

微软亚洲研究院视觉计算组提出高分辨率深度神经网络
电子说
描述
对于视觉识别中的区域层次和像素层次问题,分类网络(如ResNet、VGGNet等)学到的表征分辨率比较低,在此基础上恢复的高分辨率表征空间区分度仍然不够强,使其在对空间精度敏感的任务上很难取得准确的预测结果。为此,微软亚洲研究院视觉计算组提出高分辨率深度神经网络(HRNet),对网络结构做了基础性的改变,由传统的串行连接高低分辨率卷积,改成并行连接高低分辨率卷积,通过全程保持高分辨率和对高低分辨率表征的多次信息交换来学到丰富的高分辨率表征,在多个数据集的人体姿态估计任务中取得了最佳的性能。
前言
视觉识别主要包括三大类问题:图像层次(图像分类),区域层次(目标检测)和像素层次(比如图像分割、人体姿态估计和人脸对齐等)。最近几年,用于图像分类的卷积神经网络成为解决视觉识别问题的标准结构,比如图1所示的LeNet-5。这类网络的特点是学到的表征在空间分辨率上逐渐变小。我们认为分类网络并不适合区域层次和像素层次的问题,因为学到的表征本质上具有低分辨率的特点,在分辨率上的巨大损失使得其在对空间精度敏感的任务上很难取得准确的预测结果。
图1. 典型的卷积神经网络:LeNet-5。其它典型的卷积神经网络,如AlexNet、VGGNet、GoogleNet、ResNet、DenseNet等,表征的空间分辨率均从大逐渐变小。
为了弥补空间精度的损失,研究者们在分类卷积神经网络结构的基础上,通过引入上采样操作和/或组合空洞卷积减少降采样次数来提升表征的分辨率,典型的结构包括Hourglass、U-Net等(如图2)。
在这类网络结构中,最终的高分辨表征主要来源于两个部分:第一是原本的高分辨率表征,但是由于只经过了少量的卷积操作,其本身只能提供低层次的语义表达;第二是低分辨率表征通过上采样得到的高分辨率表征,其本身虽然拥有很好的语义表达能力,但是上采样本身并不能完整地弥补空间分辨率的损失。所以,最终输出的高分辨率表征所具有的空间敏感度并不高,很大程度上受限于语义表达力强的表征所对应的分辨率。
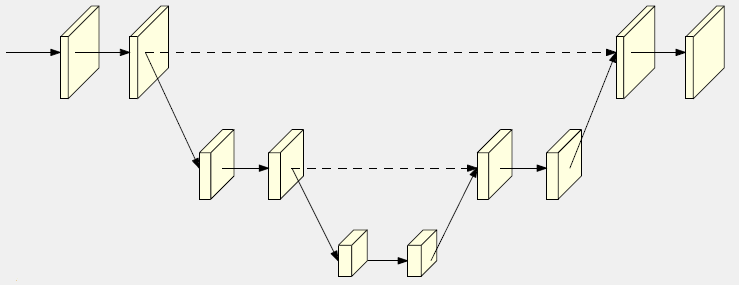
图2. 从低分辨率表征恢复高分辨率表征
