看开放域的聊天机器人,寄希望于从一句话的文本理解其含义,这本身就是很不靠谱的一件事情。
目前市场上大部分的聊天机器人,还仅是单通道的交互(语音或文本),离人类多模态交互的能力还相差甚远。哪怕仅仅是语音识别,在不同的噪音条件下也会产生不同的错误率,对于文本的理解就更加雪上加霜了。
六、技术及发展进度
在这一节,我们讨论下现有聊天机器人所涉及的技术,但不会牵扯到技术细节。
机器学习和深度学习:机器学习技术属于基础技术,比如说分类算法可以用于做用户的意图分类和情感分类;语言模型可以用于筛选语音识别后的句子是否通顺;聚类算法可以用于做用户的行为习惯分析等等。随着数据量越来越多,可以发挥深度学习的优势,更进一步提升聊天机器人的基础技术能力。
自然语言处理:是聊天机器人语义交互层面的核心技术。比如说检索技术可以选取语料库中最合适的回复,命名实体识别可以找出句子中的关键信息,如「播放李荣浩的李白」中,李白是指一首歌名。主体识别可以用于判断句子的主语,例如「我给你唱歌」和「给我唱歌」的主语是不同的。此外,还有句型判断、实体链接、词性标注、依存分析等各项技术,综合运用于对用户句子的解析。
数据库技术:通过数据库技术,我们可以在预先存储好的大规模语料库中,快速检索相近的句子,也可以对海量的用户交互数据进行存储并进一步分析。
知识图谱技术:是聊天机器人实现认知交互的关键技术之一,可以帮助聊天机器人进行记忆、联想和推理。关于知识图谱,我们放到本文的下半部分专门讨论。
声学技术:包括语音识别、语音合成、声纹迁移、声纹识别以及歌声合成等,为聊天机器人提供了更加丰富的表现力。声学技术也牵扯到和芯片、硬件(例如麦克风阵列)的配合。
计算机视觉技术:通过计算机视觉技术,可以进行人脸识别、情绪识别,并可以进一步配合语音、语义技术对用户语句进行深度分析。
其他技术:很多聊天机器人产品具备硬件形态,包括虚拟形象,因此也需要芯片技术、硬件、全息技术、美术和设计的支持。
聊天机器人一定是一个技术整合的产物,在一个有很多串行模块的系统中,有个很重要的问题是错误传递。比如说有 5 个串行模块,每个模块的性能都是 95%,最终的结果却只有 77%。所以,在设计一个聊天机器人架构的时候也需要尽可能避免模块的串行化。同时,对于多轮交互架构,也需要有更加成熟的设计。
Gartner 给出的最新技术成熟度的图,也反映了不同技术的发展现状。网上流传的一句话说到,当某个领域的代表性人物获得了图灵奖,也就代表了这个领域辉煌时代的结束。2019 年 3 月 27 日,ACM 宣布,深度学习的三位创造者 Yoshua Bengio,Yann LeCun,以及 Geoffrey Hinton 共同获得了 2019 年的图灵奖。在曲线中,我们也看到深度学习处于曲线的最高峰,并且即将处于下降的趋势,也在一方面印证了随着大数据红利的消失,以深度学习为代表的感知智能也触碰到了天花板。
图 4. Gartner2018 技术成熟度曲线
破局
一、产业现状
随着人工智能的第三次浪潮,涌现了一大批聊天机器人公司,其中有平台型公司,也有产品型公司。从业务角度上来看,主要分为三类:
2C 公司:主要产出直接面向用户的产品,例如公子小白、小米音箱、天猫精灵、微软小冰等;有一些公司还做开放性框架,例如海知智能的如意、百度的 UNIT 等。当然,还有一些公司专门针对聊天机器人推出技能包业务,比如说故事技能、冷笑话技能、订票技能、大冒险游戏技能等。
2B 公司:主要做各种场景的落地,比如说金融领域的智能监管系统、医疗领域的医疗问答助手和诊断助手、银行柜台的客服机器人、淘宝店家的智能客服等。有些时候,场景落地也是在跟风,例如各大银行的智能客服,有一个感觉是别人做了,我就一定要做,这样才显得在 AI 上的先进性。但实际效果,大家在体验之后也会有所判断。
