

阿里巴巴如何使用分布式存储技术
存储技术
描述
2018年12月12日,2018中国存储与数据峰会的闪存存储与应用论坛上,阿里巴巴资深技术专家石超介绍了阿里巴巴在分布式存储方面的技术积累,一方面服务于阿里巴巴自己的电商业务,一方面以阿里云的方式向外界提供服务。
阿里巴巴做存储可能跟其他公司不太一样,我们真的做了一个存储平台,把各个业务统一起来,然后用同一套系统去支持这个业务。十年前我们开始做这个系统,随后在2010年、2011年我们基于盘古系统发布了公有云的产品,像大数据的ODPS、ECS,还有我们的对象存储OSS服务。
在2013年有一个关键事件——阿里巴巴的飞天5K项目落成。同一时代在阿里内部还有其他的存储系统在用,还有云梯1和云梯2系统,2013年把这两个系统合并了,这是离线大数据上的标志性事件。2016年,盘古2.0项目启动等等。
阿里巴巴可能和其他做云产品的公司不一样,对于我们来说,我们做这些新的技术,并不是让大家去做小白鼠,阿里巴巴自己内部关键的电商业务也是跑在同一套系统上。
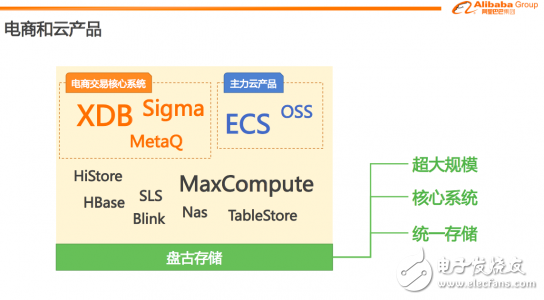
比如电商交易的核心系统,比如双11和双12,大家在淘宝上下单,淘宝的数据库、消息界面系统,都是由同一套系统来支撑的。我们的主力云产品包括ECS和OSS的存储,也都是在我们的系统上。对于统一存储,我觉得有几个关键的业务特点:
第一,我们的规模非常大,应该说阿里集团大部分的数据都在这个系统上。
第二,我们支持了非常核心的系统,内部系统会和外部系统业务稍微有一些区别。
一方面,比如我们的业务系统的分布式架构做的很好,因为它要面对双11的冲击,所以,要求系统能够在短时间内承受非常高的流量冲击,需要你的系统有非常好的弹性。
一方面,云产品又稍微有点不一样,云产品面对的是很多架构上没有那么好的公司,比如创业公司,他们的架构比较简单,但是对我们单个存储或者单个OSS的可用性要求非常高,所以这两个需求又有点不一样。
同时受到这两方面的驱动,我们做统一的存储,用统一的技术服务这两种类型的应用。
为什么我们去用分布式存储解决这些问题?
我讲一个实践例子,讲一个今年我们用存储技术支持双11大促的例子。
上图,今年双11零点高峰期,数据库对于分布式存储的读写的图,我们可以看到零点是一个标志,到了0点之后流量开始上来了,到了0点30分流量开始下跌,是和之前差不多的情况。
所以,电商面临这样一个场景,我们到底要准备多少台机器去撑这个高峰,如果我们准备了很多机器去满足这个流量,那么这个流量只持续个把小时,那么这就是一种浪费。

所以,阿里在这两三年一直在做一个叫做混部的技术,具体来说我们有很多应用服务器是跑在线的业务,有另一些应用服务器跑离线的业务。一般公司的做法都是在线业务比如数据库、Web服务器都是延时敏感的业务,不能和离线业务放在一起。但是在阿里来说,面对电商双11我们需要一个非常有弹性的系统,这两年为了应对双11,我们能够把离线业务的机器让出来,让它去跑在线应用,等双11这个高峰过去之后在线的应用可以缩回来,让离线的业务利用在线的机器完成自己的工程。
这样一件事有很多挑战,对于存储来说意味着什么?挑战在哪里?