我们认为不应该局限于从分类卷积神经网络生成的低分辨率表征来恢复高分辨率表征这一路线,而应该为高分辨率表征学习建立新的网络结构。基于此,我们提出了高分辨率深度神经网络(High-Resolution Network,HRNet),在网络整个过程中始终保持高分辨率表征,同时多次在高低分辨率表征之间进行信息交换,从而学到足够丰富的高分辨率表征。
实验证明HRNet在人体姿态估计,以及图像分割、人脸对齐和目标检测等问题上取得了不错的结果。我们相信HRNet将取代分类深度神经网络成为计算机视觉识别等应用的新的标准结构。关于人体姿态估计的论文已发表在CVPR 2019 [1],相关代码已在GitHub上开源[2, 3]。
GitHub链接:
https://github.com/HRNet
高分辨率网络
我们在HRNet的整个网络中始终保持高分辨率表征,逐步引入低分辨率卷积,并且将不同分辨率的卷积并行连接。同时,我们通过不断在多分辨率表征之间进行信息交换,来提升高分辨率和低分辨率表征的表达能力,让多分辨率表征之间更好地相互促进,结构如图3所示。HRNet与先前的分类卷积神经网络有着基础性的区别:先前的分类将分辨率从高到低的卷积串行连接,HRNet则是并行连接。
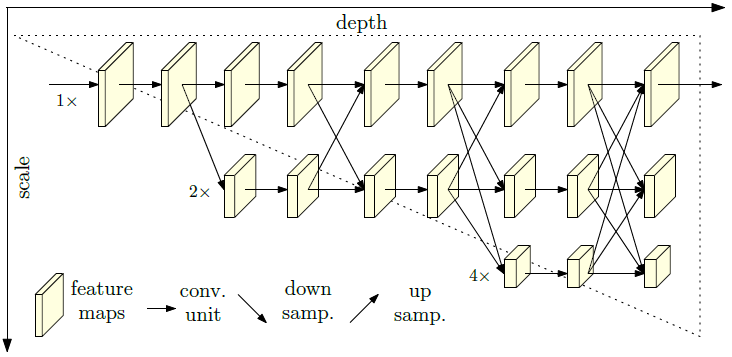
图3. 高分辨率网络 (High-Resolution Network,HRNet)
关于多分辨率表征信息交换,这里以三个分辨率输入和三个分辨率输出为例,如图4所示。每一个分辨率的输出表征都会融合三个分辨率输入的表征,以保证信息的充分利用和交互。将高分辨率特征降到低分辨率特征时,我们采用stride为2的3x3卷积;低分辨率特征到高分辨率特征时,先利用1x1卷积进行通道数的匹配,再利用最近邻插值的方式来提高分辨率。相同分辨率的表征则采用恒等映射的形式。
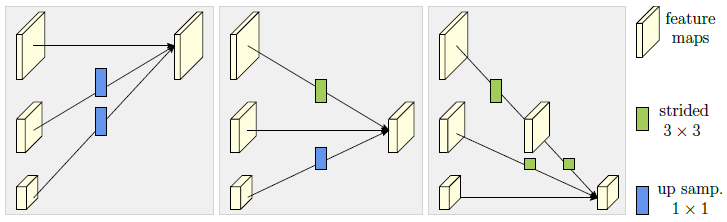
图4. 多分辨率表征信息交换
实验
HRNet保持高分辨率表征,利用重复的多分辨率表征信息交换增强其表达能力,使模型所学的表征在空间精度上有显著的提升。实验中,我们首先在MS COCO数据集中的关键点检测任务上进行了消融实验,验证了表征分辨率的重要性和重复的多分辨率表征信息交换的有效性;然后在MS COCO、PoseTrack等标准数据集中与最先进的方法进行公平对比,都取得了更好的性能。
