

以太坊的无状态客户端思想探讨
区块链
描述
自从看到了这篇文章,我便一直很想深入了解以太坊的无状态客户端。当然,经过15个月的摸索,我对以太坊中的状态、软件、网络的认知都发生了很大的变化,比如说,我现在认为要引入无状态客户端,则硬分叉在所难免;这与我之前的想法不同。但即便如此,我还是很高兴能分享一些学习上的收获,并给出后续发展建议。
无状态客户端的思想
在阐述无状态客户端之前,我们先来看看在以太坊客户端软件中一般的交易处理过程:
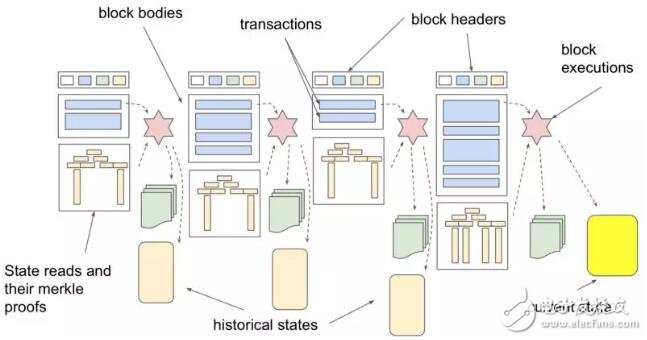
在区块中执行交易需要交易数据(蓝色矩形所示),及当前状态(黄色矩形所示);执行结束后,原本的当前状态变为历史状态,同时产生新的当前状态。处理交易可能还需要一些别的数据(如区块时间戳,或是前个区块哈希值),但我们先忽略这些大小固定且无关紧要的部分。执行交易还会产生明细(receipt)(绿色部分),但在讨论无状态客户端时也可暂时忽略。
无状态客户端的核心思想是:在区块中执行交易过程时,不访问整个状态。区块创建者以分离的数据结构作为区块补充,里面提取了执行交易所需的所有状态;为了让执行交易的人相信这些额外数据的确来自当前状态,还要附上默克尔证明。这是可以做到的,因为每个区块头都带有 “状态根”,这个默克尔树根凝结了区块内交易执行完成后所有的状态值。有了这些证明,我们能够以下面这种形式执行交易:
值得一提的是,这些区块信息(我们称之为 “区块证明”)对于有状态客户端(那些想要保有全部状态和历史数据的客户端)来说也是非常有用的。当前情况下,所谓的 “全节点” (在接收到区块时)会依凭本地保存的状态执行区块交易,计算新状态的默克尔根并验证是否与区块头的默克尔树根相同(译者注:以此验证新区块的合法性)。计算默克尔树根需要大量的计算资源,包括大量内存以及大量 I/O 读写,详细的描述见此。如果拥有前面的补充信息,全节点验证执行过程的正确性会变得非常容易,大部分情况下将不需要涉及读写操作,就能够基于执行结果更新当前和历史的状态数据库;全节点无需缓存状态树,与当前状态和历史状态数据库的交互转为以写入为主。具体过程如下:
区块证明占多大空间?
无状态客户端最大的缺点是——除了区块,还需要在网路中传输一些额外的数据(区块证明)。究竟这些额外的数据有多少呢?为了计算区块证明的大小,我基于 Turbo-Geth 创建了一个无状态客户端原型,以下是它做的事情:
1. 从以太坊主网逐一收集区块
2. 对每一个区块分别抽取出交易需要访问的状态,以及被交易访问的智能合约字节码
3. (通过计算状态默克尔树根)选取出足以验证所提取状态确实属于状态的最少哈希值集合
4. 添加一些结构信息,将上述证明(哈希值集合)和状态抽取物编码为树型结构。可能采用的编码方式不是最好的,不过结果表明编译出来的输出远小于其他部分,所以可接受。
5. 将区块证明编码为字节数组。
6. 将字节数组解码出区块证明(即那个树型结构的数据,一些节点来自于状态,一些则是无关状态部分的哈希值)。
