

借助 NVIDIA GPU,亚马逊Alexa语义识别模型的识别准确度提高了15%
描述
近期,来自于约翰霍普金斯大学(John Hopkins University)和亚马逊(Amazon)的研究人员们发布了一篇论文,介绍他们是如何通过训练一个深度学习系统来帮助亚马逊Alexa语音助手识别并忽略那些并非是对她说的话,从而将其语义识别模型的识别准确度提高了15% 。
研究人员在他们的论文中指出,“诸如Amazon Echo和Google Home的这类家用声控设备都面临着一个问题,那就是当周围存在干扰声源的时候,设备如何能够照常地识别指令。”
为了让Alexa更好地识别指令,研究人员训练了一个神经网络,来匹配和识别“唤醒词”(通常是“Alexa”)以及紧随其后的指令,并忽略那些来自于其他人或媒体设备的干扰。
研究人员介绍说:“这项任务的挑战在于需要从含有特定词汇的话语片段中学习使用者的语言习惯。借助于两种不同的神经网络架构,我们最终实现了这一目标。两个神经网络架构都是具有注意机制的序列到序列编码器 - 解码器网络的变体。”
借助于NVIDIA V100 GPU和OpenSeq2Seq 工具,用于序列到序列模型的分布式和混合精度训练,使用TensorFlow建立,团队用1,200小时来自于Amazon Echo的实时英文数据训练他们的算法。
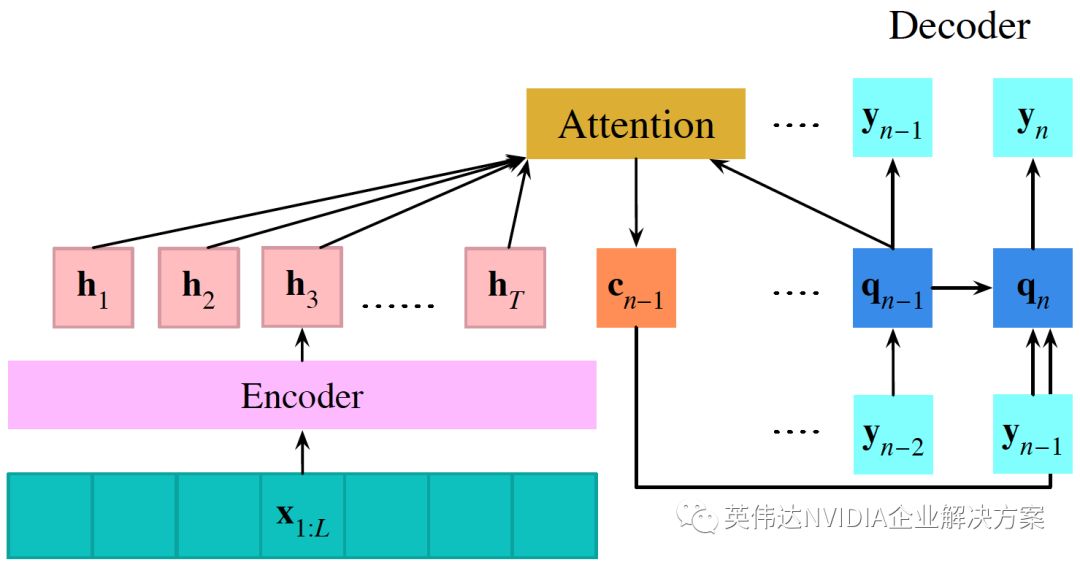
通过改进所开发的基线网络,该团队还添加了一个额外的输入端,能够通过优先处理类似于锚字的语音来增强注意机制。研究人员总结说: “在训练期间,注意机制会自动学习唤醒词的哪些声学特征,以便在随后的演讲中寻找。”
该团队还开发了一个mask-based模型,该模型能够更加明确地将输入语音与锚字的声学轮廓相匹配。
最后的测试结果显示:第一种方法的性能更好,达到了15%的改进;第二种模型也达到了13%的改进。
根据研究人员介绍,该算法在训练和推理过程中都采用了NVIDIA GPU。
-
基于LTC6802的电池管理系统准确度提升2019-05-06 1306
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2490
-
简单的校准电路最大限度地提高了锂离子电池管理系统中的准确度2009-12-20 650
-
提高了准确度的取样保持电路2009-04-11 931
-
动态加权平均行人识别模型2017-11-21 1309
-
基于四层树状语义模型的场景语义识别方法2017-12-07 1346
-
亚马逊Alexa的深度学习与语音识别的核心技术原理2018-03-21 5003
-
新人工智能模型提高预测乳癌准确度达87%2019-07-19 1134
-
影响示波器测量准确度的因素,有哪些提高准确度的使用技巧2020-10-09 3015
-
亚马逊Alexa运算迁移至自家芯片2020-11-16 2180
-
DN471 - 简单的校准电路最大限度地提高了锂离子电池管理系统中的准确度2021-03-19 832
-
基于大数据和语义识别模型的地震救援平台2021-07-05 723
-
AutoML技术提高NVIDIA GPU和RAPIDS速度2022-04-26 3678
-
AI大模型在图像识别中的优势2024-10-23 3868
全部0条评论

快来发表一下你的评论吧 !