2G 公司:主要面向政府做政务类的知识库构建和问答业务。随着人工智能被写入政府工作报告,各级政府对于 AI 的落地应用都有比较高的需求。比如说政府服务大厅的引导型聊天机器人、一站式办事机器人;政府部门的智能搜索引擎和问答系统等。
在 C 端市场,产品是需要挑剔的用户买单的。正如本文上半部分所说,在目前的技术条件下,聊天机器人的使用感受远未达到用户的期望值,因此,很多 2C 公司在早期融资消耗完毕之后,产品也未得到用户的认可,从而不得不考虑业务的转型,走向 2B 和 2G 的赛道。但很清楚的一点是,转型之后,并不一定是技术好的公司就能接到单子,能否拿到项目,其中的因素也请各位自己体会。
另外,有一个很重要的误区在于高估了技术的作用。诚然,有一些非常优秀的学者,或者大公司出来的技术高管,利用自己的实力和拥有的核心算法,成功的进行了融资和快速发展,比如说第四范式、三角兽、竹间智能等公司。但大多数宣称自己拥有某一项垄断性技术的公司,都没有走到这一步。例如我前年曾经关注过的某创业团队,宣称自己的 NLU 技术世界领先,包括分词、词性标注、依存、命名实体识别等,在其官网上也很自信的提供 NLU 平台供用户试用,想要打造一个开放的聊天机器人平台。但现在再去看其发展,已经开始转向做 B 端的垂直场景业务了。另外还有一家公司,想用更深入的逻辑仿生技术打造机器人意识,然而其核心团队人员已经开始大量流失。
在目前的聊天机器人赛道上,很多成功的公司所使用的技术都不是自研发的,国内很知名的一家代工厂商,通过集成开放的 API 和 SDK,也能够打造一款低价的儿童聊天机器人,并做了很多 OEM 的业务。而且随着 Google、Facebook 等巨头的技术不断开源,技术的门槛也越来越低,就算是拥有一个世界级领先的单点技术,也很有可能不会比用规则匹配和大规模语料库拼起来的产品效果更好。
当然,技术领先,在另一方面,也可以用于提升公司的形象,做更好的 PR,从而获取更多的融资,吸引更优秀的人才。达到一个正循环之后,可以用足够多的资源将产品打造的更为优秀。
大家常说人工智能的三大要素,包括数据、算法和算力。而在聊天机器人的技术体系下,最关键的三个因素应该是人工、数据和算法。而在现阶段,人工是大于数据,更大于算法的。工程化才是一个产品成功的关键。
二、知识图谱能解决问题么
近两年来,随着 AI 热度的降低,无论是投资者还是从业者,都开始关注另一项技术-知识图谱。知识图谱技术也是一个融合型技术,包括数据库、自然语言处理、知识表示、机器学习等等。其最近的火爆程度,可以从国内知识图谱的旗舰会议(CCKS)的参会人数一窥端倪。CCKS 全称是全国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing)。CCKS2016 成立之初只有 500 名参会者,这个数据到了 2017 年是 600 人,2018 年是 800 人,而 2019 年杭州的会议,预计参会者将突破 1000 人。
作为从感知智能到认知智能跨越的重要基石之一,知识图谱被寄予了厚望。张钹院士也提到,「没有知识的 AI 不是真正的 AI」。拿最新的 GPT-2 算法来看,即使其文章续写能力让人赞叹,也只是再次证明了足够大的神经网络配合足够多的训练数据,就能够产生强大的记忆能力。但逻辑和推理能力,仍然是无法从记忆能力中自然而然的出现的。学界和企业界都寄希望于知识图谱解决知识互连和推理的问题。那么什么是知识图谱?简单来说,就是把知识用图的形式组织起来。可能这样说还不够明白,我们举例子分别说下什么是知识,什么是图谱。
所谓知识,是信息的抽象,一个很著名的 DIKW 体系,由 Rowley 在 2007 年提出,如图 5 所示。从数据到信息到知识再到智慧,是一个不断凝练的过程。