1. 表征分辨率对性能的影响
HRNet可输出4种分辨率的表征(1x、2x、4x、以及8x),我们针对不同的网络输出分辨率在两组模型上做了对比实验,如图5所示。
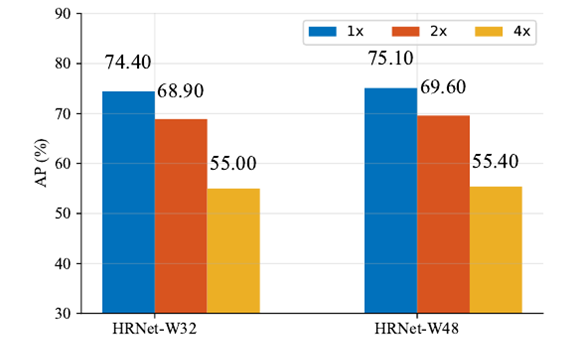
图5. 网络输出分辨率对结果的影响,1x、2x和4x分辨率表征在人体姿态估计的性能。
从图5中,我们可以清楚地看到,网络输出表征的分辨率降低会使得模型的性能有巨大的损失。分辨率在2x时,性能降低了接近6% AP,4x时降低了20% AP。这体现了表征分辨率对于空间精度的重要性。
2. 多分辨率表征信息交换对性能的影响
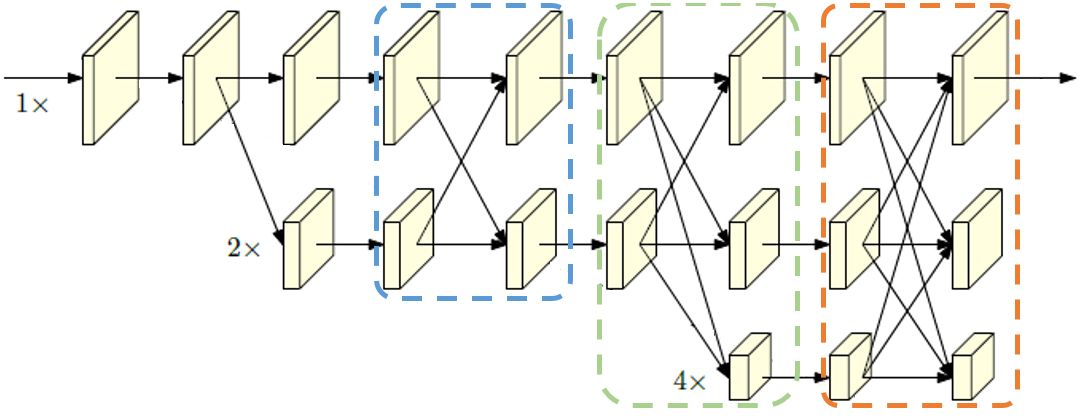
图6. 蓝色框内为阶段内的多分辨率表征信息交换(Int. exchange within),绿色框为阶段间的多分辨率表征信息交换(Int. exchange across),红色框为最终的多分辨率表征信息交换(Final exchange)。

表1. 多尺度特征融合对性能的影响,实验中每个网络是从随机初始化开始训练的。
我们考虑了三种信息交换(如图6),结果如表1。可以看到,多分辨率表征信息交换可以将不同分辨率的表征信息进行充分的交换利用,对表征增强的作用十分明显,可以到达2.6% AP的提升。
3. 在标准数据集上的性能
MS COCO数据集是关键点检测的最权威的数据集之一,我们在该数据上对我们的方法进行验证,结果如表2所示。
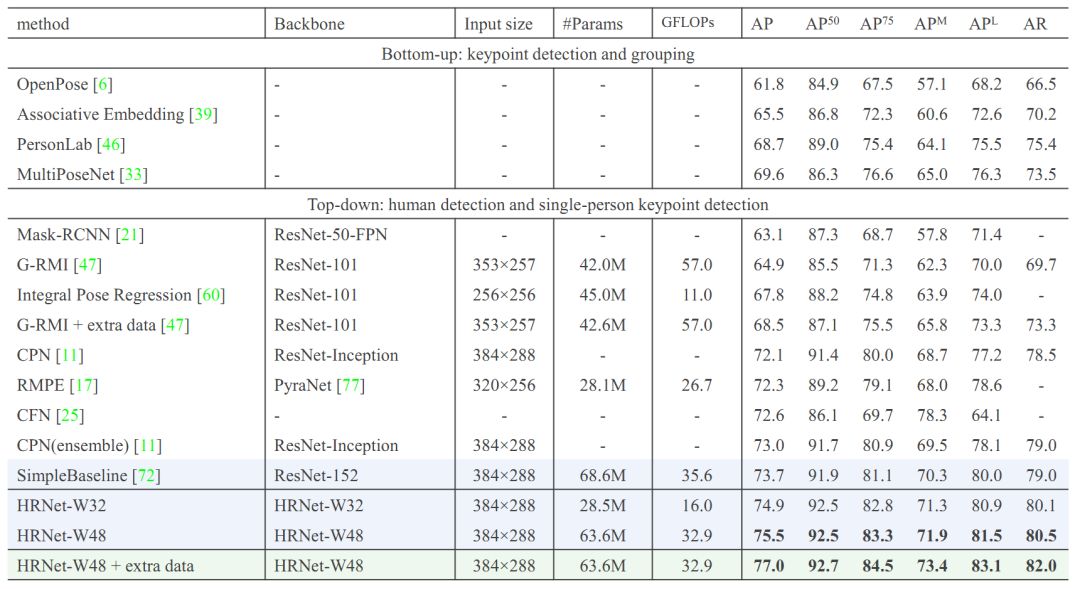
表2. COCO test-dev上与最先进方法的性能比较
我们可以看到,在相同的输入图像大小下,我们的小模型HRNet-W32在参数量和计算量都小于SimpleBaseline(ResNet-152)一半的情况下,取得了1.2% AP的提高,而大模型HRNet-W48取得了1.8% AP的提升,在引入额外数据的情况下,大模型展现了更强的表达能力,有更显著的提升。
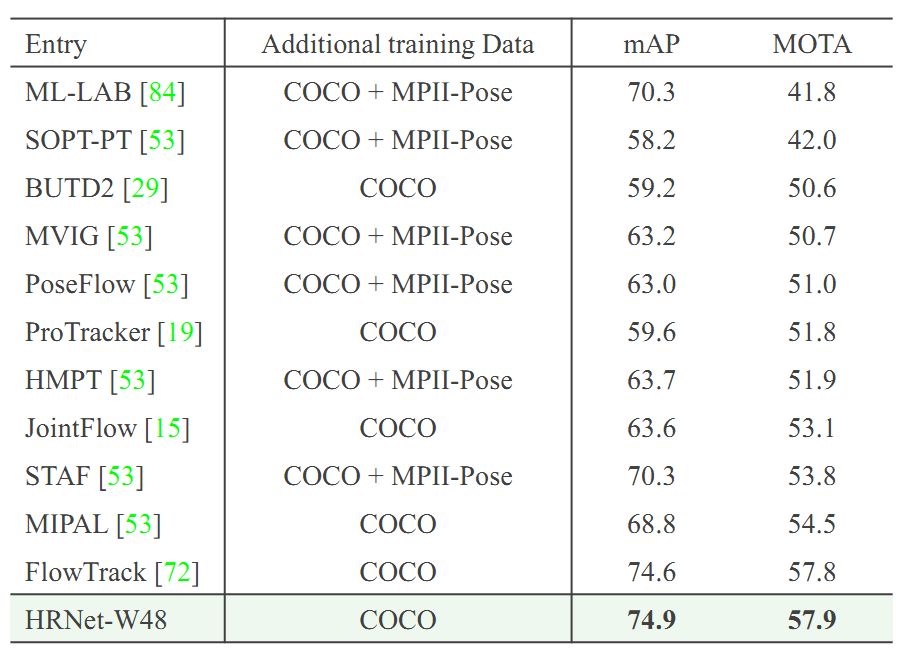
