

浅析嵌入式数据挖掘模型应用到银行卡业务中的相关知识
嵌入式技术
描述
数据挖掘就是从存放在数据库、数据仓库或者其他信息库中的大量数据中挖掘有趣知识的过程。它是在多种数据存储方式的基础上,借助有效的分析方法和工具,从传统的事务型数据库功能(增加、删除、修改、查询、统计等)背后,获得更深层次的信息。在数据挖掘技术的不断发展过程中,如何将数据挖掘(DM)系统与数据库(DB)系统和数据仓库(DW)系统紧密耦合(所谓耦合,即是数据挖掘系统和数据库或者数据仓库的集成程度)在一起是始终困扰着人们设计一个好的数据挖掘工具的最大问题。从最初的不耦合到松散耦合再到半紧密耦合,人们一直寻求着如何将DM系统平滑的集成到DB/DW中(即紧密藕合)。目前众多数据挖掘系统、数据挖掘工具中,大部分都是实现一个与数据仓库系统独立开来的数据挖掘系统,这样便使得数据挖掘过程中要花费大量的时间进行数据加载转换,算法运行时间长、效率低,特别是面对当前数据仓库中保存的海量数据时,更是效率低下。
文中在已有的数据挖掘系统体系基础上,应用数据挖掘系统与数据仓库系统紧密耦合的策略,提出了嵌入式数据挖模型,把数据挖掘系统和整个数据挖掘流程完全控制在数据仓库系统中,从而大大提高数据挖掘的效率。并且针对市面的一些用于银行卡业务的数据挖掘系统过于繁琐,但是效率不高、针对性不强等问题,本文提出将嵌入式数据挖掘应用于银行卡业务中,使得应用针对性更强,在节约了开发成本的同时也提高了挖掘效率。
1 嵌入式数据挖掘模型
嵌入式数据挖掘模型主要是采用多种数据库访问技术把算法嵌入到数据挖掘系统中。该模型支持按照一定的标准规范来开发挖掘算法,并把算法发布嵌入到多种数据库、数据仓库当中,将数据挖掘过程完全控制在数据库、数据仓库系统中,将数据挖掘功能转换成大家熟悉的、通用的、灵活的、可二次开发的数据仓库功能。
该系统框架主要由数据层、算法嵌入层、数据挖掘层以及用户层,系统模型如图1所示。
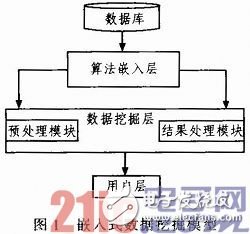
1.1 数据层和用户层
数据层主要包括数据库或数据仓库中的海量业务数据以及元数据,它是数据挖掘过程中最基础的部分。
在该模型中,用户层包括算法发布人员、数据分析人员、数据库管理人员,即使得数据挖掘面向更多的用户,摆脱了以前数据挖掘对专业人士的过多依赖性。
1.2 算法嵌入层
整个嵌入流程可以分为两个过程:算法发布和算法调用。算法发布过程主要是把算法发布到特定的数据仓库系统中,为数据挖掘系统在数据仓库系统中的执行奠下基础;算法调用过程则是在数据仓库系统中进行的,主要通过数据仓库系统中的存储过程,让用户传人相关参数,然后调用第一步发布的算法对用户指定的数据进行挖掘。
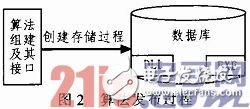
1)算法发布
算法发布过程首先就是把算法封装成DLL文件,同时把调用算法的接口编译成EXE文件,然后把算法DLL文件和相应的EXE文件发布到数据库或数据仓库中,最后在相应的数据库中创建存储过程(简称SP),流程如图2所示。