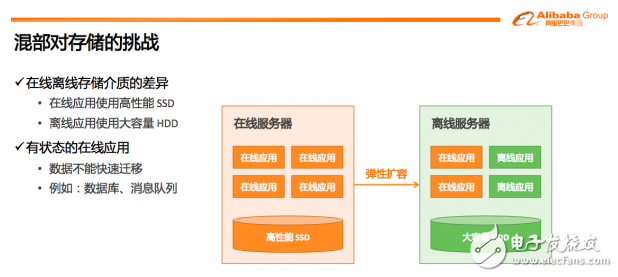
我觉得有两点:一个是在线应用和离线应用对于存储要求完全不一样。在线应用现在SSD可以做到几十微秒的延迟,离线应用只要吞吐大、容量大就好。
有一些应用是没有状态的,比如跑一个Web服务器,它在本地存储的数据就是它的程序文件,运行时它可能有一些文件缓存,程序运行起来可能会打日志,这些东西都是当程序从一个机器迁到另一台机器做扩展时可以丢掉的,是可以重新从远程拉起来的。
另一些程序是有状态的,比如说数据库,数据库在本地有它的数据,消息队列有它的数据文件,如果要做扩展,你需要把这个数据迁移到另一台机器,过程很耗时,并且没有什么弹性,你需要事先准备很长时间。这两点使得我们在做混部时,对存储提出了很大挑战。
怎么解决这个问题呢?
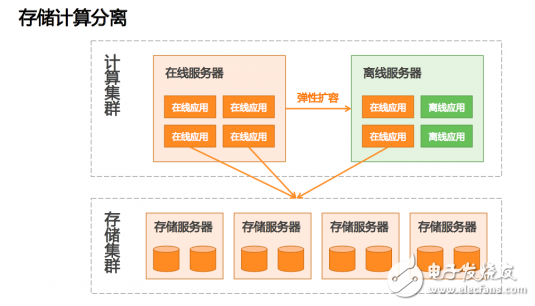
我们有一个概念叫做存储和计算分离。老话说30年河西30年河东,以前用企业存储天然就是存储和计算分离,现在我们又回到了这样一个架构。我们的在线服务器也不去写本地的盘,单独搭一个存储的机器,把这些机器分成存储和计算两种,存储专门放数据,上面不跑业务。计算上面跑业务,用计算节点的CPU资源、内存,但是它不去写本地的盘。这样高峰到来,我们很轻松地把一些计算任务从一个计算的节点去弹性弹到离线的服务器上,峰值过去之后再缩回来。
有了存储和计算分离后,数据就不用写本地盘了,而是写到远程分布式存储,这对于分布式存储来说不太容易做到,但还好,随着业界技术的进步,我们有了高性能的网络和闪存,分布式存储在一些方面上做的并不比本地的盘差,甚至在某些方面做的更好。
具体在哪些地方比较好呢?
首先,可靠性来说,分布式存储天然就在做机器之间的冗余,可以打造更好的可靠性。
从性能来说,我们用了一些比较新的技术,用户态的一些技术,能够使分布式存储和本地的盘达到差不多的水平,同时,因为分布式存储后台是一个大的资源池,对于特定的应用,比如说当IO集中在一块盘上或者几块盘上,小部分的盘的时候,可以利用更多的机器来完成这个。在这种场景下,会比本地的盘更好。
成本方面也有弹性,当你去用本地盘的时候,你会面临容量规划的问题,可能1%的情况下,某个程序有问题把盘用满了,可能会引起整个系统的崩溃。在分布式存储的情况下,它是一个资源池,容量规划的时候更简单。可以把不同用户的盘,放在一个大的池子里,这样一来,空闲的空间就会比较少。
我挑几点详细介绍一下。
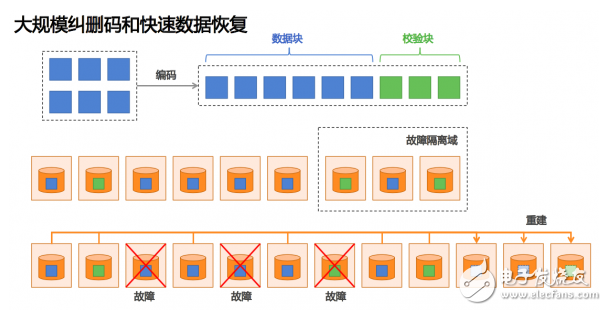
第一点,当我们做大规模纠删码的实践,在传统存储对应的就是做Raid的纠删码,但是Raid给人的印象是,这个东西比较慢,恢复的比较慢,恢复的过程会有损等等。当你把这个问题放在跨机器的集群很多事会变得比较好办。我们可以跨机器去做纠删码,我们可以跨网络交换机做纠删码,甚至跨可用区做纠删码。我们会找一个城市,找三个地方,在三个地方之间搭机房,用比较快的网络。可以把一部分数据做纠删码,分在三个地方。
做纠删码的时候可以用更多的数据块等等把这个做的更安全。我们线上基本采用的都是N+3,任何三块盘死机我都不损失数据。同时因为池子变大了,所以,我们是在几百、几千台机器的规模上去做纠删码。当你一个节点死机的时候,我会有成百上千的机器做恢复,所以,可以解决传统阵列恢复时间慢、有损的问题。
