

如何选择Embedded Linux的图形框架
描述
对于Android开发者来说,基本不用关心图形方案这些细节,你只要调用java的class,最后的性能都是有原厂和谷歌验证过的。 但对Linux开发者来说,情况要复杂的多,没有一个完美方案。。所以当你决定要在Linux要开发应用的时候,一定要明确你的需求,对比方案间的优劣。
小框图:
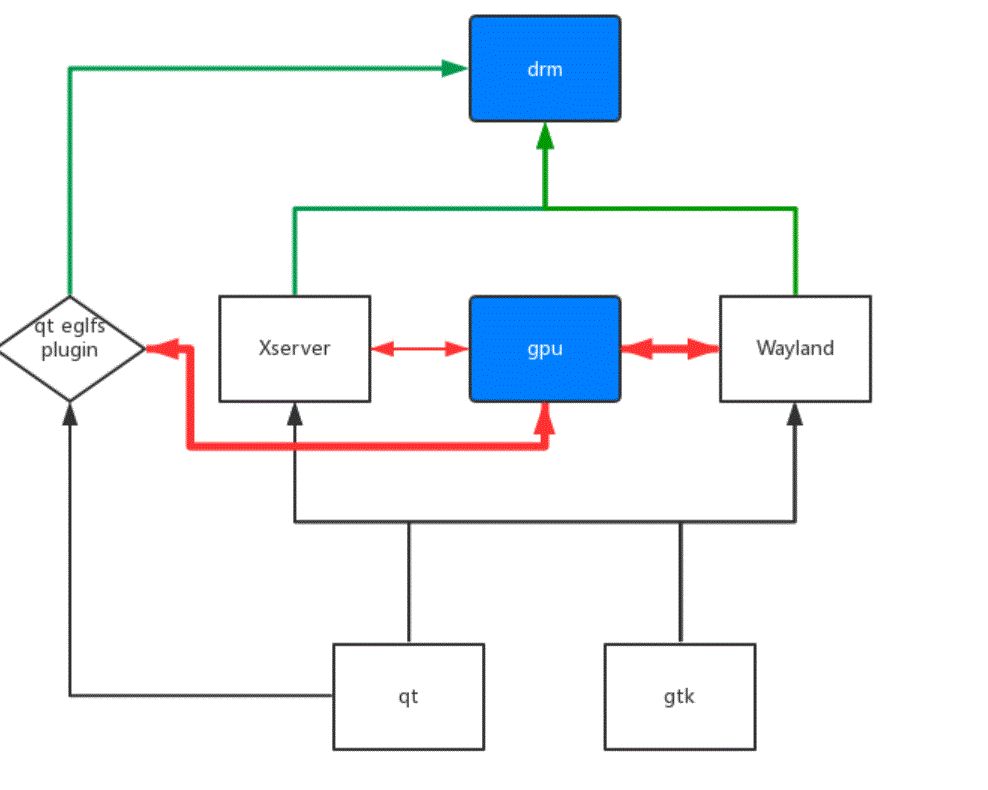
X11
X11的基础构架,建议先谷歌一下,太庞大,历史遗留比较多,到现在我也没弄清楚一些调用流程。下面主要讲讲dri2。dri2是xserver用来连接gpu的结构,下面这个链接里蛮详细的。大概理解,dri2自己管理一个window下面的buffers, xserver都不会过问,只有swap front buffer的时候,才会调一些函数来wait page flip来进行画面的同步。
不过这个front buffer是false的,要注意,最后显示还要进行compoiste(以rk的xserver为例,这里会用到cpu blit, 而wayland和qt eglfs这步是gpu做的)。dri2全屏和不全屏的性能差距会比较大,因为全屏的情况下,dri2出来的flase front buffer,也就是这个window的drawbuffer, 是直接被作为全局的font buffer,送到ddx显示的,省去了compoiste。
所以在x11下开发3d应用的时候,一定要全屏,保证没有多余的compoiste,比如qt的qmlwindow就是一个完整的gl窗口(注:debian上不是)。另外一提,rk平台上的xserver,还支持了glamor,意味一些compoiste可以被gpu加速到,如果是做多窗口的应用或者desktop类型的产品,这个featrue还是非常有用的,能运行x11上的所有软件,又有gpu加速合成。
2017.3.10
做了些实验,x11下egl的lag,在拉高cpu频率之后,显著的缓解,所以应该就是cpu参与了合成步骤,导致效率变低。
2017.5.21
在debian看到一些比较慢的现象,要注意不是x11的问题,而是debian的程序编译选项一般没带上gles。
QT EGLFS
QT EGLFS是qt自己实现的一个gui系统,不支持多窗口,但也因此少了window compoiste。 QT EGLFS和dri2的方式也差不多,区别就在于,qt eglfs的font buffer在自己用gpu compoiste后,是直接送给drm去显示,而X里是送Window manager去做compoiste,所以EGLFS在效率上是有优势的。另外除了QT,常用的UI库里,SDL也是支持这种DRM+GL的方式的。
2017.3.11
QT EGLFS的流程其实可以通过代码追踪一下。根据代码,一个qmlvideo的显示过程会是这样的(非qml的话不一样,会优先用xvimagesink的subwindow),surface路径会是QDeclarativeVideoOutput->QDeclarativeVideoRendererBackend,显示一帧frame的话,会先调用到QDeclarativeVideoRendererBackend::updatePaintNode,然后就是返回一个NV12 to RGB的shader,走正常qtquick程序的显示显示 ,最后QOpenGLCompositor会合成所有的window。Qt EGLFS的流程还是很清晰的,就是先window自己render(qquickwindow是用的GPU)一个buffer, 然后QOpenGLCompositor把所有的window再render到一个buffer上,然后这个buffer送drm显示(如果就是一个primary window,就直接送drm了)。
