

斯坦福大学研究人员就试图通过大型视频集来识别、表示和生成人与物体间的真实交互
电子说
描述
现代机器人技术在运动类任务上的表现已经很惊艳,比如搬运重物、雪地行走等,但对于人和目标的交互式任务,比如餐桌摆盘、装饰房间等多半还无能为力。近日,斯坦福大学研究人员就试图通过大型视频集来识别、表示和生成人与物体间的真实交互。
近几年来,虚拟现实(VR)和机器人平台技术已经取得了巨大进步。这些平台现在可以让我们体验更加身临其境的虚拟世界,让机器人帮我们完成具有挑战性的运动类任务,例如在雪中行走,搬运重物等。那么,我们能否很快就能拥有可以会摆放餐桌、会做菜的机器人了呢?
很遗憾,这个目标现在离我们还有点远。
在日常生活中人与物体发生相互作用的一些例子
为什么?要弄清这个问题,需要从日常人类生活中的相互作用的多样性说起。我们几乎无时无刻不在进行活动,这些活动中包括简单的动作,比如吃水果,或更复杂一些的,比如做饭。这些活动中都会发生人和周围事物的相互作用,这个过程是多步的,会受到物理学、人类目标,日常习惯和生物力学的支配。
为了开发更具动态性的虚拟世界和更智能的机器人,我们需要教机器捕获,理解和复制这些交互行为。我们可以以大型视频集(如YouTube,Netflix,Facebook)的形式,广泛提供了解这些交互所需的信息。
本文将描述从视频中学习人与对象的多级交互活动所采取的一些初级步骤。主要讨论生成适用于VR/ AR技术的人与对象交互动画,研究如何使机器人能巧妙地对用户行为和交互作出反应。
问题和挑战
我们将研究重点放在人类进行的各种交互活动的子集上,常见的如家用桌上或办公室中的人与物体的交互,比如用手拿取桌子上的目标。下图中类似的桌面交互活动占到我们日常行为中的很大一部分,但由于手-物体的配置空间很大,因此这些交互活动的模式和特征难以捕获。
上图是我们收集的视频中的一些桌面交互活动实例。我们收集了75个视频(20个验证视频)。
我们的目标是通过学习大型视频集来识别、表示和生成这些真实的交互。这必须要解决具有挑战性的基于视觉的识别任务,产生与当前和过去的环境状态一致、时间空间一致的多步交互。这些交互还应符合基本物理定律(比如不能穿透物体),人类习惯(比如不能端着带杯柄的咖啡杯),并受到人体生物力学特征的限制(比如够不到太远的物体)。
动作划分(Action Plots)表示
人类活动的空间及其支持的相互作用存在无数可能。与对象的交互会导致连续的时空上的转换,使交互模式难以形式化。不过,这些复杂的相互作用可以按照顺序进行建模,即总结出从给定状态到后续状态的变化概率。
为了在这个顺序模型中进行参数化表示,我们引入了一个称为动作划分(action plot)的表示,负责表示由手完成的、导致场景中的状态发生改变的一系列动作。每个动作定义交互中的唯一阶段,并表示为动作元组,每个动作元组由动作标签、持续时间、参与对象、结束状态和位置组成。这种离散化处理方式更加突出了人与物体相互作用的组合性质,同时抽象出时空变换的复杂度。
从视频中识别人与物体的交互
学习生成包含多步骤交互行为的动作划分,捕捉现实世界中人和物体交互行为的物理约束和因果关系。我们的目标是从人类场景交互的视频集合中进行自动学习,因为这是一种快速,廉价、多功能的设置。为了完全表示动作划分,需要首先获取有关对象的实例、类别和位置,然后确定手的位置,最后进行动作检测和分割,这些信息都要从视频中提取,难度很大。
我们通过自动化的pipeline,利用计算机视觉领域的最新进展,在动作划分任务上实现了最高的精度。
对象和实例跟踪:动作划分中的一个重要组成部分是对象类别、实例、位置和状态。我们使用基于更快的R-CNN架构的物体检测器来在每帧图像中找到候选边界框和标签和对象位置,通过时间滤波减少检测抖动。为了推断对象的状态,在每个边界框的内容上训练分类器。
手部检测:由于大多数交互涉及手部,因此图像处理目的是推断出手在操纵哪些物体,以及手部遮挡时的物体位置。我们使用完全卷积神经网络(FCN)架构来检测手部动作。该网络使用来自GTEA数据集中的手工掩模的数据进行训练,并根据我们视频集的子集进行微调。通过手部检测和物体的运动方式,可以推断出手的实时状态(是空闲,还是被占用),这是一个重要的信息。