下面讲分布式存储的可靠性给业务带来什么。
我们知道,在阿里自己的业务和云不太一样,阿里自己的电商业务本身就是分布式的,是一个多地域、分布式的很多小应用组成的系统。为什么这个时候还需要做存储的分布式?以数据库为例,数据库非常有代表性,很多人首先觉得做分布式数据库很难,基于MySQL做存储计算分离也不太容易。
阿里在很多年之前就开始了去IOE进程,去IOE之后就走向了MySQL分库、分表的架构上。为什么做分库分表?这因为MySQL单机的性能是受限的,随着业务的增长必须用多台机器去做,与此同时,为了解决单机的可靠性、可用性的问题,MySQL还去做主备,当主死机以后可以马上切备库。同时在MySQL用本地盘的时候,还会给盘做Raid,进一步增加盘的可靠性。转到分布式存储之后,其实它解决的是数据可靠性问题,但是并没有解决业务的可用性问题。
在业务层和存储层,大家各司其职去扩展。存储层专注于解决数据本身的高可靠、高可用问题。而MySQL应用层,专注解决事物处理、扩展一致性的问题。
通常认为分布式存储是要走网络,传统本地存储是直接用PCIe这样的高速连接去连到存储,分布式存储然的弱点就是接入网络,分布式存储因为数据要写多份,要跨故障率去写多份,网络的链路就会更长。
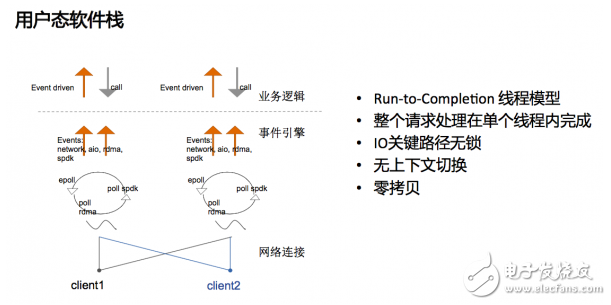
得益于现在用户态技术的发展,前面虽然分布式存储有很多好处,但是性能是一个硬的限制,一旦性能满足不了要求,前面各种优势,在业务方面都没有体现。
具体来说,我们用用户的软件栈做的事情就是采用Run-to-Completion的线程模型,这个过程中单机内部没有线程切换,没有锁、没有口,我们把这些东西都去掉了,能够达到非常好的性能。
同时因为分布式存储自身的特点,它是基于这些不稳定的硬件搭建出一个稳定的系统。
-
荣邦佳业有阿里巴巴啦2014-04-15 2540
-
2017双11技术揭秘—阿里巴巴数据库技术架构演进2018-01-02 2712
-
《阿里巴巴Android开发手册》正式发布,献给移动开发者的新年礼物2018-02-28 3440
-
阿里巴巴敏捷研发的探索与实践2018-03-07 4147
-
阿里巴巴大数据实践之数据建模2018-03-14 3120
-
微服务架构下分布式事务解决方案 —— 阿里GTS2018-03-16 6050
-
新增16条设计规约!阿里巴巴Java开发手册(详尽版)开放下载!2018-06-06 3117
-
支持Dubbo生态发展,阿里巴巴启动新的开源项目 Nacos2018-07-05 3848
-
基于分布式调用链监控技术的全息排查功能2018-08-07 3177
-
国内芯片—阿里巴巴的人工智能实力2018-09-27 4615
-
详解阿里巴巴智能对话开发平台2019-07-31 3206
-
哪里可以下载阿里巴巴的地方和链接?2019-11-04 3254
-
阿里巴巴无线空口提案正式成为LoRa国际标准2019-12-13 2613
-
阿里巴巴持续投入,etcd 正式加入 CNCF2018-12-20 317
-
阿里巴巴探讨新基建下数字经济分布式存储新机遇2020-08-17 3674
全部0条评论

快来发表一下你的评论吧 !