7. 再次执行区块,不过这回不访问当前状态,而是直接与区块证明进行交互。
8. 验证状态根和所有存储根的正确性。
整个流程花了不少时间,但我希望得到的数据足够精确。如我所料,虽然这个原型已经能处理许多琐碎的问题(因为 hexary 的默克尔帕特里夏树包含叶节点、扩展节点、嵌入节点等等复杂的结构),还是有一些罕见情况导致我的原型报错(在区块 5340939、5361803、5480357、5480507、5480722、5632299、5707052、5769636 。..。.. );不过考虑到 670 万个区块中只出现数十个报错,我有信心这些小问题不会影响数据分析的结果(当然,我会尽快 debug)。
目前我的数据只采集至第6757045 个区块,但我想很快就能超过这个数字。
第一张图表表示区块证明的总体量(注:所有图表都经过窗口 = 1024 的移动平均计算)。
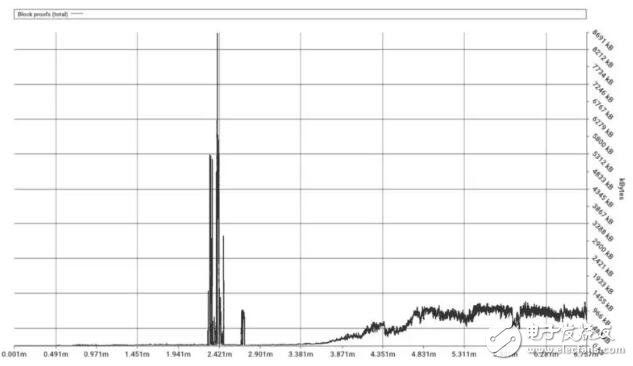
在伪龙硬分叉(区块 2675000)之前,少量的 gas 消耗也可能产生非常大的区块证明, 这个缺陷已经在 2016 年秋天被修复。
下面我们只看伪龙硬分叉后至今的数据表现:
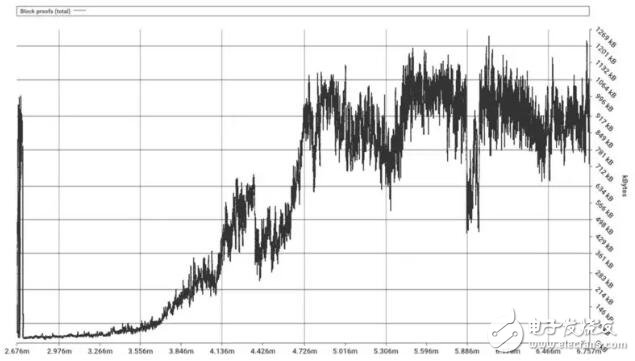
为了清除余额和 nounce 值为零的账户状态,伪龙硬分叉后进行 “状态清理”,导致图表最左侧 “峰值” 的出现。但 2017 年下半年,以及 2018 年的 “区块证明” 的规模已经超过了当时的水平。
分解
首先,我们将区块证明分解为三个部分:1)所有与 “主” 状态树有关的部分;2)所有与合约存储树有关的部分;3)智能合约字节码。
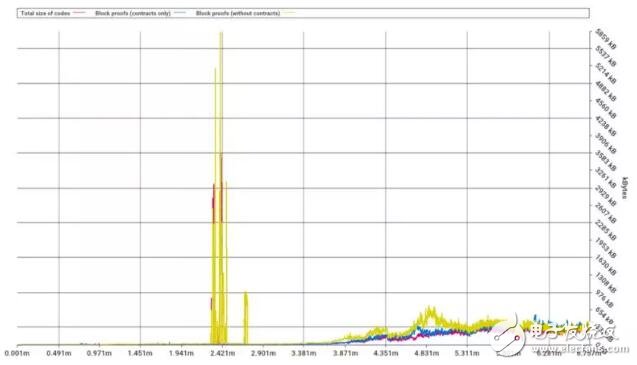
可能从图上有点看不清楚,不过可以看到 2016 年发生的垃圾攻击造成当时的字节码(红线)和 “主” 状态树的区块证明(黄线)激升。有些人还记得,当时对于智能合约的字节码大小并没有限制(现在限制小于 24k),造成当时能够部署超大的智能合约,并通过 EXTCODESIZE 之类的函数进行查询。
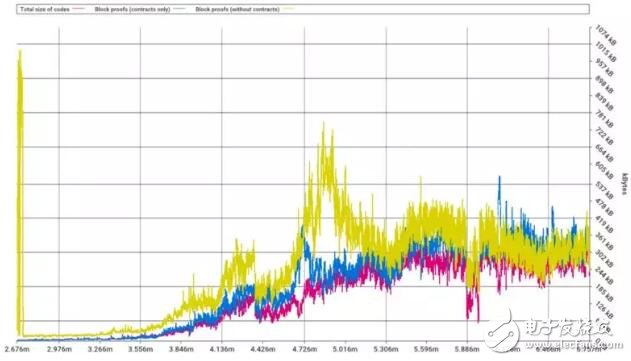
实施伪龙硬分叉后的图表表明,主默克尔树的区块证明在过去大部分时候体量占比较大,不过合约存储证明(蓝线)和字节码随后开始赶上。
分解状态树区块证明
这里我们会进一步将状态树区块证明分解为四个部分。前两部分是交易需要读取的键值对,或者是为了满足默克尔帕特里夏树的一些特殊需求所需的数据。
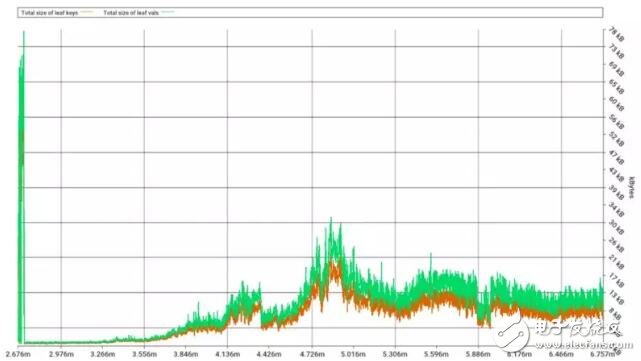
看起来状态清除操作对于读取键值对还是造成很大的影响。我们会发现键值对中值的大小(一般是 80 字节)通常比键要大得多( key 一般小于 64 字节,而我刚刚才意识到键可以被压缩,因为我把每个十六进制数都算为一个字节)。
接下来,我们看看用来建构默克尔证明的哈希值,以及那些我称之为 “mask(掩码)” 的结构化信息:

可以轻易发现,相比于哈希值,结构化信息的大小是可以忽略不计的;也可以进一步说明哈希值占区块证明大小的主要组成部分(对于合约存储证明来说也是如此)。
分解合约存储证明
与前面相同,首先是键值对:

有意思的是,合约存储证明中键值对的值(最多占 32 字节)通常远小于键。
接着是哈希值和结构化信息:

可以看到,与状态树区块证明的表现相似。
与状态费用研究的相关性
我搞这个研究的其中一个目的是想弄清楚使用无状态客户端是否能规避某些类型的租金(译者注:所指应是 “状态存储租金”)。因为当前最大的挑战在于:合约存储租金的存在,可能会导致许多现有的合约遭受 griefing 攻击(译者注:大意为尽管不能让攻击者受益,但会让受害者感觉很苦恼的攻击形式)。为了保护智能合约避免遭此类攻击,“状态费用” 协议第三版提出了费用预付(押金)的概念,能暂时保护合约免受攻击,给已部署合约提供一些缓冲时间,能够升级为不受影响的代码。
无状态客户端的构想,至少在让智能合约存储免受 griefing 攻击方面(如上文所示),提出了一种成本虽高但永久有效的预防方法。
不过如果真的引入某种无状态客户端,交易发送方无可避免的必须针对交易产生的区块证明,按比例支付额外的 gas,这样一来合约存储操作(SLOAD、SSTORE)的成本可能比现在高昂。附带一提,Martin Swende 最近的分析表明 SLOAD 费用似乎被严重的低估。
我们可以将无状态客户端用于已有的智能合约,并让新的智能合约自主选择是否使用存储租金。我估计这个租金会比使用 “区块证明” 的成本便宜许多,但总有一天这个临时费用会消失(因为大家都使用无状态客户端啦)。我们不会强迫已有的智能合约在某个时间点必须转变为兼容可选费用的部署形式,相反地我们希望以激励手段鼓励大家进行迁移。
后续的建议
显然,我要增加数据收集至当前区块,并修复数据分析中存在的 bug 。
即使我们去掉与合约储存相关的部分,区块证明的大小仍是个值得重视问题。我认为有两种方案能降低它的大小:
1. 在无状态客户端中引入多一点的 “富状态性”。如果大多数客户端都持有最新的 N 个区块证明(N = 1, 2, 3 。..),现在你(以太坊节点之一)知道你的对等节点保有许多以前的区块证明,那么你可能会选择只发送后 N 个区块证明中不包含的部分。因为你知道节点有能力重构完整的状态证明。这个方案还需要经过更多分析验证。
2. 使用 SNARK 证明,将现在区块证明中可变的 “哈希值” 部分压缩为固定大小(就我所知,目前 SNARK 产生的证明大小约 60k 左右)。这个方案还需要投入更多的研究和开发工作,比如围绕 Keccak256 算法创建 SNARK 证明,要考虑证明需要付出多少成本,是否需要用 CPU 加速证明过程、保证出块速度足够快等等。
-
MQTT中服务端和客户端2023-07-30 4024
-
HTTP客户端快速入门指南2023-01-12 638
-
#硬声创作季 #区块链 区块链开发-015 以太坊理论_以太坊客户端简介-1水管工 2022-10-09
-
Labview客户端状态获取2021-11-15 4378
-
以太坊无状态客户端是什么2020-12-25 1446
-
什么是无状态以太坊2020-01-06 2674
-
以太坊无状态客户端究竟是什么2019-11-29 790
-
基于一个开源的以太坊客户端Hyperledger Besu介绍2019-09-11 5879
-
iOS端淘宝客户端应用名称发生变化 Android客户端应用名称尚未更改2019-04-18 1340
-
以太坊无状态客户端是什么意思?有什么解决方案?2018-08-08 1901
-
CSDN博客客户端源码2015-11-18 884
-
CoolpyCould客户端2015-11-06 772
全部0条评论

快来发表一下你的评论吧 !