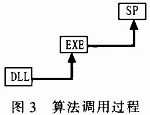
2)算法调用
在调用过程中,由于不同数据仓库系统的存储过程的功能大小不同,不同数据仓库系统对EXE文件,DLL文件的调用方式都有很大的区别,所以具体的实现细节在不同数据仓库系统下还是有很大的区别的。在该模型中,数据仓库终端调用存储过程(SP),把算法参数和用户参数传进存储过程,然后让存储过程调用EXE文件,EXE文件主要是处理存储过程传入的参数,然后调用DLL算法生成挖掘结果。具体流程如图3所示。
1.3 数据挖掘层
1)预处理模块
数据预处理在数据仓库(或数据库)中进行,主要有两个途径可以实现:一种是直接利用数据仓库管理系统(SQL等)来对数据仓库的数据表进行加工处理,还有一种就是像挖掘算法一样,用高级语言实现,然后嵌入到数据仓库系统中,用户就可以像一般的存储过程一样调用相应的预处理方法来对数据进行预处理。这两种预处理可以相互循环使用,直到加工满意的数据为止。
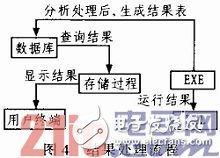
2)结果处理模块
结果处理流程其实和算法凋用过程是同时进行的,在EXE文件中通过数据库访问技术获取数据,在EXE中调用DLL算法产生文本结果返回到EXE文件中。这时候,这个文本结果可以经过加工处理写回数据仓库,同时也可以展示给用户。具体如图4所示。分析处理后,生成结果表查询结果。
2 嵌入式数据挖据的应用
2.1 嵌入式数据挖掘在银行卡业务中的应用
目前的数据挖掘技术在银行卡业务上的应用大多存在3个方面的局限:1)效率不高:面对目前的海量数据挖掘时,显得无能为力;2)专业化程度较低:不能很好的专门针对银行卡业务进行挖掘;3)开销较大:需要开发专门的系统来进行数据挖掘,而且大多数系统不能进行二次开发。
嵌入式数据挖掘显然很好的弥补了普通数据挖掘技术所带来的缺陷。首先,嵌入式数据挖据是把算法直接嵌入到数据仓库下,从而减少数据转换的时间,充分利用整个数据仓库的处理能力,大大提高数据挖掘的效率;其次,它实现了算法的组件化管理,针对不同的行业开发不同的算法组件,对银行卡业务进行数据挖掘的主要目的是对客户进行分类,从中发现对银行贡献度较大的优质客户,嵌入式数据挖掘可以开发单独的算法专门满足客户分类的需要,从而具备了很好的专业性。最后,嵌入式数据挖掘系统是个种很灵活的数据挖掘系统,客户可以在系统中不断添加新的算法、改进算法,同时进行二次开发,从而省去了重新开发大型系统的开支,这点对于当今企业来说显得尤为重要。
2.2 应用实例分析
为了证实嵌入式数据挖掘模型的有效性,我们与中国银行湖南分行进行了合作,采用其信用卡业务数据分别对嵌入式数据挖掘模型系统和非嵌入式数据挖掘模型系进行运行对比,测试是在PC机(P4 2.5G CPU,HY DDR512M RAM)上进行的,选取CMP和Apriori两种数据挖掘算法。选择嵌入的数据库为SQL Server 2005实验钱据从10 000条记录到160 000条记录,以测试上述两种算法在大小不同数据集上采用嵌入式数据挖掘和非嵌入式数据挖掘所表现出的性能差异。嵌入式数据挖掘在银行卡业务中的应用主要包括关联规则挖掘和分类挖掘。