表3. 在Pose-Track数据集上与最先进方法的性能比较
在表3中,我们在Pose-Track数据集的两个任务上进行了验证:(1)多帧人体姿态估计,可以利用其他帧的信息估计某帧的姿态;(2)多帧人体姿态跟踪,需要把不同帧间的同一个人的姿态关联起来。前者性能用mAP来评价,后者性能用MOTA来评价。可以看到在两个任务上,我们都取得了最好的性能。
结语
我们改变了现有的基于分类网络的人体姿态估计的网络结构,提出了高分辨率深度神经网络(HRNet)。该网络能够成功学到足够丰富的高分辨率表征的原因在于,整个过程保持高分辨率,以及多次对高低分辨率表征进行信息补足。HRNet在多个数据集的人体姿态估计任务中取得了当前最好的性能,也在图像分割、人脸对齐和目标检测等问题上取得了不错的结果。我们相信HRNet将取代以分类网络为基础的网络架构,成为计算机视觉识别等应用的新标准结构。
-
如何在基于机器视觉的应用中单线传输高分辨率视频数据2022-10-28 757
-
如何在基于机器视觉的应用中通过单线传输高分辨率视频数据2021-09-07 2429
-
如何实现DCP的高分辨率控制?2021-04-27 2089
-
如何设计高速高分辨率ADC电路?2021-04-23 2822
-
京东方的高分辨率QLED实现了500ppi分辨率2020-07-17 1727
-
高分辨率阵列感应测井仪的特点以及工作原理2020-06-15 3835
-
康耐视两款高分辨率Checker视觉传感器2018-11-14 2314
-
增强高分辨率图像捕获的选择2018-10-25 1777
-
超分辨率神经网络原理2018-07-12 8334
-
从AlexNet到MobileNet,带你入门深度神经网络2018-05-08 2846
-
中国深圳先进院在高分辨率超声成像领域取得重要进展2018-03-25 12280
-
【AD新闻】中国深圳先进院在高分辨率超声成像领域取得重要进展2018-03-23 4126
-
高分辨率遥感图像飞机目标检测2018-03-06 1488
-
深度反卷积神经网络的图像超分辨率算法2017-12-15 1354
全部0条评论

快来发表一下你的评论吧 !