图 5. DIKW 体系
举一个简单的例子来说,226.1 厘米,229 厘米,都是客观存在的孤立的数据。此时,数据不具有任何的意义,仅表达一个事实存在。而「姚明臂展 226.1 厘米」,「姚明身高 229 厘米」,是事实型的陈述,属于信息的范畴。对于知识而言,是在更高层面上的一种抽象和归纳,把姚明的身高、臂展,及姚明的其他属性整合起来,就得到了对于姚明的一个认知,也可以进一步了解姚明的身高是比普通人更高的。最后的智慧层面,Zeleny 提到的智慧是指知道为什么(Know-why)[1],本文不对此进行深入论述。
图谱的英文是 graph,直译过来就是「图」的意思。在图论(数学的一个研究分支)中,图(graph)表示一些事物(objects)与另一些事物之间相互连接的结构。一张图通常由一些结点(vertices 或 nodes)和连接这些结点的边(edge)组成。Sylvester 在 1878 年首次提出了「图」这一名词 [2]。如果我们把姚明相关的「知识」用「图谱」构建起来,就是图 6 所体现的内容。
图 6. 姚明的基本信息知识图谱
在聊天机器人中使用知识图谱,我们的期望是能够解决很多复杂的推理问题,包括常识推理问题。比如说「鸡蛋放到篮子里,是鸡蛋大还是篮子大」,「苏大强的大儿子是谁」等等。从而使得聊天机器人的对话更加具有「智慧」,不仅能记忆,还能推理、联想和推荐,从感知层面真正跨越到认知层面。
愿望是美好的,但真正将知识图谱落地却鲜见成功案例。考虑到成本问题,知识图谱问答在聊天机器人中的应用还不够广泛。况且,一些需求方对知识图谱还存在不少误区。很多企业和政府机构在谈项目需求的时候,一上来就说,「我想用知识图谱技术,你们能不能把现在的知识库变成知识图谱?实现大数据的链接?」「你们做的问答是不是基于知识图谱的问答?」等等,其实,知识图谱问答能不能应用,要综合考量多方面因素,就拿知识的表示和存储来说,选用不同的数据库,需要用到不同的知识表示。RDF(数据的一种三元组表示形式)的数据表示可以选用 Jena 数据库,而图表示可以选用 Neo4j 图数据库。对不同来源的数据还需要进行大量的数据清洗和结构化,甚至还牵扯到纸质文档(例如医院的文本病历)的手工录入。结合业务来看,很多时候传统关系型数据库就能解决的问题,完全没必要用到大规模图数据库,否则很容易导致整个项目的成本高、效率低的问题。
Heiko Paulheim 在其文章《How much is a Triple?Estimating the Cost of Knowledge Graph Creation》中,给出了几个典型的知识图谱的构建成本。其中,上世纪 80 年代开始的也是最早的知识图谱项目 CYC,平均构建一条陈述句和断言的成本是 5.71 美元,而随着自然语言处理和机器学习技术的进步,DBpedia 构建每一条的成本降低到了 1.85 美分。即便如此,在真正工程化落地的时候,牵扯到多源数据的清洗整合,一个知识图谱项目的成本还是居高不下。
三、垂直领域的战略收缩
在人工智能投资火爆的前几年,我们经常会看到估值十亿到几十亿的聊天机器人(或智能问答系统)公司。就像浑水沉淀后能看见底下的泥沙,随着资本的逐渐冷静,很多公司也进入了艰难的寒冬期。这没什么不好,真正优秀的公司,无论是技术和商业模式,都能够经得起考验。
聊天机器人公司,在战略收缩的时候,首先要做的是看清自己公司的核心竞争力。最近看了一本书叫做《失去的胜利》,里面提到了德国名将曼施坦因对二战初期波兰战役的回顾和评论。当德国已三面包围波兰西部的时候,波兰军队仍然把主力沿着边境部署,而不愿意放弃西部工业区,并收缩到维斯托拉河流域右线重点设防。甚至还寄希望以英法联军的支援,反攻至柏林。结果可想而知,幻想守住一切,反倒丢掉了一切。
