

谷歌:半监督学习其实正在悄然的进化
电子说
描述
谷歌首席科学家提出要想让半监督学习实际上有用,要同时考虑低维数据和高维数据,并讨论了谷歌最近的两个研究。作者认为在实际环境中重新审视半监督学习的价值是一个激动人心的时刻。
作为一个机器学习工程师,可能平时最常打交道的就是海量数据了。这些数据只有少部分是有标注的,可以用来进行监督学习。但另外一大部分的数据是没有标注过的。
那么接下来,我们就会顺理成章的想到用这些已标注过的数据进行训练,再利用训练好的学习器找出未标注数据中,对性能改善最大的数据,让机器自己的对未标注数据进行分析来提高泛化性能,
这种介于监督学习和无监督学习之间的方式,称为半监督学习。人类的学习方法是半监督学习,我们能从大量的未标注数据和极少量的标注数据学习,迅速理解这个世界。
然而半监督学习实践中根本没用?
人类的半监督学习非常有效,那么我们自然的希望机器的半监督学习也能达到类似的程度。但是从历史上来看,半监督学习的效果和我们想象的效果有很大差距。先来看一张图:
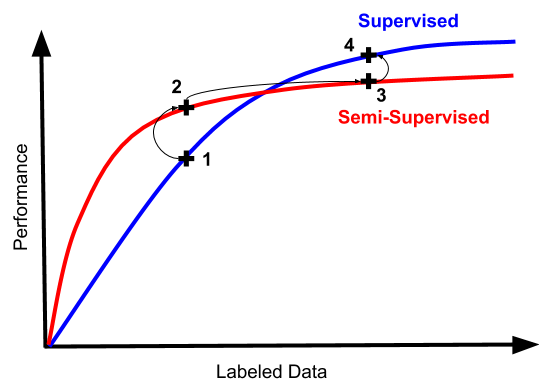
上图可以看出来,最开始的时候,半监督学习训练确实有种提升监督学习效果的趋势,然而实际操作中,我们经常陷入从“可怕又不可用”的状态,到“不那么可怕但仍然完全不可用”。
如果你突然发现你的半监督学习起效了,这意味着你的分类器单纯的不行,单纯的没有实际用处。
而且面对大量的数据,半监督学习方式通常不能实现和监督学习中所实现的相同渐近性质,未标注的数据可能会引入偏差。
举个例子,在深度学习的早期阶段,一种非常流行的半监督学习方法是首先学习一个关于未标注数据的自动编码器,然后对标注数据进行微调。
现在几乎没人这么做了。因为通过自动编码学习的表示,倾向于在经验上限制微调的渐近性能。
而且,即使是已经突飞猛进的现代生成方法,也没有对此状况有多大的改善。可能因为提升生成模型效果的元素,并不能很有效的提升分类器的效果。
当你在今天看到机器学习工程师对模型进行微调时,基本都是从从监督数据上学习的表示开始。而且文本是用于语言建模目的的自监督数据。
最终我们得出一个结论:实际情况下,从其他预训练模型进行转移学习是一个更稳健的起点,在这方面半监督方法难以超越。
所以,一位机器学习工程师在半监督学习的沼泽中艰难前行的典型路径如下:
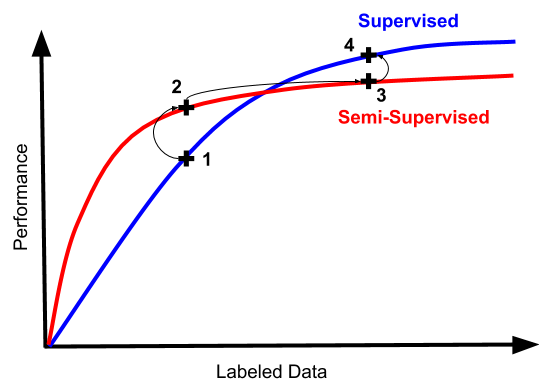
一切都很糟糕,让我们尝试半监督学习吧!(毕竟这是工程工作,比标注数据这种纯体力活可有意思多了)
看,数字上去了!但是仍然很糟糕。看起来我们还是得去搞标注数据...
数据越多,效果越好。但是你有没有尝试过丢弃半监督机器会发生什么?
