

Linux调度器中的PELT(Per-Entity Load Tracking)
描述
一、为何需要per-entity load tracking?
对于Linux内核而言,做一款好的进程调度器是一项非常具有挑战性的任务,主要原因是在进行CPU资源分配的时候必须满足如下的需求:
1、它必须是公平的
2、快速响应
3、系统的throughput要高
4、功耗要小
其实你仔细分析上面的需求,这些目标其实是相互冲突的,但是用户在提需求的时候就是这么任性,他们期望所有的需求都满足,而且不管系统中的负荷情况如何。因此,纵观Linux内核调度器这些年的发展,各种调度器算法在内核中来来去去,这也就不足为奇了。当然,2007年,2.6.23版本引入“完全公平调度器”(CFS)之后,调度器相对变得稳定一些。最近一个最重大的变化是在3.8版中合并的Per-entity load tracking。
完美的调度算法需要一个能够预知未来的水晶球:只有当内核准确地推测出每个进程对系统的需求,她才能最佳地完成调度任务。不幸的是,硬件制造商推出各种性能强劲的处理器,但从来也不考虑预测进程负载的需求。
在没有硬件支持的情况下,调度器只能祭出通用的预测大法:用“过去”预测“未来”,也就是说调度器是基于过去的调度信息来预测未来该进程对CPU的需求。而在这些调度信息中,每一个进程过去的“性能”信息是核心要考虑的因素。但有趣的是,虽然内核密切跟踪每个进程实际运行的时间,但它并不清楚每个进程对系统负载的贡献程度。
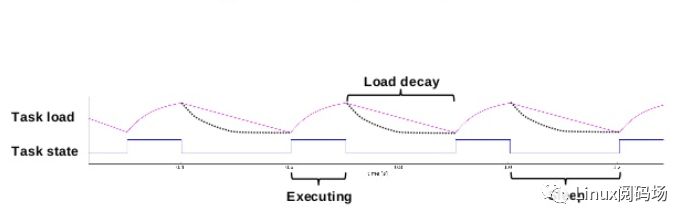
有人可能会问:“消耗的CPU时间”和“负载(load)”是否有区别?是的,当然有区别,Paul Turner在提交per-entity load tracking补丁集的时候对这个问题做了回答。一个进程即便当前没有在cpu上运行,例如:该进程仅仅是挂入runqueue等待执行,它也能够对cpu 负载作出贡献。
“负载”是一个瞬时量,表示当前时间点的进程对系统产生的“压力”是怎样的?显然runqueue中有10个等待运行的进程对系统造成的“压力”要大于一个runqueue中只有1个等待进程的场景。与之相对的“CPU使用率(usage)”不一样,它不是瞬时量,而是一个累积量。有一个长时间运行的进程,它可能上周占用大量的处理器时间,但是现在可能占用很少的cpu时间,尽管它过去曾经“辉煌”过(占用大量CPU时间),但这对现在的系统负荷贡献很小。
3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。需要注意的是:CFS中的“运行队列”实际上是有多个,至少每个CPU就有一个runqueue。而且,当使用“按组调度”( group scheduling)功能时,每个控制组(control group)都有自己的per-CPU运行队列。
对于per-rq的负载跟踪方法,调度器可以了解到每个运行队列对整个系统负载的贡献。这样的统计信息足以帮助组调度器(group scheduler)在控制组之间分配CPU时间,但从整个系统的角度看,我们并不知道当前负载来自何处。除此之外,per-rq的负载跟踪方法还有另外一个问题,即使在工作负载相对稳定的情况下,跟踪到的运行队列的负载值也会变化很大。
二、如何进行per-entity load tracking?
Per-entity load tracking系统解决了这些问题,这是通过把负载跟踪从per rq推进到per-entity的层次。所谓调度实体(scheduling entity)其实就是一个进程或者control group中的一组进程。为了做到Per-entity的负载跟踪,时间(物理时间,不是虚拟时间)被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。如果在该周期内,runnable的时间是x,那么对系统负载的贡献就是(x/1024)。
当然,一个实体在一个计算周期内的负载可能会超过1024us,这是因为我们会累积在过去周期中的负载,当然,对于过去的负载我们在计算的时候需要乘一个衰减因子。如果我们让Li表示在周期pi中该调度实体的对系统负载贡献,那么一个调度实体对系统负荷的总贡献可以表示为:
L = L0 + L1*y + L2*y2 + L3*y3 + ...