动作划分:要为每个视频帧生成动作标签,我们需要识别所涉及的动作以及它们的开始和结束时间(即动作分段)。我们采用两阶段方法:(1)为每帧图像提取有意义的图像特征,(2)利用提取的特征对每帧的动作标签进行分类,并对动作进行分段划分。为了增加动作划分的鲁棒性,使用LSTM网络来暂时聚合信息。详细信请参阅论文。
使用递归神经网络生成
利用上文中描述的动作划分表示可以对复杂的时空交互进行紧凑编码,第2部分中的识别系统可以利用视频创建动作划分。现在的目标是使用视频集合中提取的动作图来学习生成新的交互。为了使问题易于处理,我们将动作元组中的时变和时不变参数进行解耦处理,更具体地说,是使用多对多RNN来建模,并利用与时间无关的高斯混合模型。
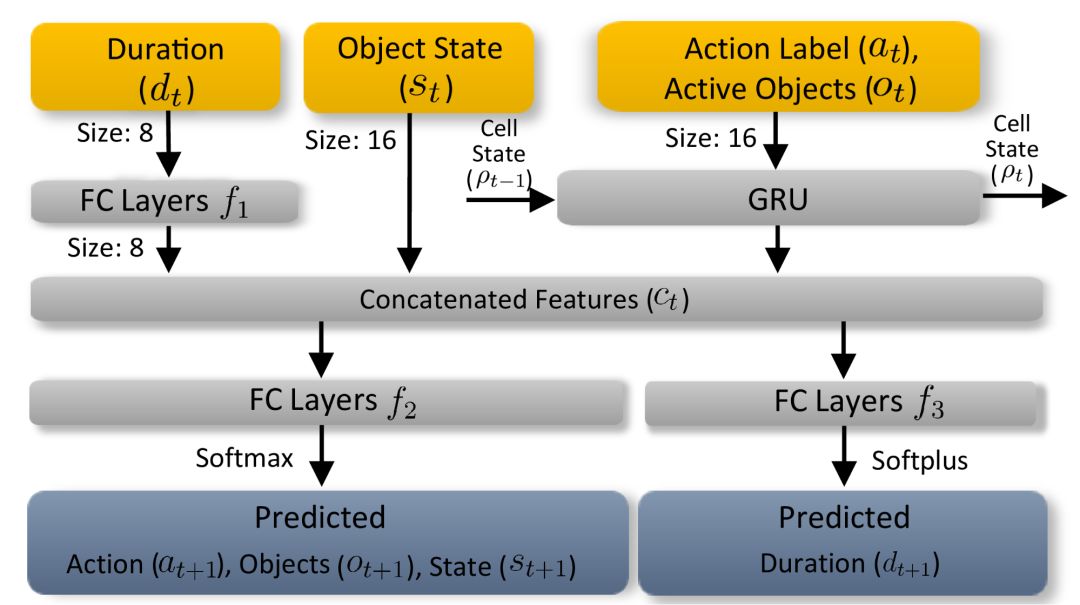
时间依赖性动作分割RNN:从自然语言处理中的类似序列问题中汲取灵感,使用状态保持递归神经网络(RNN)来模拟交互事件中与时间相关的参数。
动作分割RNN会学习并预测包括动作标签、活动对象,对象状态和持续时间组成的下一状态。每个时间步长上的输入会首先嵌入到指定大小的向量中。
与时间无关的物体位置模型:人和物体之间的许多相互作用需要通过建模,生成新的合理物体运动。物体的分布存在强烈的先验性特征。比如在杯子周围存在打开的瓶子是很常见的,但在笔记本电脑周围就很少见。由于这些先验性特征对时间因素的依赖性不高,我们可以利用高斯混合模型(GMM)对视频集合进行学习,并进行建模。
与时间无关的对象位置模型的学习和建模。此图为从视频集合中学习的可能对象位置的热图。
结果与应用实例
动画合成:我们的方法可以学习单个动作的前后因果依赖性,所以可用于生成在训练期间未见过的新的动作图像,并将这些动作图渲染成逼真的动画,如下图所示。利用这一点可以产生虚拟/增强现实领域的新应用,向人们传授新技能(比如冲咖啡)。
机器人仿真和运动规划:可以在智能和反应环境中启用应用,改善老年人和残疾人的生活。我们开发了带差动驱动器的机器杯。杯子的动作由实时识别、表示和生成pipeline驱动。杯子可以实时捕获交互并编码为动作图像,预测可能的未来状态。机器人使用这些预测来做出适当的反应。
下图中的“召唤杯”显示出用手抓杯子的过程。智能杯子会朝人手的方向移动,以防用户伸手够不到。但是,如果检测到用户的手中之前已经拿了一本书,智能杯就不会移动,因为我们的方法隐式学会了“一次只让手拿住一个物体”的物理约束。
“召唤杯”表现出了手、智能杯子和瓶子之间更复杂相互作用的实例。当手去移动装满的瓶子时,智能杯自动定位以便手将瓶中的水倒进杯里。但是,当检测到瓶子是空的时,智能杯不会做出反应。只有掌握复杂的人和对象之间的交互特征,才能实现这种语义规划。
讨论与未来方向
本研究是识别、表示和生成合理的动态人与对象交互过程的第一步。我们提出了一种方法,通过识别视频中的交互过程,使用动作划分紧凑地表示出这些交互,并生成新的交互,从而自动学习视频集合中的交互。虽然我们已经取得了很大的成果,但仍有一些明显的局限性。
我们用以进行动作划分的RNN无法捕获的长时间范围内的活动。目前的应用也仅限于桌上的交互式任务。在未来,我们计划将研究范围扩展至长期的交互活动上,并改善我们生成的交互的合理性。
我们的方法为学习生成人与对象的交互活动提供了坚实的基础。但是要想创建更具沉浸感和动态的虚拟现实,还需要进行广泛的研究,将来我们也许可以构建会做晚餐、会洗碗的机器人。
本研究的论文将于2019年 Eurographics会议上发表。
-
斯坦福大学研发全新AI辅助全息成像技术2024-05-10 1247
-
斯坦福大学开发触感VR能真实感受虚拟世界2019-06-18 3538
-
斯坦福大学开启新项目 寻找Apple Watch的健康新用途2017-01-19 1040
-
斯坦福大学公开课:编程方法学-作业52016-12-14 631
-
斯坦福开发过热自动断电电池2016-01-12 2794
全部0条评论

快来发表一下你的评论吧 !