嘿你知道吗,它实际上更简单更好。我们可以通过完全跳过2和3来节省时间和大量技术债
如果你走运的话,你的问题也可能具有这样的性能特征:
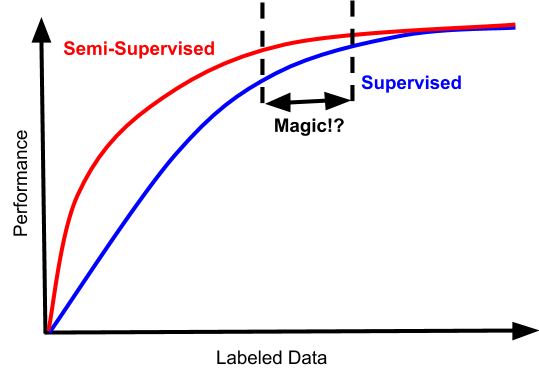
巧了,在这种情况下,存在一种狭窄的数据体系。半监督学习在其中不仅不糟糕,而且还实实在在的提高了数据效率。
但是根据过来人的经验来看,这个点很难找到。考虑到额外复杂性的成本,标注数据量之间的鸿沟,通常不会带来多大的效果,并且收益递减,所以根本不值当浪费精力在这个上面,除非你想在这个领域竞争学术基准。
半监督学习其实正在悄然的进化
说了这么多半监督学习的弱项。其实本文真正想讲的是在半监督学习领域,一直在悄悄发生的进化。
一个引人入胜的趋势是,半监督学习的可能会变成看起来更像这样的东西:
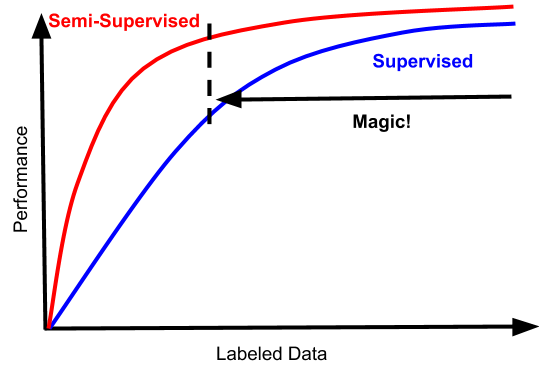
这将改变所有目前半监督学习领域的难题。
这些曲线符合我们理想中的半监督方法的情况:数据越多越好。半监督学习和监督学习之间的差距,也应该是严格成正比的,即使是监督学习表现的很好的领域,半监督学习也应该能表现的很好。
而且这种效果的提升伴随着的是成本的稳定,以及很少量的额外复杂性。图中的“magic区域”从更低的地方开始,同样重要的是,它不受高数据制度的束缚。
其他一些新的发展包括:有更好的方式进行自我标注数据,并以这样的方式表达损失,即它们与噪声和自我标注的潜在偏差兼容。
最近有两篇论文讲述了半监督学习最近的进展。
MixMatch: A Holistic Approach to Semi-Supervised Learning
论文地址:
https://arxiv.org/abs/1905.02249
Mixmatch是本文中提出的新方法,它巧妙地结合了以前单独使用的3种SSL范例。
一致性正则化:通过增加标记和未标记的数据输入来引入
熵最小化:锐化函数减少了未标记数据的猜测标签中的熵
传统正则化: MixUp引入了数据点之间的线性关系

在每个batch中,每个标记的数据点被增强一次,并且每个未标记的数据点被增加K(超参数)时间。要求该模型预测所有K个增广条目(L类的概率),并将它们的平均值作为所有K个条目的预测。
锐化该平均值以最小化熵并将其作为最终预测。将增强的标记和未标记的数据连接并混洗以获得W.batch中的标记数据与第一个|X|“混合”。 W的条目得到X',其中|X|是batch中标记数据的大小。batch中的未标记数据与W的其余条目“混合”以获得U'。
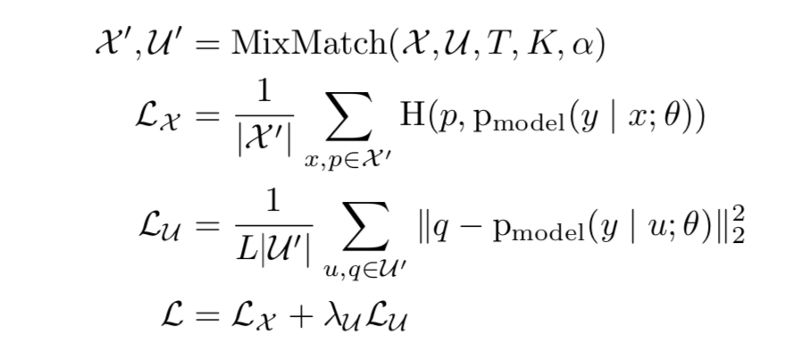
MixMatch算法结合了不同的SSL范例,通过一个重要因素实现了比所有基线数据集上所有当前方法明显更好的性能。它确保了差异隐私的更好的准确性和隐私的权衡,因为需要比其他方法更少的数据来实现类似的性能。
Unsupervised Data Augmentation
论文地址
https://arxiv.org/abs/1904.12848
本文的重点是从(主要是启发式的,实用的)数据增强世界中为监督学习提供进展,并将其应用于无监督设置,作为在半监督环境中引入更好性能的一种方式(具有许多未标记点,以及很少标记的)。
论文中的无监督数据增强(UDA)策略注意到两件事:首先在监督学习领域,在生成增强数据方面存在特定于数据集的创新,这对于给定数据集特别有用。语言建模,这方面的一个例子是把一个句子翻译成另一种语言,并通过两个训练有素的翻译网络再次返回,并使用得到的句子作为输入。对于ImageNet,有一种称为AutoAugment的方法,它使用验证集上的强化学习来学习图像操作的策略(比如旋转,剪切,改变颜色),以提高验证的准确性。
