

如何使用深度学习对电池片的缺陷进行识别详细研究资料说明
电子说
描述
基于TensorFlow框架搭建卷积神经网络对电池片电致发光图像进行缺陷识别。选取公开的数据集,其中包含了电池片的不同种类缺陷。在传统的VGGNet网络的基础上使用全卷积神经网络进行训练,并分析不同损失函数和dropout概率在数据集上的训练效果。经过实验证明,该算法实现了对电池片是否有缺陷的准确识别。研究还得出压缩网络结构对算法训练速率能有大幅提升,这使得简化的模型更具有可迁移性,为大范围的实时缺陷识别提供了一种有效方案。
0 引言
以太阳能为代表的新能源在近些年得到了广泛的研究和应用,特别是光伏发电技术。光伏太阳能的核心组件是光伏电池组件,除了电池材料自身存在的缺陷,生产时对电池片的多次加工也可能导致电池片的损坏,如过焊片、黑斑片、隐裂片等缺陷问题,加上安装和使用过程中的机械损伤,都会影响组件的转化效率和使用寿命。在实际应用中,更会对光伏发电系统自身的安全构成威胁。因此,研究光伏组件的缺陷检测显得尤为重要。
目前电池组件缺陷检测的技术主要有[1]:红外成像技术、光致发光成像技术、电致发光(ELectrofluorescence,EL)成像。EL成像是用于光伏组件缺陷检测的非接触式成像技术,根据硅材料的电致发光原理进行检测。给晶体硅电池组件加上正向偏压,组件会发出一定波长的光,电荷耦合器件图像传感器(CCD)可以捕捉到这个波长范围的光并在电脑上成像。但电池组件存在缺陷会减弱其发光强度,所以可以根据EL图像中电池发光强度的不同来判断电池组件是否存在缺陷。
在以往的研究中,2012年TSIA D M等[2]提出了利用独立分量分析(ICA)基图像识别缺陷的监督学习方法,该方法在80个太阳电池单元的测试样本上平均识别率为93.4%。2014年ANWAR S A和ABDULLAH M Z提出了检测多晶电池微裂纹的算法[3],即基于各向异性扩散和形状分类的图像分割方法,在600张图像上检测微裂纹的精度上达到88%。深度学习特别是卷积神经网络(Convolutional Neural Network,CNN)在图像识别[4]和检测上备受重视。2018年DEITSCH S等提出自动检测单一光伏电池EL图像缺陷的方法[5],分别用支持向量机和卷积神经网络进行训练及预测,平均准确率分别达到了82.44%和88.42%。另外,随着深度学习的网络结构趋于更深,增加了训练及实际应用的时间,因此,对网络模型的压缩的研究显得尤为重要[6]。
本文针对传统缺陷识别算法的不足,通过深度学习算法对EL图像进行分类,进而识别出有缺陷和没有缺陷的电池片。经过实验证明,改进的VGG16[7]网络具有很好的准确率,并且大幅降低了神经网络由于层数过多而带来的大量运算,缩减后的模型有更大的实用性。
1 实验数据及预处理
实验数据来自于BUERHOP-LUTZ C等人公开的数据集[8],该数据集提供了从光伏组件的高分辨率电致发光图像中提取的太阳能电池图像。图片来自于44个不同的PV模块,其中18个模块为单晶型,26个为多晶型。图片可以拆分为2 624个300×300像素的电池单元的EL图像。这些图像包含了常见的内外缺陷,如黑心片、黑斑片、短路黑片、过焊片、断栅片、明暗片、隐裂等类型,如图1所示,出现的这些缺陷会对太阳电池组件的转换效率和使用寿命造成严重影响。

原数据集中将单晶和多晶的电池单元进行注释,并且按照缺陷的概率对每张图片进行标注,统计样本的总数以及各类样本分立情况,发现各类样本数目相差较大,样本分布的不平衡将导致训练后模型对各类别识别出现偏差。为了减少分布不平衡的差异,本文首先将概率为0%和33.33%的图片作为无缺陷的正样本,66.67%和100%的图片作为有缺陷的负样本,因此得到的样本分布如图2所示。