Wayland
wayland是Linux上下一代的display server,从结构上来讲,也最相近android上的HWC,全部的compoiste都是gpu来做的,不会有xserver那样cpu合成的场景。wayland除了gpu合成以外,另一个优势,就是overlay接口的存在,能允许移动平台上的一些2d加速模块,display模块在这个接口上被调用(这些模块才是移动平台能跑大分辨率ui的关键)。wayland主要的问题是兼容性,比如你用qtmultimedia的话,会发现video sink不能换,因为不兼容wayland的窗口api。
应用场景
3d应用
3d应用的瓶颈最主要在计算单元上,拷贝,compoiste一类的开销,根据具体场景再考虑。建议直接raw的drm api或者qt eglfs。
视频播放
对视频播放来说,拷贝,compoiste的开销是决定性的。Spec上的视频播放极限,比如rk3399,rk3288播放4k,rk3036播放1080p,基本上是不可能在通用框架,也就是走gpu实现的。 因为达到了芯片bandwidth的上限场景,如果让gpu去拷贝和转格式的话速度会很慢,必须要display的部分自己去处理显示视频数据。
但想让display部分去处理的话,软件上必须有对应的支持——-然而desktop based的gui framework大多缺失了这样一个东西。之前在rk的系统上,我base X11做了一个“gstreamer sink” 。通过x的api获取窗口的位置,然后直接drm的api,绕过X系统,overlay画在窗口的位置。
这样做确实可以发挥视频播放的极限,主要的问题就是没办法和gui系统融合,没办法叠加控件,如果使用的场景都是fullscreen,可以试试这做。上文提了下wayland框架支持overlay,所以最理想的,还是wayland通过overlay的机制直接call的display单元显示,像android那样。
总结一下,所以如果视频性能不是那么高,又需要复杂UI,建议用gpu的框架。 qt eglfs,放视频,按rk3288的性能,可以达到1080p 60fps。x11,gles在rk平台的软件上,测试下来,性能比较差;不过已经有rkximagesink的overlay显示方案。wayland暂时没有研究,理论上原生支持overlay的wayland是最好的,但是我觉得应该也就类似rkximageisnk的那种效果,不能和正常的窗口兼容。
Tips
libmali
libmali是mali gpu的userspace library,我也看不到代码,完全是黑盒,只能说根据一些类似的代码和文档猜测他的实现方式。libmali有很多编译选项,我猜的话,除了软件硬件版本,还有下面两种。一个是fbdev和gbm,分别对应了fbdev和drm两种内核驱动的场景。fbdev对比gbm有几个差异。
1.vblank 用fbdev去跑on-screen的glmark,分数一般是要比gbm的高,原因就是这套流程没有去等待vblank。gbm的实现都会在最后swap front buffer的时候等待vblank,所以on-screen只能跑几十fps,fbdev的不会去等,因此fbdev的libmali on-screen的fps和off-screen的差不多。