(2)在半监督学习中,越来越倾向于使用一致性损失作为利用未标记数据的一种方式。一致性损失的基本思想是,即使不知道给定数据点的类,如果以某种很小的方式修改它,也可以确信模型的预测应该在数据点与其扰动之间保持一致,即使你并不知道实际的ground truth是什么。通常,这样的系统是在原始未标记图像的基础上使用简单的高斯噪声设计的。本文的关键提议是用更加简化的扰动程序替代在监督学习中迭代的增强方法,因为两者的目标几乎相同。
除了这个核心理念之外,UDA论文还提出了一个额外的聪明的训练策略:如果你有许多未标注的样本和少量标注的样本,你可能需要一个大型模型来捕获未标注样本中的信息,但这可能会导致过拟合。
为了避免这种情况,他们使用一种称为“训练信号退火”的方法,在训练中的每个点,他们从损失计算中删除模型特别有信心的任何样本,比如真实类别的预测高于某个阈值等。
随着培训的进行,网络逐渐被允许看到更多的训练信号。在这种框架中,模型不能轻易过度拟合,因为一旦它开始在受监督的例子上得到正确的答案,他们就会退出损失计算。
在实证结果方面,作者发现,在UDA中,他们能够通过极少数标记的例子来改进许多半监督基准。有一次,他们使用BERT模型作为基线,在其半监督训练之前以无人监督的方式进行微调,并表明他们的增强方法甚至可以在无人监督的预训练值之上增加价值。
例如,在IMDb文本分类数据集中,仅有20个标注样本,UDA优于在25000个标注样本上训练的最先进模型。
在标准的半监督学习基准测试中,CIFAR-10具有4,000个样本,SVHN具有1,000个样本,UDA优于所有先前的方法,并且降低了超过30%的最先进方法的错误率:从7.66%降至5.27%,以及从3.53%降至2.46%。
UDA也适用于具有大量标记数据的数据集。例如,在ImageNet上,使用130万额外的未标记数据,与AutoAugment相比,UDA将前1/前5精度从78.28/94.36%提高到79.04/94.45%。
半监督学习激动人心的未来
半监督学习的另一个基础转变,是大家认识到它可能在机器学习隐私中扮演非常重要的角色,例如Private Aggregation of Teacher Ensemble(PATE)。PATE框架通过仔细协调几种不同机器学习模型的行为来实现隐私学习。
用于提取知识的隐私敏感方法正在成为联合学习(Federated Learning)的关键推动者之一,联合学习提供了有效的分布式学习的方式,其不依赖于具有访问用户数据的模型,具有强大的数学隐私保证。
在实际环境中重新审视半监督学习的价值有点激动人心,这些进步将会导致机器学习工具架构有极大可能性发生根本转变。
-
使用MATLAB进行无监督学习2025-05-16 1811
-
跨解剖域自适应对比半监督学习方法解析2023-04-14 2376
-
半监督学习代码库存在的问题与挑战2022-10-18 2247
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5698
-
半监督学习:比监督学习做的更好2020-12-08 2385
-
为什么半监督学习是机器学习的未来?2020-11-27 4879
-
最基础的半监督学习2020-11-02 3596
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6891
-
Google AI最新研究用无监督数据增强推进半监督学习,取得令人瞩目的成果2019-07-13 4343
-
聚焦 | 新技术“红”不过十年?半监督学习却成例外?2019-06-18 3339
-
如何用Python进行无监督学习2019-01-21 5570
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 1067
-
基于半监督学习框架的识别算法2018-01-21 1103
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 1068
全部0条评论

快来发表一下你的评论吧 !