本文所使用的神经网络模型需要224 pixel×224 pixel大小的输入图像,由于给定数据集EL图像大小都是300 pixel×300 pixel,在输入前需要对通过压缩来得到符合大小的图片。对于样本分布不平衡问题,本文使用了数据增强方法。采用的第一种数据增强方法是随机水平和垂直翻转图像;第二种方法是对原始图像随机旋转一定角度(不超过2°),旋转所使用的插值方法为双三次插值;第三种方法是调整图像的亮度和对比度,因为光照强度的变化会对成像结果造成很大影响。在预处理阶段还对输入图片进行了去噪处理。
2 基于VGGNet的缺陷识别分类网络
神经网络在20世纪就已经被发现,经过十多年的发展,研究人员提出了各种不同的网络结构,从AlexNet到VGGNet、GoogLeNet和ResNet,随着网络深度和宽度的增加以及不同功能层的引入,其在图像识别的准确率不断提高。一方面,当增加网络层数后,网络可以进行更加复杂的特征提取,理论上可以取得更好的结果。但随着网络深度的增加,会出现退化的问题,由于深层网络存在着梯度消失或者爆炸的问题,深度学习模型很难训练。因此,设计一个实用的EL图像缺陷识别分类网络,需要结合理论分析和实验验证。
卷积神经网络作为一种特殊的深层的神经网络模型,它的核心思想是将局部感知、权值共享以及下采样结合起来,通过深度神经网络的逐层计算来学习图像的像素特征、低级特征、高级特征直至类别的隐式表达关系。2014年SIMONYAN K等人提出VGG网络,探索了CNN的深度与其性能之间的关系,成功地构筑了16~19层深的神经网络,输入为224×224×3的图片,经过卷积和池化的处理输出图像所属类别的概率[7],在具有1 000多个类别一百多万张图片的ImageNet数据集上取得了当时很好的效果。因此不少分类问题采用的卷积神经网络都以此为基础。
原始的VGG16网络结构如图3所示,由5组卷积层、3层全连接层、softmax输出层构成,每组卷积层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数做非线性变换,用以加快网络收敛。图中,3×3 conv,64等表示卷积核尺寸为3×3,通道数为64的卷积层;pool/2表示滑动步长为2的池化层(这里为最大池化);fc 4096表示通道数为4096的全连接层;softmax表示softmax函数。对于每一组卷积操作,都包含多个特别小的3×3卷积核构成的卷积层,采用小卷积核既可以减少参数,又增加了非线性映射,从而增强网络的拟合效果。滑动步长为1,采用边界填充的方式,使得每个卷积层的输入/输出特征图的像素不变。池化层采用2×2的池化核。每一组的通道数从64开始扩大2倍,分别为64、128、256、512、512,使得更多的信息可以被提取出来。之后的3个全连接层通道数分别为4 096、4 096、1 000,最后通过softmax层得到图片属于每个类别的概率。在以下研究中,将最后的3层全连接层替换为卷积核为7×7和1×1的卷积层,通道数分别为4 096、4 096和2。

3 实验及其分析
3.1 网络训练方法
实验所用计算机内存为8 GB,使用英伟达GTX 1060显卡加速模型训练,显存为6 GB。软件环境为Ubuntu 16.04 LTS 64位系统,选用Python作为编程语言,采用TensorFlow深度学习开源框架,CUDA版本为9.0。
实验选取图片总数的80%进行训练,20%用来测试,即训练集图片数量为2 099,测试集数量为525。采用批量训练的方法,将训练集和测试集分成多个批次(batch),每个批次的大小为16或32,在对每一个batch训练完之后,对所有的测试集图片进行测试,迭代的次数记为steps。采用随机梯度下降算法作为优化器,学习率在训练中控制着参数的更新速度,这里使用指数衰减学习率,初始学习率为0.005,衰减速度为1 000,学习率衰减系数为0.9。训练得到的损失和准确率如图4所示。
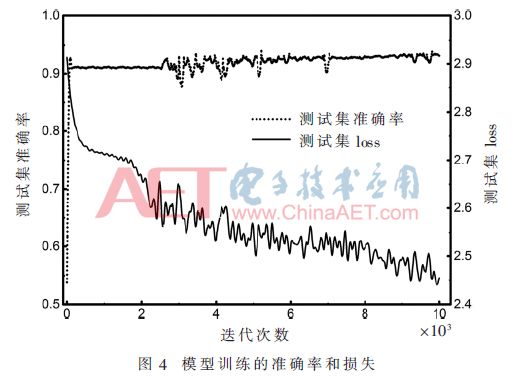
通过大量实验,发现CNN在缺陷识别上有不错的效果,为了进一步提高分类的性能及减少训练所需的时间,下面将对不同的dropout概率和损失函数进行讨论,以期望得到更优的模型。
3.2 不同损失函数下的识别准确率
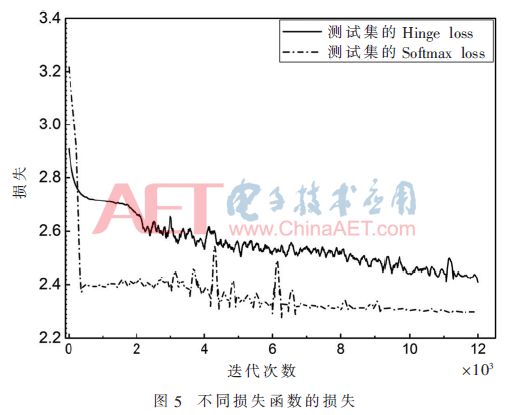
损失函数用来估量模型的预测值与真实值的相差程度,这里比较了两种常见的损失函数Hinge loss和Softmax loss。Hinge loss又称为折页损失函数,其函数表达式为:

其中,L为损失,t=[t1,t2,…,tN]T表示目标值;y=[y1,y2,…,yN]T,表示预测值输出;1≤j≤N,N为输出节点的数量。
这两种损失函数随着迭代次数变化的曲线如图5所示。在训练的初始阶段,Softmax loss要小于Hinge loss,但其下降的速度比较缓慢;训练200次以后Hinge loss迅速减小,说明模型收敛得更快,并且模型的鲁棒性更好。从这里可以看出,在电致发光图像缺陷识别的数据集上,二分类的Hinge loss具有更好的效果。
3.3 不同Dropout概率下的识别准确率
在数据集有限的情况下,通常使用dropout来缓解过拟合的发生,在一定程度上起到正则化的效果。它是指在标准的BP神经网络基础之上,使BP网络的隐藏层激活值以一定的比例变为0,即按照一定的比例,随机地让一部分隐藏层节点失效。存在dropout的神经网络计算过程如下:

图6给出了在不同dropout概率时对缺陷识别的准确率,从图中可以看出,当dropout概率在0.3时准确率最高。在训练的过程中,概率越小,网络的参数较多,对于训练集样本不足够大情况下,容易出现过拟合的现象;概率越小,由于所训练的神经网络节点数不足,并不能有效地拟合训练数据,导致最终的识别准确率下降,所以找到合适的概率对于模型的训练效果至关重要。

3.4 不同网络结构的识别效果分析
基于VGG16的卷积神经网络虽然在现有数据集上取得了良好的限制,但训练时间过长,通过对dropout概率的研究也表明网络中存在着冗余参数,因此为了提高训练的速度,本文对网络进行缩减,计算不同网络层数时的参数总量,记录下训练时的时间以及在测试集上的准确率,如表1所示。
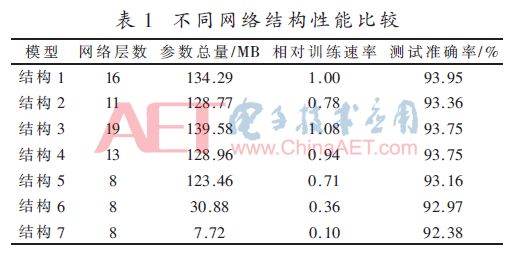
表1中,结构1为完整的VGG16网络;结构2将每组卷积的卷积层个数减少为1、1、2、2、2,通道数不变;结构3将每组卷积的卷积层个数改为2、2、4、4、4,通道数不变,用来作对比;结构4将每组卷积的卷积层个数改为2、2、2、2、2,通道数不变;结构5~6每组卷积的个数均为1,结构4的通道数为64、128、256、512、512、4096、4096、2,结构5的通道数为32、64、128、256、256、2048、2048、2,结构6的通道数为16、32、64、128、128、1024、1024、2。
从表1中可以看出网络的参数主要集中在全连接层,在将全连接层的神经元节点数目缩减之后,训练的时间大大缩减。卷积操作承担着图像特征提取的任务,卷积层数量的缩减虽然会稍微降低识别的结果,但是能大大加速模型的训练速度,这对于工业上的电致发光图像缺陷识别有重要意义。
4 结论
本文提出将卷积神经网络用于太阳电池单元电致发光图像缺陷识别,它能够很好地提取电池片的缺陷,进行正确的分类。在2 624张样本上,用全卷积VGG16网络进行训练,经过大量的参数调节,识别的准确率达到93.95%。在此基础上本文研究了模型压缩后的训练速率以及识别准确率,得出在减少网络层数之后,模型的训练速率大大加快,并且不会使准确率明显下降。下一步的研究中,将在简化网络结构的基础上,提高模型性能和识别准确率,以便用于实际的电池片缺陷识别当中。
-
电极片常见缺陷 电极片缺陷检测方法 电极片缺陷对电池性能的影响2023-11-10 3159
-
基于机器学习的应用系统指纹识别技术研究2023-11-03 2554
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2154
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 28291
-
labview深度学习检测药品两类缺陷2021-05-27 20951
-
传统锂离子电池充电方式研究资料下载2021-04-06 1303
-
labview深度学习应用于缺陷检测2020-08-16 2975
-
基于TensorFlow框架搭建卷积神经网络的电池片缺陷识别研究2019-08-28 8599
-
如何进行色环电阻识别详细方法说明2019-06-10 2225
-
利用ECS进行深度学习详细攻略2018-12-24 2116
-
基于DSP的指纹识别系统研究资料下载.pdf2018-05-07 1389
-
RCC电路间歇振荡的研究资料2016-05-09 836
-
光纤通信复用技术的研究资料2012-08-20 4901
-
支持向量机超声缺陷识别法的研究2009-07-11 816
全部0条评论

快来发表一下你的评论吧 !