大部分初创公司,应该是集中优势力量突破一个点,等待资本回暖。同时精耕细作一个细分领域,在大公司无暇顾及的垂直行业杀出一条血路。无论是后期被收购还是能够独立壮大,都是比较好的结果。切忌大而全,什么都想做,做自己擅长的才是最重要的。举例来说,一些公司利用硬件优势转型打造语音交互芯片,另外还有金融知识图谱公司从智能投顾转为智能监管,还有大批聊天机器人公司,从做纯软件的聊天机器人转为为 B 端客户提供智能客服解决方案。
而且,对于做平台这个事情,要单独提出来聊一聊。自然语言交互平台,没有大量的人员和资金支持,是无法实现的。由于没有办法进行工业级产出,导致了大量资本投入换来的只是 Demo 和论文,而不是实实在在的产品。因此,在细分领域做强做好,才是小公司的生存之道。
四、商业模式和产品的重要性
从技术到产品落地,还只是万里长征的第一步,产品在市场上真正被用户所接受,并能产生良性的流水和利润,这才是正常的商业模式。我们看下目前几个比较火热的聊天机器人产品。首先是儿童教育机器人,教育、医疗和金融是一直都很热的领域。自然而然的,很多产品都会冠以人工智能教育机器人的名号。但儿童教育聊天机器人真正能解决用户需求么?很明显不能。大多数家长还是报以尝鲜的心态,给孩子买一个玩具,并没有寄希望于让机器人起到「教育」的作用。但毕竟儿童市场是巨大的,中国有 1.5 亿 3 到 12 岁的儿童,每年的新生婴儿数量也达到了 2000 万。儿童教育机器人的出货量在近三年一直保持着 100% 的增长。因此,在这个市场上,影响用户购买的很重要的一个因素是价格,也就造成了目前整个行业利润的持续走低。随着更多厂商的加入,红海市场也逐渐变成了血海市场。另外一个典型的案例是老人陪聊机器人,这种机器人从商业模式上来看,我认为并不成立。首先,老人们对聊天机器人的接受程度不高,购买力也不强。其次,老人在对话过程中,由于对话速度、连贯性、方言等问题,使得聊天机器人的表现要更差。
最近网上讨论的很多的一个典型案例是夸夸机器人。其来源是「相互表扬小组」,这些活跃在 QQ、微信、微博上的社群的目的,言简意赅又单刀直入:溜须拍马,相互夸奖。无论是高兴的事情例如考上了大学、获得了奖励,还是倒霉的事情例如被老板骂,烤糊了面包,在群里都可以得到天花乱坠的夸赞。而有公司还真的将夸夸机器人产品化,但结果是昙花一现,仅是蹭了一波热度,却没有持续的用户留存。其实,夸夸机器人在商业角度上是不成立的,没有一个可行的变现路径。三联生活周刊有个评论说到:「人们容易为快节奏的生活所累,更容易在各种新鲜事物面前短暂停留。所以人们也清醒地意识到:来自陌生人的鼓舞与表扬虽然温暖,但保质期却是极其有限与流于表层的」,因此付费求夸的事情也变得不切实际了。
再来看下 2B 的业务,真正成功的项目应该是给需求方带来成本的降低或收益的提升。比如说淘宝店家的客服机器人,一套系统的成本,如果能够低于将 200 位人工客服降低到 100 位所节省下来的成本,同时在获客效果上又有所提升,那就是一个成功的项目。况且,对于开发者而言,从单一项目逐步变为 PAAS 服务或 SAAS 服务,所带来的开发成本会显著降低,也就可以为规模化打下良好的基础。
刚刚聊了一些商业模式的问题,那么从产品形态上,有一句流行的话说的是「技术不够,产品来凑;产品不够,运营来凑」。既然聊天机器人受限于技术无法达到人类期望值,那么是否可以从产品设计的角度上,让用户不去关注技术表现本身,而是从其他维度对产品产生粘性?答案是肯定的。做产品的关键在于「高出用户期望值」,这显然对于 AI 产品是不友好的,因为用户期望值太高了,所以要在其他层面上去想办法。文章一开始提到,产品设计的一个原则应该贴合人类的七宗罪。我们曾经获取过一批来自不同聊天机器人脱敏后的用户聊天数据,其中包含了很多难等大雅之堂的语言。所以有一些成人用品公司开始用对话技术包装自己的产品,也算是一种成功的商业实践了。
