

AI把狗认成猫 只因它在捕捉人类看不到的特征
电子说
描述
近日,一个来自麻省理工学院(MIT)的团队公开了他们的研究成果。该文章指出,对抗样本(Adversarial Sample)导致图像识别(Image Classification)失效的现象,或许只是人类的一种“自以为是”。识别模型捕捉的,其实是那些不能被人眼察觉的“非稳健特征”(Non-robust Feature)。如果只是基于这些像素层面的特征,模型对对抗样本的识别就不能被认为是失败的。
几乎所有图像识别算法都存在一个弱点——对抗样本问题。对抗样本是指在一张自然图片中,对少部分像素点的数值进行修改,即使修改不足以被人眼察觉,但识别算法却做出完全错误的判断,比如把小狗识别成鸵鸟。这可能成为致命的安全漏洞,比如让自动驾驶的汽车偏离车道,或者让监控探头无法发现罪犯的身影。《给 T 恤印上一个图案,就能在监控下实现“隐身”?》
图|左为自然图片,识别为“小狗”。右为刻意修改后的对抗样本,识别为“鸵鸟”。(来源:Christian Szegedy/Google Inc.)
目前许多研究机构(如谷歌公司、麻省理工学院和腾讯科恩实验室)都在尝试解决对抗样本问题。其中主要的难题存在于三个方面,首先是视觉世界的复杂性,比如一张图片中通常存在上百万个像素点。其次,我们并没有彻底地理解卷积神经网络模型(CNN)实现图像识别的机制。此外,科学家不知道识别模型失效的原因是训练方式的问题还是训练数据量不够大?
麻省理工学院的科研团队发现,目前常用的识别模型其实是通过关注图片中,人眼无法察觉的细节来实现图像识别。就如同人类会对比耳朵的不同,而将狗和猫的照片区分出来一样。但是AI模型却是在像素的层面进行区分。
论文的第一作者,麻省理工学院在读博士生 Andrew Ilyas 说道:“对于那些像素层面的特征,它们最大的特点就是不会被人眼察觉。”
想要弄明白 AI 到底是依据什么特征来识别图像并不容易。Andrew Ilyas等人首先定义了一整套理论框架。他们把图片中的特征分成两类:“稳健特征”(Robust Features),指即使做了像素层面的修改也不会影响识别结果的特征(如耳朵、胡须),和 “非稳健特征”(Non-robust Features),即会被像素修改而影响的特征(通常无法被人类识别)。
其次,他们又定义了两种训练模型的方法,“标准训练”(Standard Training)和“稳健训练”(Robust Training)。稳健训练的损失方程额外考虑了对抗样本的存在,使得模型在训练中可以强化对稳健特征识别。
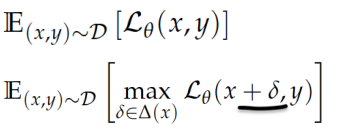
图|标准训练和稳健训练的损失方程。稳健训练中划线的部分表示修改原始数据,使之成为对抗样本。(来源:Andrew Ilyas/MIT)
他们假设稳健特征和非稳健特征同时存在。并且使用和生成对抗网络(GAN)相似的方法,将原始的训练数据集(D)中的图片进行重新加工,生成了两个新的数据集:将非稳健特征洗刷掉、只含稳健特征的 D_R,和在人类看来错误标注、但非稳健特征符合其标注的 D_NR。
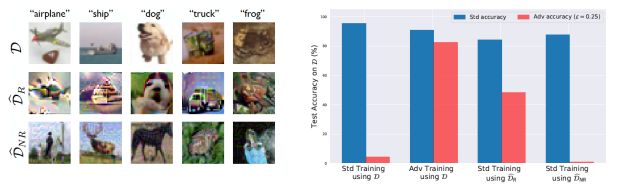
图|左:原始训练数据 D,只含稳健特征的 D_R,和失去特征一致性的 D_NR。右:三种数据集在不同训练方式下的准确率。(来源:Andrew Ilyas/MIT)
研究人员指出,由于只有稳健特征,D_R 所含的信息量少于原始数据 D。实验发现,再以 D_R 为基础,以标准训练的方法得到的识别模型,同样可以抵御对抗样本。以此证明像素层面的修改(人眼无法分辨),并不影响图片中的稳健特征。
另一方面,研究人员对训练数据(D)进行像素层面的修改,并且不断优化,让标准模型尽可能地把图片识别成另一个类型。比如,稳健特征(人眼观察)是“狗”,而非稳健特征和标注(模型认为)则是“猫”。
研究人员将经过修改的图片集计作 D_NR,并找来一张训练数据之外的自然中“猫”图片进行测试。识别器成功把这张外来的图片也识别成了“猫”。说明这张自然的“猫”,和 D_NR 中的“猫”具有可以被模型识别的相同属性,而这个属性就是我们看不到的“非稳健特征”。
图|图中右侧“狗”的图像,和下方“猫”的图像,都被识别成了“猫”,他们有相同的非稳健特征。(来源:Andrew Ilyas/MIT)
通过实验,Andrew Ilyas 和他的团队确定:稳健特征和非稳健特征都存在于图片之中,并且一般的识别模型只会通过非稳健特征进行图像识别,而非稳健特征不能被人眼察觉。所以,对抗样本本身并不是图像识别的漏洞,只是另外一种无法被我们看到的特征而已。
“这并不是模型本身有什么问题,只是那些真正决定识别结果的东西并不能被看到。”该论文第二作者、麻省理工学院在读博士生 Shibane Santurkar 补充道:“如果我们只知道算法的决策取决于一些我们看不见的东西,那我们又怎么能理所当然地以为它做的决定就是正确的?”如果一个人需要在法庭上证明监控视频中的人不是自己就会非常麻烦,因为我们不知道监控识别的错误结果是怎么得来的 。
科学家始终需要面对一个抉择,模型究竟是应该做出“准确”的决定,还是应该做出“人类”的决定?如果模型只是识别稳健特征,它或许就不会那么准确。然而如果决策机制偏向不能被看到的非稳健特征,那么对抗样本就会成为潜在的漏洞。如今,图像识别技术已广泛应用在日常生活中,我们需要在这两个选择之间找到某种平衡。
-
TINA虚拟示波器看不到输出波形是为什么?2024-08-14 468
-
为什么发表的帖子有些是看不到的呢!2011-09-29 2509
-
为什么我看不到别人的回复啊?2013-03-06 2563
-
CIS Exploror里面看不到元件2013-04-02 4425
-
PROTLE导入DXF后看不到图档是怎么回事?2013-06-05 3838
-
cam350导入allegro16.5光绘时丝印文字看不到,钻孔表也看不到2014-11-20 11104
-
place_BOUND_TOP的网格怎么看不到了2015-01-13 10917
-
为什么示波器看不到完整波形?2016-04-18 26973
-
pads软件下面菜单看不到2019-03-22 2340
-
请问在PCB布线中,把一根线拉到看不到区域该怎么删除呢?2019-06-05 3470
-
为什么我画pcb板子的时候看不到线的轨迹 ?2019-09-24 6913
-
php setcookie浏览器中看不到的问题有哪些?2020-06-19 2870
-
串口看不到接收的数字是为什么?2021-09-30 1802
-
为什么Allegro调入网络表后看不到元器件2008-03-22 5538
-
特斯拉的驾驶系统看不到消防车?2018-01-29 4222
全部0条评论

快来发表一下你的评论吧 !
