

谷歌AI推出端到端纯语音翻译技术,有望成为未来的“机器同传”
人工智能
描述
谷歌AI推出端到端纯语音翻译技术,有望成为未来的“机器同传”
我们先来听一下三段语音:
三段语音说的是同一句话:“你好,我是 Guillermo,你怎么样?(How's it going, hey, this is Guillermo. How are you?)”
只不过第一段是西班牙语原声(Qué tal, eh, yo soy Guillermo, ?Cómo estás?),第二段是标准的人类英语翻译,而第三段则是AI合成的英语翻译,来自于谷歌 AI 最新的语音翻译模型 Translatotron。
该模型是一个基于注意力机制(Attention)的端到端语音翻译神经网络。它不同于传统语音翻译技术,在翻译的过程中省略了中间步骤,完全不需要进行语音转文字和完成翻译的文字转语音,而是根据翻译内容,尝试匹配不同语言的语音频谱图(speech spectrogram),直接完成语音之间的转换。
换句话说,我们刚才听到的第一段西班牙语和第三段英语片段,AI在翻译的过程中,没有使用到任何语音转文字的技术,也没有使用西班牙语和英语的文字翻译技术,只有纯粹的语音转换。
虽然从翻译的准确率来看,Translatotron 模型还比不过传统翻译技术,但这种端到端的联合优化思路确实打破了主流语音翻译技术的基本原理,具有很强的启发性和拓展性。
目前谷歌只使用了西班牙语和英语语音作为概念验证,研究成果以预印本的形式发表在 Arxiv 和谷歌 AI 博客上。
打破常规思路
不同语言之间的语音转文字和翻译,是近年来机器学习领域的热门研究方向,尤其是语音到语音的直接翻译。
通常来讲,语音翻译过程可以分解成三个步骤。
第一步是语音识别,就是将英文语音内容识别出来,并且以文字的形式表达出来,比如听到“How are you?”这句话,就写出 How,are,you 三个单词和问号。
第二步是文字翻译,就是将上一步拿到的文字翻译成目标语种,比如写出“你好吗?”这句话。
最后一步是语音合成,也就是将翻译好的文本组合成一段语音,然后播放出来。
图 | 不同模型从西班牙语到英语的语音翻译对比
谷歌翻译等当下常见的语音翻译软件都遵循了这一思路,并且对每一步骤进行了很多优化,比如引入端到端模型(End-to-end model)。这是一种将三个步骤结合起来,比如建立语音信号到文字映射,进而实现整体优化的模式。
在谷歌研究人员看来,他们提出的 Translatotron,是之前很多端到端研究成果的进一步延伸,可以直接抛弃文字翻译这一中间步骤,成功在神经网络的帮助下,实现了不同语言语音片段的直接转换。
他们使用的是一套序列到序列模型(Sequence-to-sequence model),即训练 AI 将有关联的连续数据视为一段整体(英文句子),然后直接转化为另一段不同的整体(中文句子)。
在 Translatotron 中,研究人员选择了语音片段的频谱图作为序列,上面描述了语音频率随时间变化的热图。它们会作为输入值进入到神经网络中,随后经过8层堆叠双向长短时记忆网络(BLSTM)编码器,频谱与自动语音识别特征结合,多头注意力和频谱解码器等多个模块,完成对语音频谱特征的提取,转换和生成等任务。
经过上述一系列转换后,西班牙语语音频谱就变成了对应的英语语音频谱,最后可以通过声码器(vocoder)合成我们听到的语音。如果需要的话,还可以使用额外预训练好的 Speaker 编码器捕捉语音源的声音特点,添加到合成语音当中,让两者听起来更加相似。
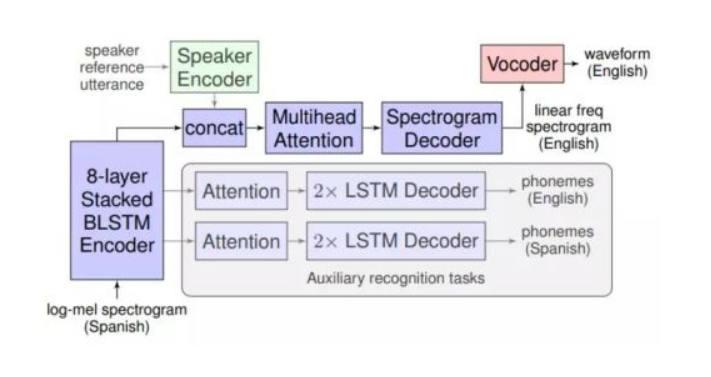
在训练过程中,Translatotron还使用了多任务学习技巧(multitask learning),引入了四个长短时记忆网络解码器。
上图的辅助识别任务区域(Auxiliary recognition tasks)就是负责在生成目标语种频谱图的同时,也顺便学习一下如何预测语音的因素和文字内容。只不过它们没有被用来进行推理,否则就不是纯语音翻译了。
为了测试翻译质量,研究人员使用了机器翻译评估算法 BLEU,最好成绩达到了基准表现的76%。
他们认为,这一成绩虽然不及主流的传统语音翻译技术,但 Translatotron 作为一个概念验证,足以证明抛弃机器翻译和文字转换的思路行得通,而且可能还在还原音色等方面拥有更大的潜力。
下一步,谷歌团队将尝试降低训练过程中的监督水平,扩大合成数据和多任务学习的规模,并且探索其他可以转移的声音元素,改善合成语音的质量。
不得不说,直接在不同语言之间转换音频的想法还是很有创意的,而且极富挑战性,对特征提取质量,语音频谱绘制和噪声抵抗能力提出了更高的要求,足以启发其他团队,成为一个新的研究方向。
- 相关推荐
- 热点推荐
- AI
-
科大讯飞卷入“AI同传造假”,谷歌实时翻译也遭吐槽2018-10-25 3721
-
机器翻译三大核心技术原理 | AI知识科普2018-07-06 7301
-
AI同传,首次登上国际级会议的舞台2018-04-12 7873
-
被人质疑的“AI同传”翻译效果究竟如何?2018-09-25 3918
-
智能同传翻译离我们还有多远2018-11-05 1032
-
谷歌推出端到端语音翻译技术,让优质高效的机器翻译不再遥遥无期2019-05-17 3910
-
真人和AI竞技 人工智能会取代同传吗?2019-07-04 586
-
一种基于端到端基于语音的对话代理2020-09-09 2452
-
远程云同传系统 人工同传翻译方案商 上海安睿杰翻译公司2022-07-01 2379
-
语音识别技术:端到端的挑战与解决方案2023-10-18 2347
-
中兴通讯推出基于AI驱动的全新端到端网络解决方案2025-03-05 1755
-
从矢量降噪到双向同传,时空壶 W4Pro 如何重构 AI 同传技术标准?2025-06-05 1159
-
时空壶凭 L3 级 AI 同传技术领航行业,未来蓝图初见端倪2025-06-16 1112
-
当经典IP撞上AI技术:利尔达助力跃然创新推出全球首款端到端AI互动玩具2025-08-26 2194
-
腾讯会议推出“AI同传”功能2026-05-25 919
全部0条评论

快来发表一下你的评论吧 !