其中y是衰减因子。通过上面的公式可以看出:
(1) 调度实体对系统负荷的贡献值是一个序列之和组成
(2) 最近的负荷值拥有最大的权重
(3) 过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的负荷贡献,只要把上次的总负荷的贡献值乘以y再加上新的L0负荷值就OK了。
在3.8版本的代码中,y已经确定:y ^32等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个周期(1024us)后,对当前时间的的符合贡献值会衰减一半。
一旦我们有了计算runnable调度实体负荷贡献值的方法,那么这个负荷值可以向上传递,通过累加control group中的每一个调度实体负荷值可以得到该control group对应的调度实体的负荷值。这样的算法不断的向上推进,可以得到整个系统的负荷。
当然,计算负荷不是那么简单。因为调度器本身就会定期的观察记录调度实体的信息,计算runnable调度实体的负荷贡献是容易的。但没有处于runnable状态的调度实体就对系统负荷没有贡献了吗?当“密码破解”进程由于page fault而阻塞,它其实仍然会给 “系统列车”增加“负荷”。因此我们需要有一种计算进入阻塞状态的进程对系统负载贡献的方法,当前不是调度器需要关注的。
当然,内核可以选择记录所有进入阻塞状态的进程,像往常一样衰减它们的负载贡献,并将其增加到总负载中。但这么做是非常耗费资源的。所以,相反,3.8版本的调度器在每个cfs_rq(每个control group都有自己的cfs rq)数据结构中,维护一个“blocked load”的成员,这个成员记录了所有阻塞状态进程对系统负荷的贡献。
当一个进程阻塞了,它的负载会从总的运行负载值(runnable load)中减去并添加到总的阻塞负载值(blocked load)中。该负载可以以相同的方式衰减(即每个周期乘以y)。当阻塞的进程再次转换成运行态时,其负载值(适当进行衰减)则转移到运行负荷上来。因此,跟踪blocked load只是需要在进程状态转换过程中有一点计算量,调度器并不需要由于跟踪阻塞负载而遍历一个进入阻塞状态进程的链表。
另外一个比较繁琐的地方是对节流进程(throttled processes)负载的计算。所谓节流进程是指那些在“CFS带宽控制器”( CFS bandwidth controller)下控制运行的进程。当这些进程用完了本周期内的CPU时间,即使它们仍然在运行状态,即使CPU空闲,调度器并不会把CPU资源分配给它们。
因此节流进程不会对系统造成负荷。正因为如此,当进程处于被节流状态的时候,它们对系统负荷的贡献值不应该按照runnable进程计算。在等待下一个周期到来之前,throttled processes不能获取cpu资源,因此它们的负荷贡献值会衰减。
三、per-entity load tracking有什么好处?
有了Per-entity负载跟踪机制,在没有增加调度器开销的情况下,调度器现在对每个进程和“调度进程组”对系统负载的贡献有了更清晰的认识。有了更精细的统计数据(指per entity负载值)通常是好的,但人们可能会怀疑这些信息是否真的对调度器有用。
我们可以通过跟踪的per entity负载值做一些有用的事情。最明显的使用场景可能是用于负载均衡:即把runnable进程平均分配到系统的CPU上,使每个CPU承载大致相同的负载。如果内核知道每个进程对系统负载有多大贡献,它可以很容易地计算迁移到另一个CPU的效果。这样进程迁移的结果应该更准确,从而使得负载平衡不易出错。目前已经有一些补丁利用per entity负载跟踪来改进调度器的负载均衡,相信这些补丁会在不久的将来进入到内核主线。
small-task packing patch的目标是将“小”进程收集到系统中的部分CPU上,从而允许系统中的其他处理器进入低功耗模式。在这种情况下,显然我们需要一种方法来计算得出哪些进程是“小”的进程。利用per-entity load tracking,内核可以轻松的进行识别。
内核中的其他子系统也可以使用per entity负载值做一些“文章”。CPU频率调节器(CPU frequency governor)和功率调节器(CPU power governor)可以利用per entity负载值来猜测在不久的将来,系统需要提供多少的CPU计算能力。
既然有了per-entity load tracking这样的基础设施,我们期待看到开发人员可以使用per-entity负载信息来优化系统的行为。虽然per-entity load tracking仍然不是一个能够预测未来的水晶球,但至少我们对当前的系统中的进程对CPU资源的需求有了更好的理解。
-
Linux的Deadline实时调度算法2024-01-24 2033
-
深入探讨Linux的进程调度器2024-08-13 1934
-
Linux2.4与Linux2.6内核调度器的比较研究2008-06-17 6185
-
Linux系统调度是实现特性的关键部分2019-07-05 1987
-
Linux2.4和Linux2.6的调度器对比分析,Linux2.6对调度器的改进有哪些方面?2021-04-27 1271
-
嵌入式工程师必会的 Linux 进程调度所有知识点2021-08-01 2961
-
Linux与VxWorks任务调度机制分析2009-03-28 954
-
linux处理机调度与死锁2009-04-28 684
-
Linux 2.6进程调度2009-06-13 571
-
uClinux进程调度器的实现分析2017-11-06 983
-
Linux内核的DL调度器的细节和怎么样使用DL调度器?2018-07-16 6559
-
如何更改 Linux 的 I/O 调度器2019-05-15 1275
-
英创信息技术Linux系统调度简介2020-02-05 1991
-
Linux进程调度时机概念分析2020-01-23 3624
-
带大家看看Linux内核如何调度进程的2021-07-26 2798
全部0条评论

快来发表一下你的评论吧 !