当然,从正常的产品角度而言,如果一个聊天机器人产品的形象和使用感受,超越了聊天本身,给用户带来了不同的惊艳感,也可以算得上一种取长补短的方法。正如我们下一节要讨论的聊天机器人的更多形态,如果聊天机器人被人格化、IP 化之后,用户也不会仅仅关注对话,而是会从更多的需求层面产生对产品的粘性。
五、多模态交互和虚拟生命
在技术不断进步的同时,聊天机器人也逐步迈向其下一代范式-虚拟生命。其核心在于模拟生命的主要特征,以多形态和多模态进行交互 [3]。设想一下,如果你是蔡徐坤的粉丝,如果有一个聊天机器人具备蔡徐坤的形态和声音,并且可以进行交互,那是多么令人兴奋的一件事情。同时,在不同的性格和人设下,虚拟生命的交互体验也会变得更为丰富。
再进一步,除了 IP 化和人格化,多模态交互能力会进一步增强虚拟生命对用户的认知和表现力。虚拟生命能够通过麦克风阵列、摄像头听得到、看得见,使其能够综合感知用户意图。同时,利用知识图谱,虚拟生命能够和人以及周围环境进行「真实自然」的交流,包括规划、推理、联想、情感和学习能力,具有非常强的可用性和可交互性。再进一步,通过美术设计、动作捕捉、全息投影等技术,虚拟生命可以在不同设备、不同场景下展示不同的形象,除了自然语言交流,还可以进行舞蹈、唱歌等更多样的体现。
目前日本的 Gatebox 和国内的狗尾草智能科技,都提出了聊天机器人的虚拟生命形态。例如,狗尾草智能科技开发了世界上第一款结合了 GAVE 引擎(Gowild AI Virtual Engine)的虚拟生命产品-琥珀•虚颜(如图 7),搭载 HoloEra 硬件平台及 360°全息投影,创造一个有情感、可养成、可进化的虚拟存在,但这种存在又可以和周边世界进行多模态真实互动,并针对用户行为习惯形成不同的性格体系。同时,人物还可以换成二次元角色和真实的明星,进一步提升用户体验和粘性。
图 7. 虚拟生命产品-琥珀•虚颜
在这个新的赛道上,相信未来的聊天机器人以及虚拟生命,会以更好的形态和体验感呈现给我们。
六、革命尚未成功,同志仍需努力
在这个广阔的市场上,进步的空间还很大,挑战还有很多。但有挑战的事情才有意思,不是么?
-
全球机器人发展现状2016-01-28 4270
-
聊天机器人在国内为什么只能做客服?2017-06-20 3850
-
聊天机器人的自动问答技术实现2019-06-03 3199
-
嵌入式系统开源软件的现状及未来的发展方向2021-04-28 3099
-
如何利用Python+ESP8266 DIY 一个智能聊天机器人?2022-02-14 2336
-
与机器人技术结合的确是 VR未来可能的发展方向2016-07-28 1953
-
巨头分食聊天机器人大蛋糕 个性化部署是未来方向2016-11-08 1149
-
聊天机器人的作用分析2017-09-20 1264
-
会说话就叫聊天机器人,这个七个指标符合吗2017-12-05 1491
-
微软频繁出手 计划研发聊天机器人2018-11-16 1019
-
人工智能聊天机器人的发展将成为未来市场的趋势2019-12-08 3559
-
7大关键指标衡量一个公司使用的聊天机器人是否合格2020-09-03 999
-
聊天机器人开源分享2023-06-20 955
-
英伟达推出全新AI聊天机器人2024-02-19 2133
-
NLP技术在聊天机器人中的作用2024-11-11 1966
全部0条评论

快来发表一下你的评论吧 !