1)关联规则挖掘
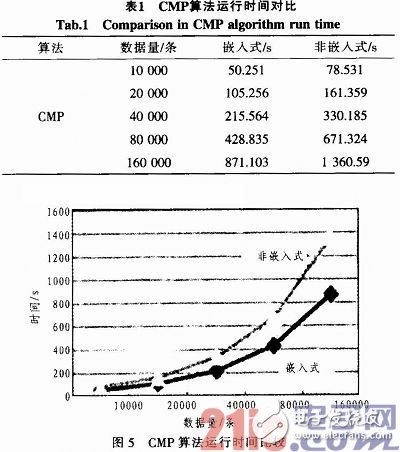
综合持卡人用卡行为和基本情况进行分析,导出具有一定支持度和可信度的用卡习惯的人群组成之间的关联规则。在算法选择方面,选择了由wang H等提出的一种新型高效决策数算法:CMP算法。在实例中,当实例数据呈倍数增长时,数据挖掘所需时间对比如表1所示。
算法运行效率曲线如图5所示。
2)分类挖掘
根据持卡人的使用情况和交易方式,对持卡人群进行分类,主要分为优质客户、潜在优质客户、流失客户和潜在流失客户等,这也是当前比较流行的用法。在分类挖掘过程中,使用关联规则中的Apriori算法对实例进行了数据的挖掘,算法时间对比如表2所示。
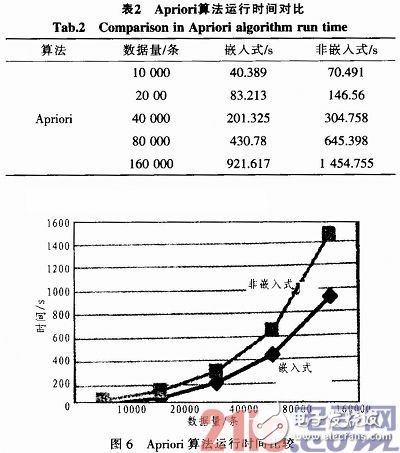
算法运行效率曲线如图6所示。
从以上对比数据可以看出,在将嵌入式数据挖掘应用到银行卡业务数据的挖掘当中后,对于两种不同的算法,其效率的提高都是显而易见的,从图形中可以看出,不管是CMP还是Apriori,其效率上都有2~3倍的提高。从应用实例中,还可以看出,随着业务数据量的不断加大,嵌入式数据挖掘能更进一步的节省时间。整体说来,嵌入式数据挖掘模型是非常有效的,同时把它应用于银行卡业务数据的挖掘中也是切实可行的。
3 结束语
嵌入式数据挖掘模型使挖掘算法更加简单易用、方便,它将成为第四代数据挖掘系统的一个重要发展方向之一,也是数据仓库系统,商业智能平台的一个重要发展方向。把新的嵌入式数据挖掘技术应用到银行卡业务中,一方面可以验证嵌入式数据挖掘技术的优越性,推动数据挖掘技术的发展;另一方面,为商务智能应用软件升级做出贡献,这是一个极具吸引力的课题,具有十分重要的社会效益和经济价值。
-
分区存储助力QLC应用到嵌入式存储设备2023-11-27 1369
-
银行卡信息精准识别-智能快速绑卡2023-07-12 2497
-
嵌入式系统是怎样应用到企业中去的?2021-04-27 1538
-
移动端银行卡识别技术,基于Android、iOS系统2020-06-17 1061
-
数据挖掘算法有哪几种?2020-03-11 2099
-
nfc手机读取银行卡2019-02-28 38982
-
银行卡手机拍照识别sdk2018-08-07 512
-
云端银行卡识别技术的特点和优势2018-07-25 2366
-
嵌入式数据挖掘模型应用实例2017-10-17 1088
-
指纹识别技术在银行卡业务中的应用分析与设计_曾庆勇2017-03-20 927
-
银行卡刷卡的WAV转成0101信号问题2016-03-16 2621
-
提供银行卡识别API免费接入的OCR SDK开发者平台2015-09-16 2970
-
嵌入式数据挖掘模型及其在银行卡业务中的应用2012-08-13 1203
-
避开自助银行“门禁陷阱” 防范银行卡欺诈2009-12-10 1212
全部0条评论

快来发表一下你的评论吧 !