2.zero-copy所谓zero-copy就是不拷贝texture。一段在内存里的texture,要让gpu去使用,必须先用cpu把数据从这段内存拷到gpu能用的buf(dma-buf)里。如果这个texture数据本来就在一个dma-buf里的话,可以通过特定的api直接让gpu load,从而避免拷贝。dma-buf在gbm上的实现,搜索EGL_LINUX_DMA_BUF_EXT就可以。在fbdev上的实现,比较麻烦,“fbdev zero-copy” 。还有就是display server的选项,比如xserver,比如wayland。 这个就是支持在display server下运行,没什么好说的。
libdrm
drm的api分legacy api和新一点的atomic api,如果你直接用drm api开发程序,一定要注意这两个api的区别。legacy api:drmModeSetCrtc, drmModeSetPlane, drmModePageFlip都是legacy的api,这些函数什么意思,怎么用,可以搜索下网络资料。
大致上,drmModeSetCrtc包括了drmModeSetPlane包括了drmModePageFlip。在rk平台上,drmModeSetCrtc和drmModeSetPlane都是atomic的,意味着你调用这些api后会一直block到vblank,drmModePageFlip是noneblock的,你调用后就会返回。
一般来说不在一个程序里顺序调用会block的api,性能不会有太大问题。atomic api:legacy的api都是atomic的,而且容易重复调用,这就导致有些场景会很没效率。比如wayland drm的场景下,有3个plane,每个周期内要更新这几个plane,如果全用drmModeSetPlane的话,就意味着要等待3次vblank,那么一个60hz的屏幕,你的fps最高只会有20fps。
为了解决这种情况,我们就需要有一个api,能在一次调用里,解决掉所有的事情,比如更新所有的plane,然后只用等一次vblank。 drmModeAtomicCommit,具体用法请谷歌。
-
一文读懂Linux各模块框架2018-06-30 8521
-
Linux内核开发框架学习资料汇总2021-06-17 832
-
嵌入式Linux图形系统(GUI)快速参考手册2011-02-14 0
-
Embedded SIG | 多 OS 混合部署框架2022-06-29 0
-
基于Qt/Embedded的嵌入式控制界面开发2009-08-12 587
-
基于QT/Embedded的可变情报板应用程序开发2010-03-03 774
-
Mentor Graphics新扩展Mentor Embedded Linux功能2015-11-06 1139
-
Qt/Embedded开发入门2017-10-18 1830
-
采用Linux还是Windows Embedded,研华选择后者2017-12-04 348
-
Linux DMA Engine框架的介绍2018-11-23 6252
-
你对Linux总线设备驱动框架是否了解2019-05-05 723
-
当前HarmonyOS轻设备图形框架的总体特性介绍2021-07-28 1638
-
基于STM32移植UCGUI图形界面框架(3.9.0源码版本)2021-11-30 868
-
ThunderGP:基于HLS的FPGA图形处理框架2022-10-27 427
全部0条评论

快来发表一下你的评论吧 !
